Config 뜯어보기
- dataset
- type, train/val/test Dataset 유형, data_root
- 주요파라미터 설정 가능(type, ann_file, img_prefix, pipeline)
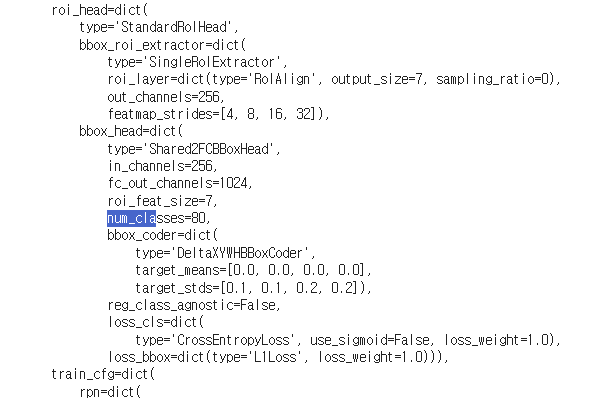
- model
- Object Detection model 의 backbone, neck, dense head, roi extractor, roi head(num_classes) 의 세부 설정
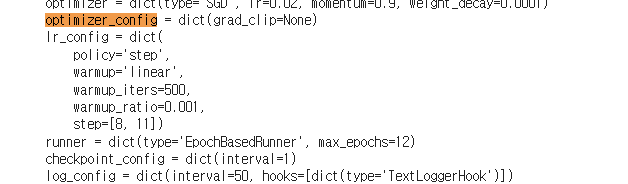
- schedule
- optimizer 유형 설정(SGD, Adam, Rmsprop)
- 최초 learning rate 와 동적 lr 적용 policy(step, cyclic, CosineAnnealing)
- 에폭 횟수
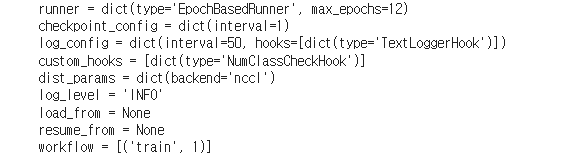
- run time
- callback 관련 설정
- checkpoint 파일
- intervl 에폭 수
- Data pipline

data pipeline 은 크게 3단계로 구분할 수 있다. data loading, preprocessing, formatting.
- data loading : 데이터 로드
- LoadImageFromFile
- LoadAnnotations
- Preprocessing : 원본 이미지의 픽셀 값 수정
- Resize: 크기 조정(img, img_shape, gt_boxes 수정)
- RandomFLip: 이미지를 왼, 오른쪽으로 플립하여 이미지 전처리(img, gt_boxes 좌표가 바뀜)
- Normalize : 정규화
- Pad : 고정된 비율로 맞출 때, 맞지 않는 부분을 패딩으로 처리.
- Formatting : 모델에 집어넣기 전 최종 가공
- DefaultFormatBundle: img, gt_bboxes, gt_labels 가공
- Collect : 최종 모델에 전달될 사항 추출
custom_imports = dict(imports=['path.to.my_pipeline'], allow_failed_imports=False)
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std = [58.395, 57.12, 57.375], to_rgb = True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', scale=(1333, 800), keep_ratio=True), # 원본 이미지 ratio 그대로 키움
dict(type='RandomFlip', prob=0.5), # 10번 중 5번은 augmentation
dict(type='Normalize', **img_norm_cfg), ## 추가
dict(type='Pad', size_dovisor=32),
dict(type='DefaultFormatBundle'),
dcit(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']), # 이 값들을 모델에 투입
]한가지 문제가, data.pipeline 도 있고 train_pipeline 은 또 따로 분리되어 있는 것이다. 중복되어 있는 것이 거슬리기 때문에, train_pileline 에서 설정을 마친 다음 data.pipeline 의 경우 pipeline([**train_pipeline]) 로 설정해주고 끝내는 것도 좋아보인다. (asterisk: 가져오기)

Mathematics, Algorithm, and IDEA for AI research🦖