이전 글인 변수에서 지역 변수와 전역 변수에 대해서 설명했었다. 하지만 함수를 배우지 않았었고 전역 변수는 누가 오류냈는지를 찾기가 쉽지 않기 때문에 지역 변수를 많이 활용해야한다.
함수의 선언
- 함수의 선언이 되어있어야 다른 함수에서 사용할 수 있음
- 사용할 함수보다 위에서 ‘정의’해두면 상관 없지만 수많은 함수가 정의될 상황에서 사용할 함수가 항상 아래 있다는 보장이 없음으로 선언을 하는 것이 좋음
- 함수의 선언에서 모양만 맞추면 됨
- 함수의 정의부와 매개변수의 이름을 통일할 필요는 없음
- 선언부의 매개변수의 이름으로 함수의 기능을 유추할 수 있으므로 이름을 잘 설정하는 게 좋음
void PrintHelloWith(int number); // 함수의 선언
void PrintHelloWith(int number) // 함수의 정의
{
cout << "Hello " << number << endl;
}
int main()
{
PrintHelloWith(5); // 함수의 호출
}void Func1(); // 함수의 선언
void Func2();
void Func3();
void Func1() // 함수의 정의
{
cout << "Call Func1" << endl;
Func2(); // 함수의 호출
cout << "End Func1" << endl;
}
void Func2()
{
cout << "Call Func2" << endl;
Func3();
cout << "End Func2" << endl;
}
void Func3()
{
cout << "Call Func3" << endl;
cout << "Do Stuff in Func3" << endl;
cout << "End Func3" << endl;
}
int main()
{
Func1();
}
// 출력 결과
// Call Func1
// Call Func2
// Call Func3
// Do Stuff in Func3
// End Func3
// End Func2
// End Func1Func3가 가장 안쪽에서 호출된 함수고 이 함수의 모든 문장이 마친 후 종료되면 기존에 이 함수를 불렀던 Func2의 다음 문장으로 돌아간다. 다음 문장은 cout << “End Func2” << endl;로 이 문장까지 수행하면 Func2 또한 모든 문장을 수행했으므로 Func1로 돌아간다. 그리고 Func1의 마지막 문장을 수행하고 main 함수로 돌아간 후 프로그램은 종료된다.
함수의 오버로딩
같은 이름의 함수를 서로 다른 매개변수를 가진 여러 개의 함수를 만들 수 있는 기능
- 중복정의, 함수 이름의 재사용
- 코드의 가독성을 높여줌
- 함수의 반환 타입은 함수 오버로딩에서 고려되지 않음
- 오버로드된 함수를 호출하면 세 가지 중 하나가 발생
- 정확히 일치하는 함수가 있을 때 그 함수 호출
- 정확히 일치하는 함수가 없을 때, 자료형 승격, 표준 변환을 차례로 해보며 일치하는 함수 호출
- 모호한 일치(둘 이상의 함수와 정확히 일치하지 않을 때)인 경우 컴파일 오류
함수의 시그니처
컴파일러는 다음 3가지를 통해 함수를 구분한다.
- 함수명
- 매개변수의 개수
- 매개변수의 자료형
int add(int a, int b)
{
return a + b;
}
float add(float a, float b)
{
return a + b;
}
int main()
{
int x = add(1, 2);
float y = add(3.4f, 2.7f);
}x, y라는 각각의 변수를 만들고 동일한 이름을 갖고 있는 함수를 사용했지만 잘 작동한다. x는 int 형 변수로 int와 int 자료형이 매개변수인 add 함수가 호출되어 int 반환 값이 들어간 것이고, y는 float, float가 매개변수인 아래 오버로딩된 함수가 호출된 후 반환 값이 들어간 것이다.
