인트로
맥주 추천기능을 위해 필요한 맥주데이터를 모색하던 중
RateBeer라는 사이트를 찾았습니다.
이 사이트는 BeerAdvocate와 함께 가장 큰 맥주 리뷰 사이트로 유명하기에 해당 사이트에서 크롤링하도록 하겠습니다.
소스코드
Colab에서 진행할 것이기 때문에 아래와 같이 필요한 라이브러리를 install해주겠습니다.
! pip install pandas
! pip install numpy
! pip install selenium그리고 크롬 웹 브라우저에서 크롤링을 할 것이기 떄문에
! apt-get update
! apt install chromium-chromedriver
! cp /usr/lib/chromium-browser/chromedriver /usr/bin위와같이 추가적인 설정이 필요합니다.
그리고 필요한 라이브러리들을 가져오고, 수집할 맥주 목록을 정하도록 하겠습니다.
import pandas as pd
import numpy as np
import time # time.sleep(대기시간)
import re
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from googletrans import Translator
translator = Translator()정보를 수집할 맥주는 국내편의점에서 판매하는 맥주들 + 웹 element 위치 및 태그가 유사한 맥주들로 선정했습니다.
# 수집할 맥주 목록
beer_list = ['kloud', 'fitz super clear', 'Asahi super dry', 'Tsingtao', 'Heineken',
'Kirin ichiban', 'Sapporo Premium Beer / Draft Beer', 'stella artois', 'guinness braught',
'1664 Blanc', 'pilsner urquell', 'San Miguel', 'OB premier pilsner', 'cass fresh',
'dry finish', 'max hite', 'hite extra cold', 'victoria bitter', 'BINTANG pilsner',
'krombacher weizen', 'Miller Genuine Draft', 'Hoegaarden Cherry', 'TIGER REDLER',
"Suntory The Premium Malt's", 'REEPER B Weissbier', 'PEEPER B IPA', 'TIGER BEER',
'TSINGTAO WHEAT BEER', 'Erdinger Weissbier', 'Carlsberg', 'Budweiser ', 'Hoegarden',
'YEBISU', 'Paulaner Hefe-weissbier', 'Desperados', 'Peroni Nastro Azzurro',
'Edelweiss Snowfresh', 'Heineken Dark Lager', 'Kozel Dark 10', 'Guinness original',
'Filite', 'SEOULITE ALE', 'JEJU WIT ALE', 'Stephans Brau Philsner', 'Stephans Brau Larger',
'Stephans Bräu Hefe-Weizen Naturtrüb', 'Apostel Brau', 'Egger Zwickl', 'Egger Marzenbier',
'Holsten Premium Beer', 'Franzisaner Hefe-Weissbier', 'Egger Radler Grapefruit', 'Barvaria Premium',
'Barvaria 8.6', 'Lapin Kulta IV A', 'Grolsch Premium Larger', 'Gambrinus Original',
'XXXX Gold', 'Leffe Brown', 'Lowenbrau Original', 'Asahi Super dray Black ', 'Harbin Beer', "beck's",
'Hoegaarden Rosee', 'Platinum White Ale', 'Platinum Pale Ale', 'Ambar Especial Larger',
'Schöfferhofer Grapefruit', 'Volfas Engelman Grünberger Hefeweizen', 'Berliner Kindl Pilsener ',
'BURGE MEESTER', 'Red Rock',
'Warsteiner Premium Verum', "Queen's Ale Blonde Type"]
# 데이터프레임으로 저장
beer_list = pd.DataFrame(data=beer_list, columns=['검색이름'])그리고 drive와 mount합니다
from google.colab import drive
drive.mount('/content/drive')이후 웹 크롤링 이후 결과 xlsx, csv파일을 저장할 경로로 이동합니다. 4can10000won폴더에 저장할 것이기에 아래와 같이 입력합니다.
