사용할 데이터셋
이번에 사용할 데이터셋은 Oxford Pet 데이터이다.
- 하나의 이미지 당 하나의 annotation file 로 구성되어 있다.
- 고양이, 강아지 37종으로 구분된 데이터셋이 구축되어 있다.
Oxford Pet dataset 해당 링크에 들어가면 다운을 받을 수 있다. 나의 경우, tar.gz 압축 파일을 코드로 다운 받고 /content/data 밑에 압축을 해제했다.
✅ Oxford Pet 데이터 다운과 압축 해제
!wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
!wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
# /content/data 디렉토리를 만들고 해당 디렉토리에 다운로드 받은 압축 파일 풀기.
!mkdir /content/data
!tar -xvf images.tar.gz -C /content/data
!tar -xvf annotations.tar.gz -C /content/data그러면 data 폴더에 다음과 같은 구조의 데이터들이 들어온다.
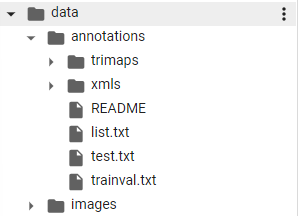
- data 폴더 아래에 크게 annotations 와 images 폴더가 있다
- images 폴더 바로 아래에는 다수의 png 파일들이 들어가있고,(PASCAL VOC 와 유사)
- annotations 는 또다시 폴더가 있다. trimaps 과 xmls, 그리고 txt 파일들.
- 사용할 것은 xmls 폴더 안에 들어있는 xml 형식의 파일들이다.

역시나 필요한 name, 좌상단 우하단의 GT bboxes 정보들이 잘 담겨있는 것처럼 보인다. 그러나 name 의 경우 37개의 분류하고자 하는 항목이 아닌 개와 고양이 2가지 클래스밖에 없다. 각각의 종을 확인하기 위해선 아까 봤던 3개의 txt 파일을 이용해야 한다.
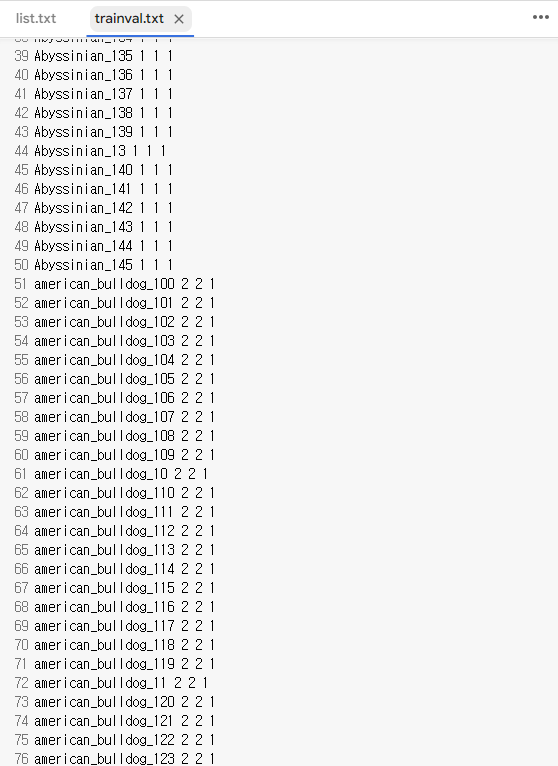
trainval.txt 을 보면 위와 같이 각 종의 클래스 이름과, 총 3680장에 대한 정보가 포함되어 있으므로 결과적으로 이 txt 파일도 활용해야 한다.
Train, Valid meta 파일을 별도로 만들기
PASCAL VOC와 비슷한 현재 데이터 Oxford Pet 의 경우 xml 하나로 모아주는 과정이 필요하다. 따라서 하나로 모아준 텍스트 자체를 하나의 파일로 저장하는, 즉 메타파일 2개 (train 과 valid 각각에) 을 만들어주자. 현재 data/annotations/xmls 아래에는 다음과 같은 많은 파일들이 있다.