함수의 디폴트 매개변수
기본값이 제공된 함수의 매개변수
- 사용자가 이 매개 변수의 값을 제공하지 않으면 기본값이 사용됨
- 매개변수의 값을 제공하면 사용자 제공 값이 기본값 대신 사용
void Print1(int a = 10)
{
cout << a << endl;
}
void Print2(int a = 1, int b = 2)
{
cout << a << ", " << b << endl;
}
void Print3(int a = -1, int b = -2, int c = -3)
{
cout << a << ", " << b << ", " << c << endl;
}
int main()
{
Print1();
Print1(0);
Print2(10);
Print2(10, 20);
Print3(3);
Print3(3, 4);
Print3(3, 4, 5);
}
// 출력 결과
// 10
// 0
// 10, 2
// 10, 20
// 3, -2, -3
// 3, 4, -3
// 3, 4, 5값에 의한 전달
Pass by value
- 함수로 값을 전달할 때 세 가지 경우가 있음
- 값에 의한 전달
- 참조에 의한 전달
- 주소에 의한 전달
- 나머지 두 개는 추후에 설명
이전의 글에서 함수의 매개변수도 함수가 호출될 때 스택 프레임에 생성되며, 함수가 종료될 때 매개변수 또한 같이 스택 영역에서 사라지는 것을 배웠다. 매개변수에 들어가는 값은 호출한 곳에서 넣은 인자의 같이 복사가 되는 것이고, 그 복사를 해준 원본의 값은 유지된다. 즉, 복사한 매개변수로 함수 내부에서 값을 변경한다하더라도 원본의 값은 유지된다.
void PassByValue(int x) // 메인 함수의 x 변수와 이 함수의 매개변수인 x는 다른 변수
{
x++; // 함수의 지역변수인 매개변수 x의 값을 1 증가시킴
