Swin Transformer V2: Scaling Up Capacity and Resolution
Abstract
기존 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows를 더 큰 모델, 고해상도의 이미지에서 더 안정적으로 학습하는 것과 모델의 성능을 높이는 여러 테크닉을 기술하는 논문이다.
기존의 Swin Transformer v1을 30억 개의 parameter, 1536×15361536×1536 크기의 이미지에도 적용할 수 있게 개선한다. 이 논문에서 제시하는 vision model의 크기를 키우는 방법은 다른 모델에서 충분히 적용 가능하다고 한다.
- Vision model은 크기를 키울 때 학습이 불안정한 문제가 있고
- 고해상도의 이미지 혹은 window를 요구하는 많은 downstream vision task의 경우 어떻게 낮은 해상도를 처리하는 모델에서 높은 해상도를 처리하는 모델로 전이학습(transfer learninng)이 효과적으로 잘 될 수 있는지 불분명하다는 것이다.
큰 모델, 고해상도의 이미지를 처리할 때는 GPU 메모리 사용량도 중요한 문제인데, 이를 해결하기 위해 여러 기법을 적용해본다:
- 큰 모델의 학습 안정성을 높이기 위해 normalization을 attention 이전이 아닌 다음에 적용하고(post normalization) scaled cosine attention 접근법을 적용한다.
- 저해상도에서 고해상도 모델로 전이학습할 시 위치 정보를 log-scale로 continuous하게 표현한다.
- 이외에 GPU 메모리 사용량을 줄이는 여러 기법을 소개한다.
Swin-Transformer v1의 단점을 개선한 Swin-Transformer v2가 등장하게 되었다.
어떤 점이 다른 지 간략하게 알아보자
1. Pre-Norm
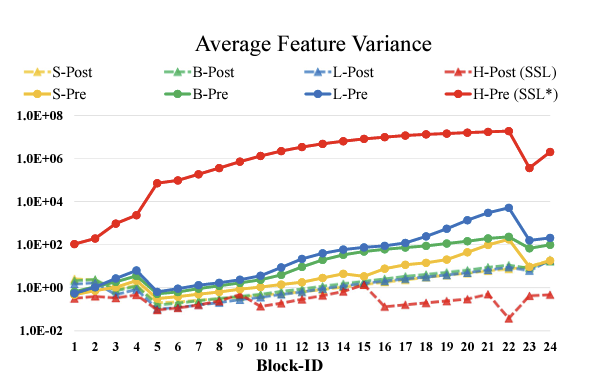
논문에서 저자는 크기가 큰 vision model들은 학습 과정에서 불안정함을 보인다고하였다. 크기가 큰 모델에서 계층간 activation amplitude가 일치하지 않고 그 크기가 점점 커진다고 하였다.
원래 v1의 구조를 살펴보면, “residual unit directly added back to the main branch.” 라는 표현을 쓰는데, 잔차가 main에 계속하여 더해지고, 그결과 activation value가 계속하여 누적된다고 한다. 층 별로 이 값이 누적되면서 amplitude(진폭)이 점점 커진다. 이를 해결하기 위해서 LN계층을 각 잔차의 시작에서 Attention 계층의 뒤로 이동하는 Post Norm이라는 새로운 Normalization 방법을 제시한다.
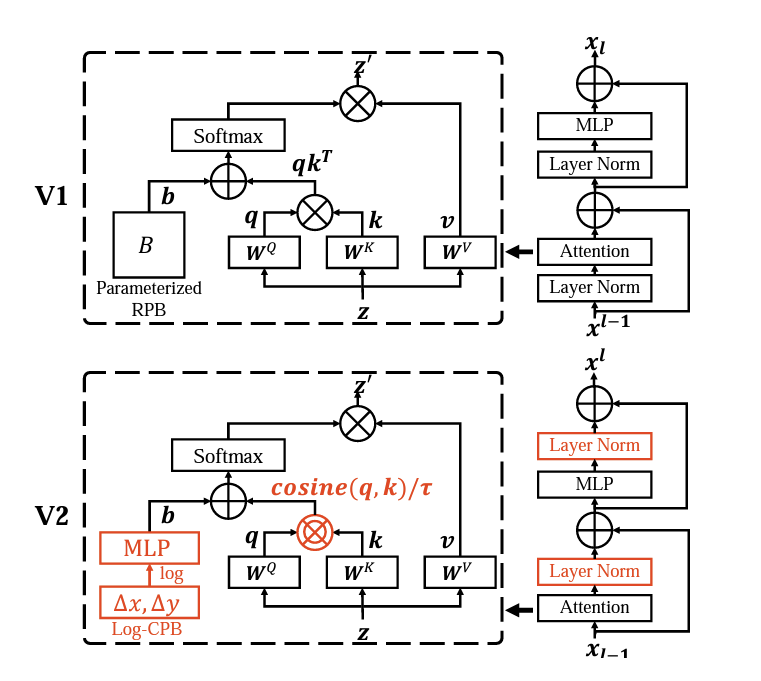
Post normalization을 적용한 결과, Layer을 통과해도 activation amplitude가 크게 커지지 않는다. 아래 사진에서 Pre-Norm, Post-Norm 사이의 차이를 볼 수 있다.