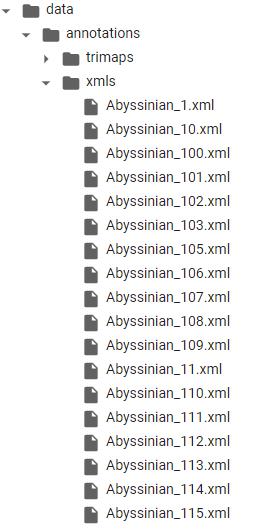
결국 이 파일들은 data/images 아래 png 파일들과 상응하여 해당 이미지 파일의 정답 역할을 하게될 것이다. (종이름번호 형식) 따라서 이 파일들을 가리키는 종이름번호 형식의 메타 파일이 2개 필요한 상황이다.
이전 글에서 이러한 메타파일의 역할을 해주는 것이 trainval.txt 에 있다고 했다. 현재 trainval.txt 를 보면 다음과 같다.

여기서 우리가 원하는 것은 맨 앞의 결과물이었기 때문에, 일련의 과정을 거쳐 가져오도록 한다.
✅ trainval.txt 데이터프레임 만들기
import pandas as pd
pet_df = pd.read_csv('./data/annotations/trainval.txt', sep=' ', header=None, names=['img_name', 'class_id', 'etc1', 'etc2'])
pet_df.head()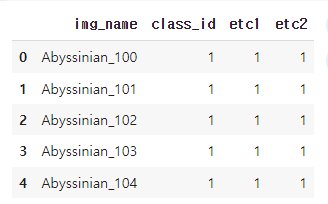
✅ 이름만 추출한 새로운 열 만들기
# apply lambda 적용, 1 row 씩 들어오면서 _를 찾아 그 앞 인덱스까지 가져옴.
pet_df['class_name'] = pet_df['img_name'].apply(lambda x:x[:x.rfind('_')])
pet_df.head()
✅ train, valid 쪼개고 img_name 열만 가져와서 train.txt 와 val.txt 파일로 저장
# train_test_split 해주기 (test size = 0.1)
from sklearn.model_selection import train_test_split
train_df, val_df = train_test_split(pet_df, test_size=0.1, stratify=pet_df['class_id'], random_state=2021)
# 추출할 img_name 대로 sorting
train_df = train_df.sort_values(by='img_name')
val_df = val_df.sort_values(by='img_name')
# 메타파일로 사용할 train.txt 와 val.txt 만들기
train_df['img_name'].to_csv('./data/train.txt', sep=' ', header=False, index=False)
val_df['img_name'].to_csv('./data/val.txt', sep=' ', header=False, index=False)마지막으로 후에 모델 내부적으로 사용할 종 이름 또한 리스트로 저장해두자.
pet_classes_list = pet_df['class_name'].unique().tolist()
print(pet_classes_list)['Abyssinian', 'american_bulldog', 'american_pit_bull_terrier', 'basset_hound', 'beagle', 'Bengal', 'Birman', 'Bombay', 'boxer', 'British_Shorthair', 'chihuahua', 'Egyptian_Mau', 'english_cocker_spaniel', 'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese', 'japanese_chin', 'keeshond', 'leonberger', 'Maine_Coon', 'miniature_pinscher', 'newfoundland', 'Persian', 'pomeranian', 'pug', 'Ragdoll', 'Russian_Blue', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu', 'Siamese', 'Sphynx', 'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']✅ 완성된 train.txt, val.txt 파일 확인


mmdetection 의 middle annotations format 으로 변환
이전에 했던 과정과 거의 비슷하다. 이전과의 차이점이라 한다면, PSCAL VOC 와 비슷한 데이터들의 경우 annotation 파일들이 여러개인 문제가 있었고, 따라서 메타파일을 하나 지정하고 그 파일에 들어가서 읽어온 이름들로 annotation 파일 이름을 만들었다. 또한 현재의 경우 클래스 명은 /annotations/xmls/이름.xml 의 이름 그 자체에서 가져오고, 바운딩박스 좌표는 해당 xml 의 -> object 의 하위 bndbox 에 좌상단우하단 좌표를 반환하도록 한다. 다음은 함수와 클래스들이다.