}
int main()
{
int x = 10;
cout << "Before : " << x << endl;
PassByValue(x);
cout << "After : " << x << endl;
}
// 출력 결과
// Before : 10
// After : 10main 함수의 지역변수로 x를 만들고 10이라는 값을 넣어주었다. 그리고 PassByValue 함수의 매개변수 x에 인자 main 함수의 x의 값을 복사해주었다. PassByValue 함수의 매개변수 x는 ++ 증가 연산자를 만나 11로 바뀌게 되지만, 원본인 main 함수의 x 값은 10으로 유지된다. 그렇게 함수는 종료되고 cout으로 main 함수의 x 값을 출력해보아도 애초에 건들이지 않았으니 값 10이 출력된다.
호출 스택
Call stack
- 너무 많은 함수에서 호출되면 내가 현재 어디있는지를 잘 모름
- 디버거의 호출 스택을 사용하여 내가 현재 어떤 경로에 의해 왔는지를 확인할 수 있음
- 반환 주소랑 밀접한 관련이 있음
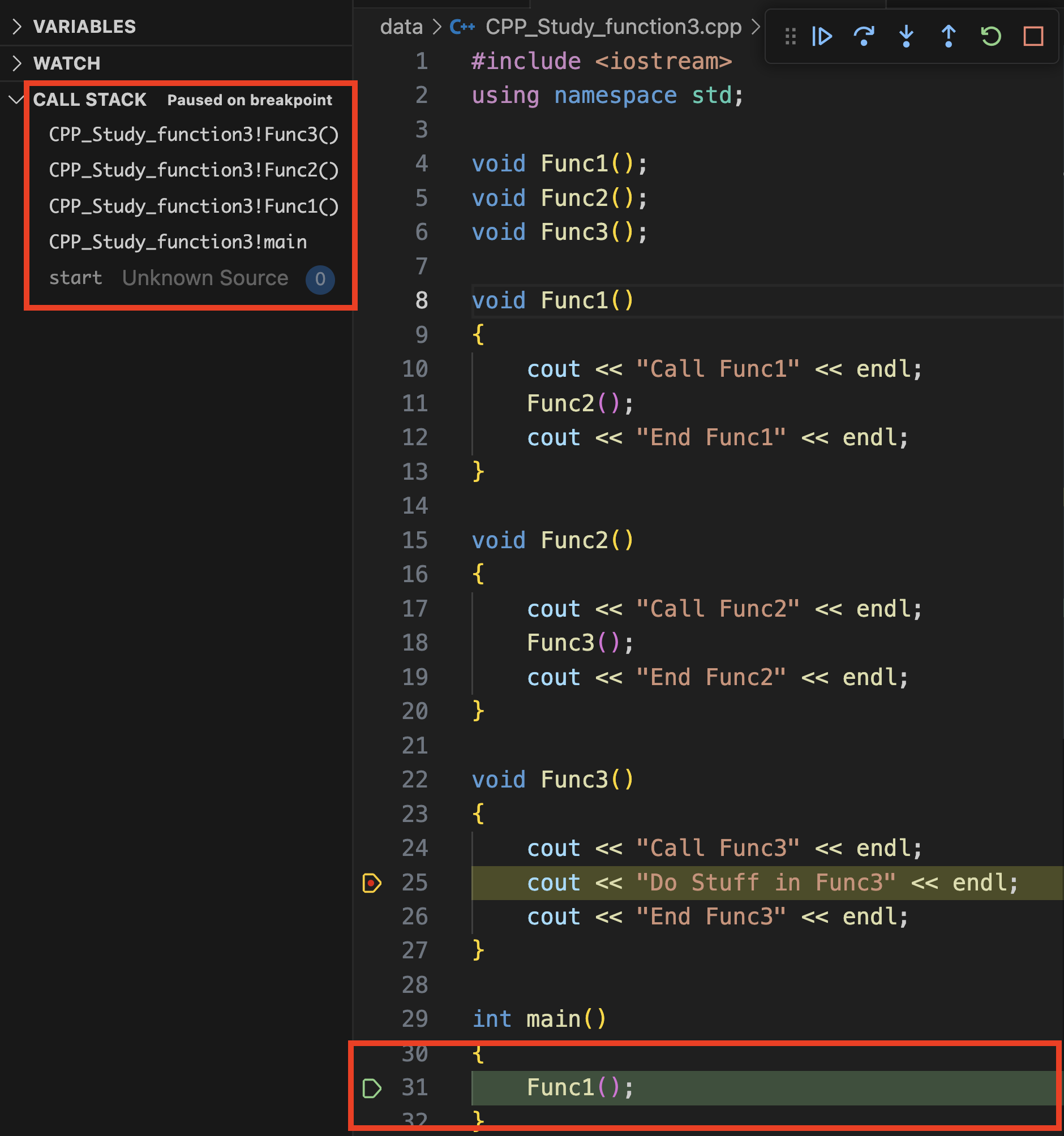
왼쪽 위의 콜 스택을 보면 맨 아래서부터 차곡차곡 스택 프레임이 쌓아 올려진 것을 볼 수 있다. 현재 중단점은 Func3의 내부에 있기 때문에 main 함수부터 시작하여 Func1, Func2, Func3이 차례대로 올려져있다.
스택오버플로우
지정한 스택 메모리 사이즈보다 더 많은 스택 메모리를 사용하게 되어 오류가 발생하는 상황
스택오버플로우는 이전 글에서 배웠던 슽택 프레임이 너무 많아져서 발생할 수 있다. 종료되지 않은 엄청나게 많은 함수의 스택 프레임이 스택 영역에 쌓여있다는 것이다. 스택오버플로우를 재현하기 위해서는 재귀함수가 가장 무난하게 쓰인다.
