Seq2Seq
Seq2Seq 과정
seq2seq는 번역기에서 대표적으로 사용되는 모델입니다.
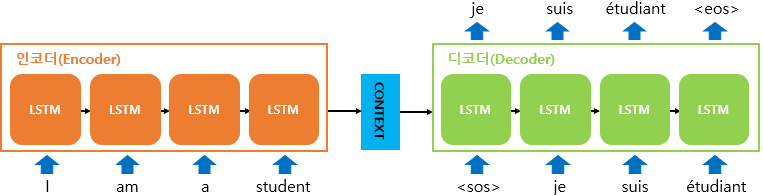
Seq2Seq 모델은 Encoder-Decoder 모델이라고도 합니다.이름에서 나왔듯이 2개의 모듈, Encoder, Decoder가 등장합니다.

인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만드는데, 이를 컨텍스트 벡터(context vector)라고 합니다.
입력 문장의 정보가 하나의 컨텍스트 벡터로 모두 압축되면 인코더는 컨텍스트 벡터를 디코더로 전송합니다. 디코더는 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력합니다.
Encoder에서는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환합니다. 위의 사진에서는 LSTM을 사용했지만, GRU나 단순한 vanilla RNN도 종종 사용합니다.
Encoder가 출력하는 벡터 h는 LSTM 계층의 마지막 은닉 상태입니다. h에 번역하기 위해 필요한 정보가 인코딩 됩니다. 여기서 h벡터는 고정길이 벡터입니다. context vector라고 불리기도 합니다.
결국 Encoding 한다는 것은 문장을 고정길이 벡터로 변환하는 작업이 됩니다.
디코더는 초기 입력으로 문장의 시작을 의미하는 심볼 가 들어갑니다. 디코더는 가 입력되면, 다음에 등장할 확률이 높은 단어를 예측합니다. 첫번째 시점(time step)의 디코더 RNN 셀은 다음에 등장할 단어로 je를 예측하였습니다.
첫번째 시점의 decoder RNN 셀은 예측된 단어를 다음 셀에 입력하고, 그리고 두번째 시점의 decoder RNN셀이 예측된 단어를 다음 셀에 입력하는 방식을 반복합니다.
Seq2Seq 단점
Seq2Seq에서 Encoder가 시계열 데이터를 인코딩합니다. 인코딩된 정보를 Decoder로 전달합니다. Encoder의 출력은 context vector이고 이는 고정길이벡터였습니다. 여기서 고정 길이라는 것은
입력 문장의 길이가 아무리 길어도, 항상 같은 길이의 벡터로 변환한다는 뜻입니다. 필요한 정보가 벡터에 담기지 못하게 되어서 loss가 생깁니다.
이를 Bottleneck Problem이라고 합니다.
또한 RNN의 고질적인 문제인 vanishing gradient 문제가 존재합니다.
이에 따라 Attention이라는 모델이 등장하게 됩니다.
Attention
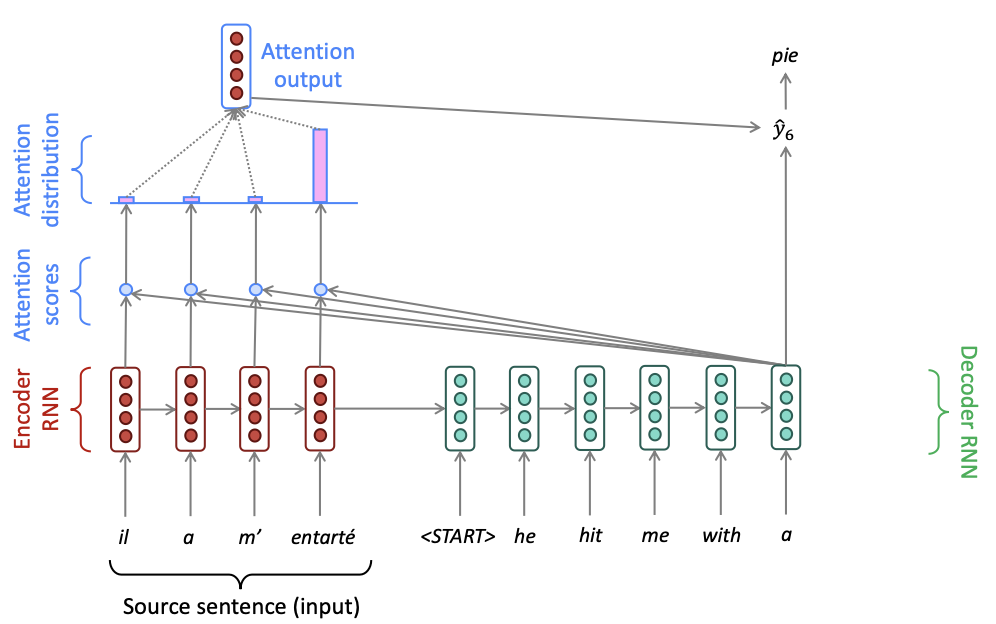
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점입니다. 왜 Attention이냐하면, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 더 집중(attention)해서 보게 됩니다.