✅ annotation 디렉토리와 xml 파일 이름을 받아 절대 경로를 만들고, 좌표와 클래스 명 추출하는 함수
import xml.etree.ElementTree as ET
# 1개의 annotation 파일에서 bbox 정보 추출. 여러개의 object가 있을 경우 이들 object의 name과 bbox 좌표들을 list로 반환.
def get_bboxes_from_xml(anno_dir, xml_file):
anno_xml_file = osp.join(anno_dir, xml_file)
tree = ET.parse(anno_xml_file)
root = tree.getroot()
bbox_names = [] # -> 클래스 명 추출
bboxes = [] # -> 바운딩박스 좌표
# 파일내에 있는 모든 object Element를 찾음.
for obj in root.findall('object'):
# object의 클래스명은 파일명에서 추출.
bbox_name = xml_file[:xml_file.rfind('_')]
# 바운딩 박스의 정보는 ojbect 안에 bndbox 에 존재.
xmlbox = obj.find('bndbox')
x1 = int(xmlbox.find('xmin').text)
y1 = int(xmlbox.find('ymin').text)
x2 = int(xmlbox.find('xmax').text)
y2 = int(xmlbox.find('ymax').text)
bboxes.append([x1, y1, x2, y2])
bbox_names.append(bbox_name)
return bbox_names, bboxes✅ mmdet 프레임웍에 등록하는 클래스. 위의 함수로부터 반환받은 클래스명과 좌표와, 기존 이미지 파일로부터의 이름, 너비, 높이를 딕셔너리로 middle_form 으로 전환.
import copy
import os.path as osp
import mmcv
import numpy as np
import cv2
from mmdet.datasets.builder import DATASETS
from mmdet.datasets.custom import CustomDataset
import xml.etree.ElementTree as ET
PET_CLASSES = pet_df['class_name'].unique().tolist()
@DATASETS.register_module(force=True) # -> mmdet 의 프레임웍에 등록하는 decoration
class PetDataset(CustomDataset):
CLASSES = PET_CLASSES # -> 클래스 명들을 저장
# 인자로 전달받은 ann_file 은 train.txt와 val.txt
def load_annotations(self, ann_file):
cat2label = {k:i for i, k in enumerate(self.CLASSES)} # -> 클래스명: 숫자로 전환
image_list = mmcv.list_from_file(self.ann_file)
# 포맷 중립 데이터를 담을 list 객체
data_infos = []
for image_id in image_list:
# self.img_prefix는 images 가 입력될 것임.
filename = '{0:}/{1:}.jpg'.format(self.img_prefix, image_id)
# 원본 이미지의 너비, 높이를 image를 직접 로드하여 구함.
image = cv2.imread(filename)
height, width = image.shape[:2]
# 개별 image의 annotation 정보 저장용 Dict 생성. key값 filename에는 image의 파일명만 들어감(디렉토리는 제외)
data_info = {'filename': str(image_id) + '.jpg',
'width': width, 'height': height}
# label_prefix 를 만들기 위해 images -> annotations
label_prefix = self.img_prefix.replace('images', 'annotations')
# 주소는 ./annotations/xmls/아이디.xml 형태임
anno_xml_file = osp.join(label_prefix, 'xmls/'+str(image_id)+'.xml')
# 이미지는 있지만 anno 없는 경우는 건너뛰기
if not osp.exists(anno_xml_file):
continue
# get_bboxes_from_xml() 를 이용하여 개별 XML 파일에 있는 이미지의 모든 bbox 정보를 list 객체로 생성.
anno_dir = osp.join(label_prefix, 'xmls')
bbox_names, bboxes = get_bboxes_from_xml(anno_dir, str(image_id)+'.xml')
#print('#########:', bbox_names)
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
# bbox별 Object들의 class name을 class id로 매핑. class id는 tuple(list)형의 CLASSES의 index값에 따라 설정
for bbox_name, bbox in zip(bbox_names, bboxes):
# 만약 해당 클래스 이름이 있는 이름이라면 좌표 (gt_bboxes), 레이블 숫자 (cat2label[bbox_name]) 입력
if bbox_name in cat2label:
gt_bboxes.append(bbox)
gt_labels.append(cat2label[bbox_name])