cd /content/drive/MyDrive/4can10000won/# 데이터 프레임 생성
data = pd.DataFrame(data=[], columns=['맥주정보', '검색이름', '맥주이름'])
# 셀레니움으로 웹브라우저를 오픈합니다.(Colab으로 웹드라이버 사용할때 필요한 설정)
options = webdriver.ChromeOptions()
options.add_argument('--headless') # Head-less 설정
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
# 크롤링 할 경로 설정
url = 'https://www.ratebeer.com/search?tab=beer'
driver.get(url)
driver.set_window_size(900, 900)
time.sleep(1)
n = len(beer_list['검색이름'])
# data = pd.DataFrame(data=[], columns=['beer_name', 'inforamtion', 'beer_type', 'total_point', 'alchol_degree', 'image_url'])
results = []아쉽게도 로컬에서 driver.get()한 것처럼 자동으로 웹브라우저가 열리진 않지만 내부적으로 잘 동작하고 있습니다.
def translate(sentence):
result = translator.translate(sentence, dest="ko")
return result.text
def crawl(driver, beer, data, k):
global n, results
driver = webdriver.Chrome('chromedriver', options=options)
# url open
print('url_open... {0} 맥주 데이터를 수집합니다..'.format(beer))
driver.get(url)
driver.set_window_size(900, 900)
# 1: 맥주 검색(페이지 로딩되는 시간을 기다리기 위해 time.sleep())
time.sleep(2)
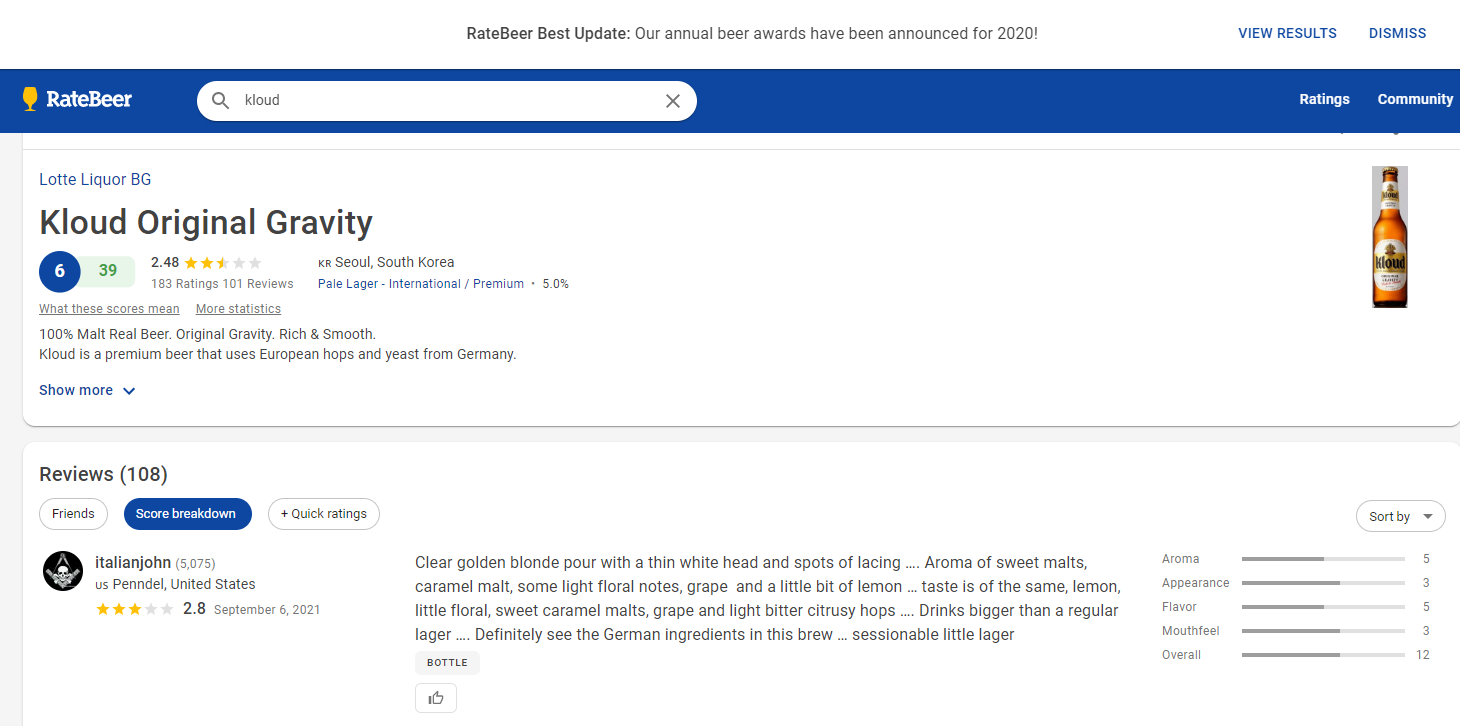
element = driver.find_element("xpath", '//*[@id="root"]/div[2]/header/div[2]/div[1]/div[2]/div/div/input')
time.sleep(2)
element.click()
time.sleep(2)
element.send_keys(beer)
time.sleep(3)
# 2: 상품 선택
driver.find_element("xpath", '//*[@id="root"]/div[2]/header/div[2]/div[1]/div[2]/div/div[2]/a[1]/div/div[2]').click()
# 3: 상품 이름 수집
time.sleep(3)
en_beer_name = driver.find_element(By.CSS_SELECTOR, '.MuiTypography-root.Text___StyledTypographyTypeless-bukSfn.pzIrn.text-500.colorized__WrappedComponent-hrwcZr.hwjOn.mt-3.MuiTypography-h4').text
beer_name = translate(en_beer_name) # 번역