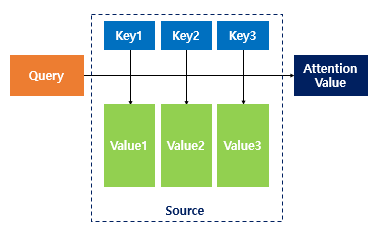
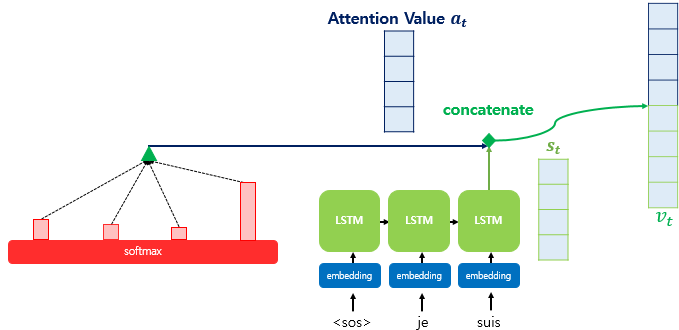
어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다.
그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다.
그리고 유사도가 반영된 '값(Value)'을 모두 더해서 리턴합니다. 여기서는 이를 어텐션 값(Attention Value)이라고 하겠습니다.
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
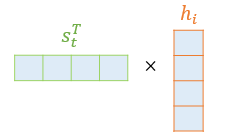
attention score= Key의 transpose값과 Query를 내적해서 scalar값으로 나옴
Attention scores
인코더의 time step이 1,2,3,..N이라고 할 때, 인코더의 hidden state를 이라고 하자. 디코더의 time step에서의 hidden state는 라고 하자.
어텐션에서는 출력 단어 예측에 다른 값을 필요로 하는데 이 것이 attention value입니다.
attention value를 구하기 위해서 attention score를 구합니다. score는 현재 디코더의 시점 t에서 단어를 예측하기 위해서, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 hidden state 와 얼마나 유사한지를 판단하는 값입니다.
여기서 이 스코어는 를 transpose하고 (hidden state)를 내적합니다. 결국 모든 attention score는 스칼라 값입니다.
Attention distribution
attention score에 softmax 함수를 씌워 attention distribution을 구한다.→ 이때 확률분포이기 때문에 합은 1입니다. 이 때, 각각의 값은 attention weight라고 합니다.
Attention value
어텐션의 최종 결과값을 얻기 위해서 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고, 최종적으로 모두 더합니다. 요약하면 가중합(Weighted Sum)을 진행합니다.
이라고 할 수 있습니다. 여기서 이 attention value는 context vector라고도 불립니다. 왜냐하면 인코더의 문맥을 포함하고 있기 때문에
마지막으로 attention value와 decoder의 hidden state인 를 연결(concatenate)합니다. 아래의 그림에서는 v로 표현이 되어있는데요. 이 v를 y값 (즉 번역에서 예측해야 하는 값)의 입력에서 씁니다. encoder로 부터 얻은 정보로 y를 구하기 때문에, 더 잘 번역합니다.