else: # 없다면 ignore 에 각각 입력
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
# 개별 image별 annotation 정보를 가지는 Dict 생성. 해당 Dict의 value값을 np.array형태로 bbox의 좌표와 label값으로 생성.
data_anno = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.long),
'bboxes_ignore': np.array(gt_bboxes_ignore, dtype=np.float32).reshape(-1, 4),
'labels_ignore': np.array(gt_labels_ignore, dtype=np.long)
}
# 현재 info 에는 3가지 정보, ann 을 추가 (하나의 사진 안에서)
data_info.update(ann=data_anno)
# 전체 infos 에 딕셔너리 추가 (각 사진에서)
data_infos.append(data_info)
#print(data_info)
return data_infos모델 학습
✅ pretrained 모델 다운로드
본격적인 학습에 들어가기 위해서 pretrained 된 모델을 다운로드 해주자. config파일과 checkpoint 파일이 필요했었다.
config_file = './mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = './mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 모델은 mmdetection/checkpoints 아래에다 다운로드
!cd mmdetection; mkdir checkpoints
!wget -O ./mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
# Config 파일은 cfg 객체로 만들어주자
from mmcv import Config
cfg = Config.fromfile(config_file)
print(cfg.pretty_text)✅ 구글 드라이브에 pet_work_dir 디렉토리 생성
이번에는 학습 시간이 오래걸리기 때문에 모델을 저장할 디렉토리를 따로 구글 드라이브에 만들어줬다. 구글 드라이브 연동 후,
!mkdir "/mydrive/pet_work_dir"✅ Config 파일 수정
Config 파일은 어떻게 이루어져 있고, 어떻게 수정하는지는 지난 포스팅들에서 다루었으니 설명은 생략하도록 하겠다.
from mmdet.apis import set_random_seed
# dataset에 대한 환경 파라미터 수정.
cfg.dataset_type = 'PetDataset'
cfg.data_root = '/content/data/'
# train, val, test dataset에 대한 type, data_root, ann_file, img_prefix 환경 파라미터 수정.
cfg.data.train.type = 'PetDataset'
cfg.data.train.data_root = '/content/data/'
cfg.data.train.ann_file = 'train.txt'
cfg.data.train.img_prefix = 'images'
cfg.data.val.type = 'PetDataset'
cfg.data.val.data_root = '/content/data/'
cfg.data.val.ann_file = 'val.txt'
cfg.data.val.img_prefix = 'images'
# class의 갯수 수정.
cfg.model.roi_head.bbox_head.num_classes = 37
# pretrained 모델 (상대경로, cd %mmdet 필)
cfg.load_from = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 학습 weight 파일로 로그를 저장하기 위한 디렉토리로 구글 Drive 설정.
cfg.work_dir = '/mydrive/pet_work_dir'
# 학습율 변경 환경 파라미터 설정.
cfg.optimizer.lr = 0.02 / 8
cfg.lr_config.warmup = None
cfg.log_config.interval = 4
cfg.runner.max_epochs = 5
# 평가 metric 설정.
cfg.evaluation.metric = 'mAP'
# 평가 metric 수행할 epoch interval 설정.
cfg.evaluation.interval = 4
# 학습 iteration시마다 모델을 저장할 epoch interval 설정.
cfg.checkpoint_config.interval = 2
# 학습 시 Batch size 설정(단일 GPU 별 Batch size로 설정됨), 사진이기 때문에 장 수 단위
cfg.data.samples_per_gpu = 4
# Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# 두번 config를 로드하면 lr_config의 policy가 사라지는 오류로 인하여 설정.
cfg.lr_config.policy='step'
# ConfigDict' object has no attribute 'device 오류 발생시 반드시 설정 필요. https://github.com/open-mmlab/mmdetection/issues/7901
cfg.device='cuda'✅ 본격적인 학습 수행
본격적인 학습을 수행하려면, 다음의 세가지가 필요하다.