재귀함수
함수의 내부에서 자기 자신을 다시 부르는 함수
- 일부로 버그를 내는게 아닌 이상, 반드시 탈출하는 조건을 정의할 것
void foo()
{
foo(); // 자기 자신을 호출하고 있음
}
int main()
{
foo();
}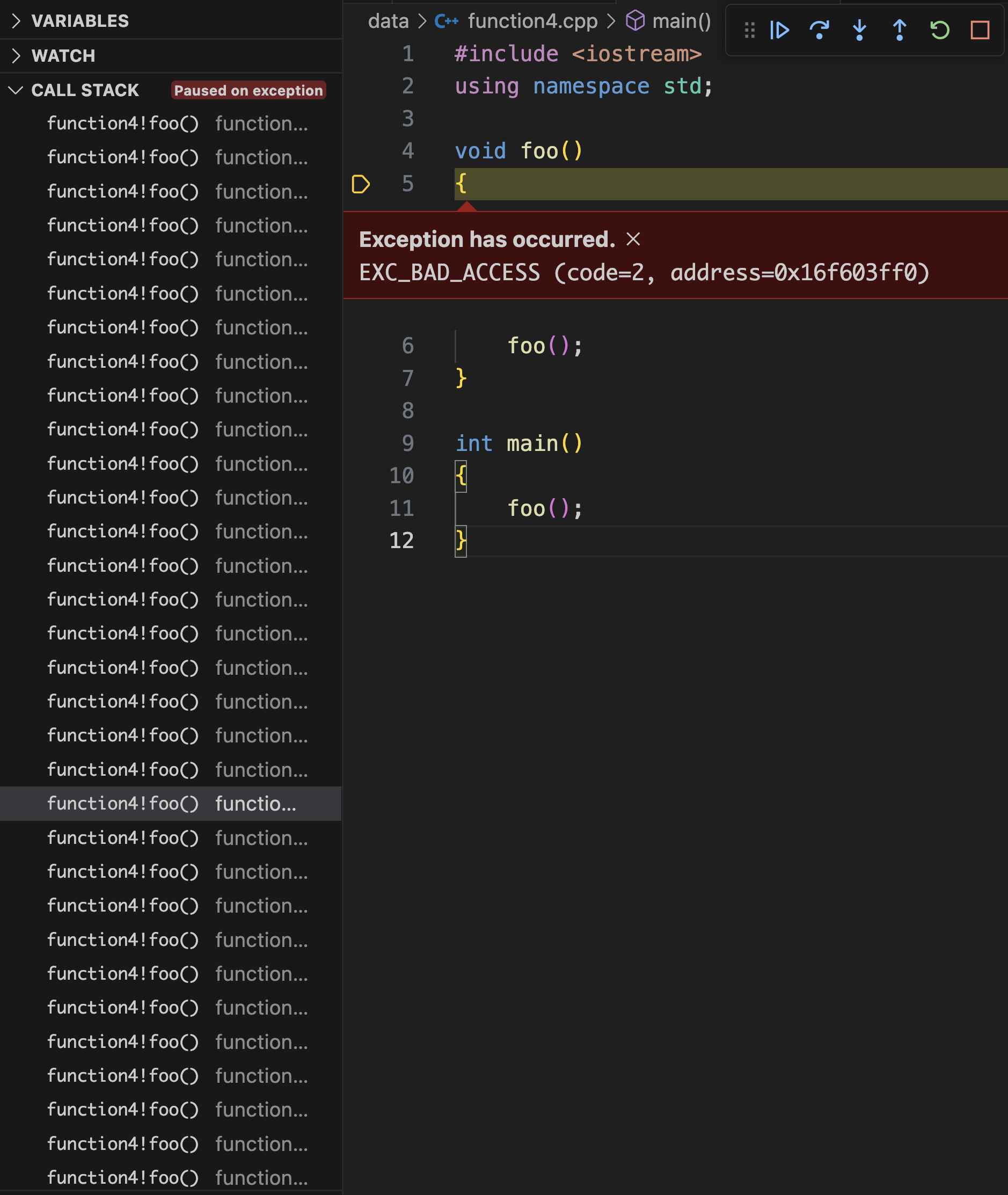
function4는 cpp 파일 이름이다.
콜스택을 보면 수많은 foo 함수가 불린 것을 볼 수 있다.
참고한 글