beer_type_element_list = driver.find_elements(By.CSS_SELECTOR, '.MuiTypography-root.Text___StyledTypographyTypeless-bukSfn.kbrPIo.colorized__WrappedComponent-hrwcZr.liJcHu.Anchor___StyledText-uWnSM.eseQug.MuiTypography-caption')
beer_type_list = []
for beer_type_element in beer_type_element_list:
beer_type_list.append(beer_type_element.text)
beer_type = beer_type_list[0].split('-')[0]
if len(beer_type) > 6: beer_type = beer_type.split(' ')[1]
en_beer_info = driver.find_element(By.CSS_SELECTOR, '.LinesEllipsis').text
beer_info = translate(en_beer_info)
beer_total_point = driver.find_element(By.CSS_SELECTOR,
'.MuiTypography-root.Text___StyledTypographyTypeless-bukSfn.pzIrn.text-500.colorized__WrappedComponent-hrwcZr.hwjOn.mr-2.MuiTypography-body2').text
alchol_degree = driver.find_element(By.CSS_SELECTOR,
".MuiTypography-root.Text___StyledTypographyTypeless-bukSfn.kbrPIo.colorized__WrappedComponent-hrwcZr.bRPQdN.MuiTypography-caption").text
beer_image = driver.find_element(By.CSS_SELECTOR,
'.BeerCard___StyledImg-euvbSt.frMxAC.cursor-pointer.mr-4.rounded') # src 태그 값
beer_image_src = beer_image.get_attribute('src')
results.append([beer_name, beer_info, beer_type, beer_total_point, alchol_degree, beer_image_src])
# 4: xlsx, csv 파일로 저장
if k == n-1:
df = pd.DataFrame(results)
df.columns = ['beer_name', 'inforamtion', 'beer_type', 'total_point', 'alchol_degree', 'image_url']
df.to_csv("./4can10000won_beer_data"+".csv", encoding='utf-8')
df.to_excel("./4can10000won_beer_data" + ".xlsx")
return df
driver.quit()
return함수호출
n = len(beer_list['검색이름'])
for k in range(n):
beer = beer_list['검색이름'][k]
crawl(driver, beer, data, k)코드 설명
셀레니움으로 가져올 element들을 순서대로 확인하며 작동과정을 보겠습니다.
우선은 맥주 검색부분에 해당하는 element의 xpath를 가져옵니다.
이 과정은 F12를 누른 후, 해당 element에 해당하는 html 소스를 우클릭 한 뒤
Copy > Copy xpath를 누르면 그대로 경로를 가져올 수 있습니다.
최종 코드
참조

부족한 부분을 인지하는 것부터가 배움의 시작이다.