- build_datset: 데이터셋 빌드, 인자는 cfg.data.train

- build_detector: 모델 빌드, 인자는 cfg.model, train_cfg, test_cfg

- train_detector: 모델 훈련, 인자는 build_detector 로 만든 모델, cfg 전체
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.apis import train_detector
# train용 Dataset 생성.
datasets = [build_dataset(cfg.data.train)]
# build_detector
%cd mmdetection
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
model.CLASSES = datasets[0].CLASSES
# 훈련된 모델 저장
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# train_detector
train_detector(model, datasets, cfg, distributed=False, validate=True)성능 확인 및 Inference
t4 기준으로 학습에는 1시간 20분 정도 걸린 것 같다. 성능은 다음과 같이 나왔다.
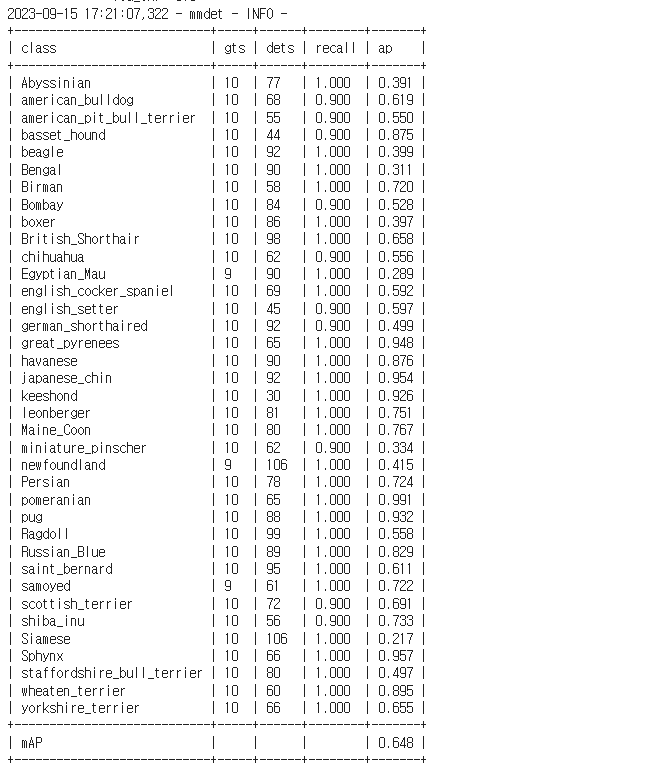
- 전체적인 mAP 는 0.648로 나쁘지 않다
- 간혹가다 특정 종에 대해서 성능이 떨어지는 결과가 나온다. Abyssinian, Bengal, Egpytian_Mau 등..
- 그러나 높은 mAP는 정말 높다. great_pyreness, kesshoned, Sphynx 등
예측하는 코드는 다음과 같다.
from mmdet.apis import show_result_pyplot
import cv2
checkpoint_file = '/content/drive/MyDrive/pet_work_dir/epoch_4.pth'
# checkpoint 저장된 model 파일을 이용하여 모델을 생성, 이때 Config는 위에서 update된 config 사용.
model_ckpt = init_detector(cfg, checkpoint_file, device='cuda:0')
# BGR Image 사용
img = cv2.imread('/content/data/images/Abyssinian_88.jpg')
#model_ckpt.cfg = cfg
result = inference_detector(model_ckpt, img)
show_result_pyplot(model_ckpt, img, result, score_thr=0.3)예측할 땐 다음과 같은 것들이 필요하다.
- init_detector: 저장된 모델을 불러오기, 인자로는 cfg, 모델 주소가 필요
- inference_detector: 실제 예측 수행, init_detector 로 만든 모델과 이미지 필요
- show_result_pyplot: 예측을 띄워주기, init_dector 로 만든 모델, 이미지, inference_detector 가 반환한 예측 결과, threshold 가 필요.
마무리
이번에도 역시나 새로운 데이터셋인 Oxford Pet 데이터셋을 가지고 와서 pretrained 모델을 이어서 학습하는 형태로 훈련을 진행해봤다. 훈련쪽 코드는 이제 많이 알 거 같은데, 데이터셋 구조를 middle form 으로 변환시키는 과정이 아직은 익숙치 않다. 그러나 그렇게 복잡한 과정은 또 아니므로, 데이터를 파악하고 (이미지, anno, meta file 은 어디있는지) 이에 맞게 자유자재로 middle form 으로 변환하고, 학습하는 과정까지를 좀 더 반복해보고자 한다!