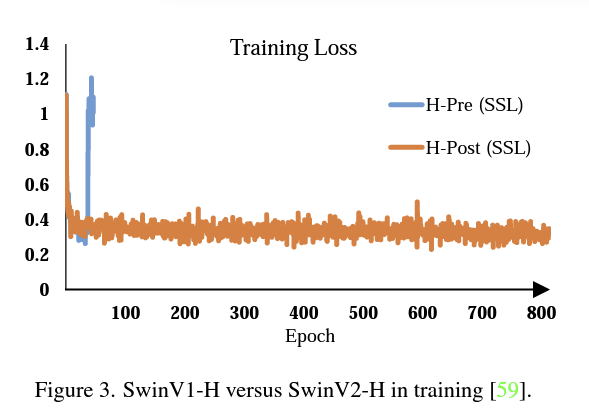
Pre-Norm을 사용했을 떄, Loss가 발산해서 터져버리는 것을 나타내기도 하였다.
2. Scaled cosine attention
💡 Neural Networks 에서 cosine similarity의 사용에 대한 논문[https://arxiv.org/pdf/1702.05870.pdf](https://arxiv.org/pdf/1702.05870.pdf)크기가 큰 vision model에 안정성의 향상을 주기 위해서 cosine attention을 사용한다.
또한 Scaled cosion attention은 attention value의 값이 block amplitude의 값과 상관없게 나오게 만들고, 그 값이 extreme으로 빠지게 될 가능성이 낮다.
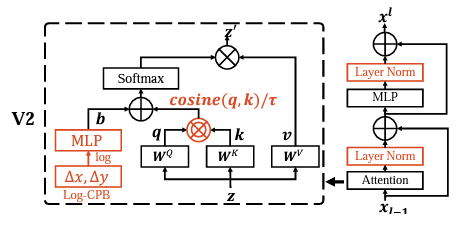
- 원래의 self attention computation에서는, query 와 key간 유사도를 계산할 때 dot-product로 계산한다.
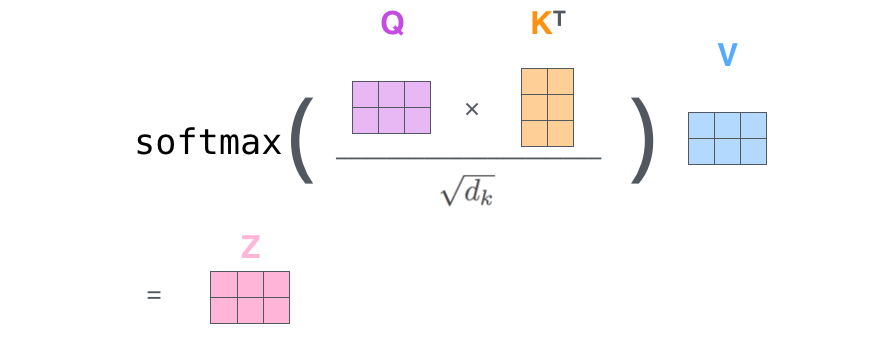
그러나, 일부 학습된 몇몇 블록과 크기가 큰 vision model에서, 일부 pixel이 dominated 되는 문제가 생긴다. (정확히 무슨 의미인지는 잘 모르겠음)
따라서, 다음 문제를 해결하기 위해, scaled cosine attention을 쓰게 되었다.
Bias은 pixel i,j 사이의 relative position bias이다.
는 learnable scalar로 non-shared across heads and layers이다.
Cosine Similarity
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다.
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 됩니다.
즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있습니다. 이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미합니다.
라고 가볍게 표현할 수 있다.
Similarity값이 그 cos값과 거의 같다고 할 수 있다.
3. Log-CPB
Swin-Transformer v1에서는 Relative position bias를 사용하게 되는데
해상도가 커질수록(pixel 이 커짐) 상대 좌표의 차이도 커질텐데, 이를 정비례하게 잡으면 그 차이가 너무 커진다. 그래서 log-scale로 바꾼다.
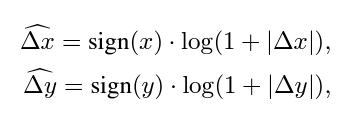
예를 들어 8×8 크기의 window를 16×16으로 키우면, 선형 비례하게 차이를 잡을 경우 [−7,7]에서 [-15, 15]가 되므로 8/7=1.14배만큼 extrapolate해야 한다. 그러나 log-scale의 경우 0.33배로 줄어든다.
Continous relative position bias
parameterized bias를 직접 최적화하는 대신 continuous position bias를 상대 좌표 하에서 작은 meta network에 맞춘다 (무슨 뜻인지 이해가 안됨)
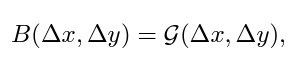
G는 2-layer MLP(사이의 activation: RELU)와 같은 작은 network이다. 임의의 상대좌표에 대해 bias value를 생성하고 따라서 어떤 크기의 window에든지 적절한 값을 생성할 수 있다. 추론 시에는 각 상대 위치를 사전에 계산할 수 있고 모델 parameter로 저장할 수 있으며, 이는 원래 parameterized bias 접근법과 같은 수준으로 간편하다.
