Faster R-CNN 영상처리 실습
이번엔 이미지가 아닌 영상을 처리해보자! 움직이는 영상에서 object detection 을 수행한다. 그러나 로직은 크게 다르지 않고 프레임마다 object Detection 을 수행한것을 이어붙이기만 하면 된다.
✅ VideoCapture 와 VideoWriter 설정
VideoCapture 을 사용하면 프레임별로 캡쳐할 수 있는 상태가 되고, 프레임의 크기와 fps 를 설정할 수 있다. 또한 VideoWriter 을 통해 영상을 쓸 수 있는데, 이때 인자로 전달해줄 몇가지 정보들이 필요하니 알아보자.
video_input_path = '/content/data/Jonh_Wick_small.mp4'
cap = cv2.VideoCapture(video_input_path)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # cap 후 get 을 하면 프레임카운트가 가능
print('총 Frame 갯수:', frame_cnt)가져올 영상은 존윅이 말을 타는 2초짜리 짧은 영상이다. cv2.VideoCapture() 을 이용해서 프레임별로 캡쳐할 수 있는 상태가 된다. 객체에 .get(cv2.CAP_PROP_FRAME_COUNT) 를 적용하면 프레임이 몇 개인지 카운트가 가능하다.

이제 비디오캡쳐와 라이터 두 가지를 설정해주자. 캡쳐는 그대로 수행하고, Writer 설정을 위해선 codec, size, fps 세가지 정보가 필요하다.
video_input_path = '/content/data/Jonh_Wick_small.mp4'
video_output_path = './data/John_Wick_small_cv01.mp4'
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID') # -> video writer 을 어떤 포맷으로? 코덱 설정
# 비디오 사이즈와 비디오 fps 설정
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
# writer 에 입력과 동일하게 인자 전달
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)이제 cap 과 vid_writer 가 어떻게 이용되는지 주의깊게 보면된다.
✅ Object Detection 수행 (프레임별로)
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# 영상 프레임을 돌면서 프레임이 없을 때까지 object detection
while True:
hasFrame, img_frame = cap.read() # -> cap.read() 를 하게되면 다음에 프레임이 있는지와, 현재 프레임정보 반환
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
rows = img_frame.shape[0]
cols = img_frame.shape[1]
# 원본 이미지 배열 BGR을 RGB로 변환하여 배열 입력
cv_net.setInput(cv2.dnn.blobFromImage(img_frame, swapRB=True, crop=False))
start= time.time()
# Object Detection 수행하여 결과를 cv_out으로 반환
cv_out = cv_net.forward()
frame_index = 0
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.5 이상만 추출
if score > 0.5:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_0딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
#print(class_id, caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(img_frame, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(img_frame, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, red_color, 1)
print('Detection 수행 시간:', round(time.time()-start, 2),'초')
vid_writer.write(img_frame)
# end of while loop
vid_writer.release()
cap.release()-
cap.read()는 다음 프레임이 있는지 True or False 정보와, 현재 프레임을 반환하는 중요한 메서드다. 만약 다음 프레임이 없으면 반복문을 빠져나오는 코드를 넣어주자. -
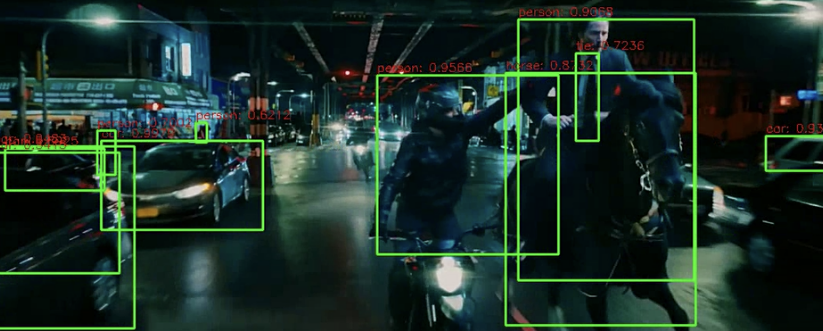
다음은 이미지에서 Object Detection 과 거의 같다. 이미지를 네트웍에 입력하고, forward() 를 수행하며.. 각 프레임에서 object detection 을 수행해서 네모박스를 씌우고 텍스트를 넣으면 된다.
-
이때 하나의 이미지 프레임 연산이 끝나면
vid_writer.write()를 통해 비디오를 써주자. -
모두 끝나면 vid_writer 와 cap 을
.release()를 통해 종료시킨다.
영상을 실행시켜보면 프레임별로 열심히.. object detection 된 것을 확인할 수 있다!
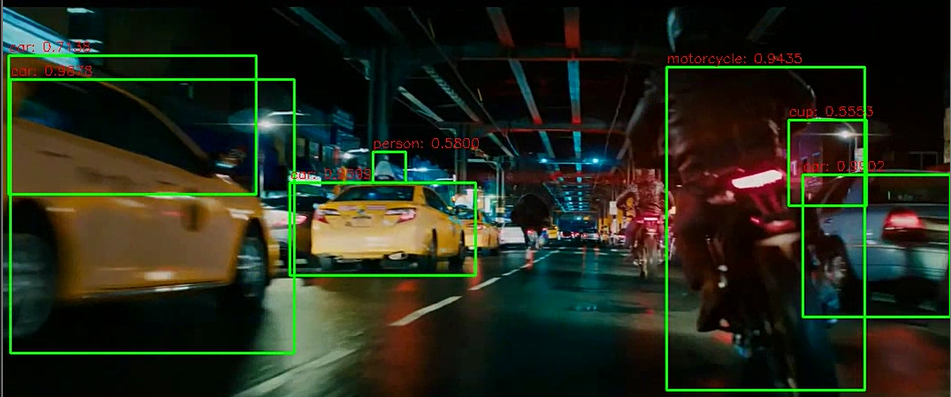

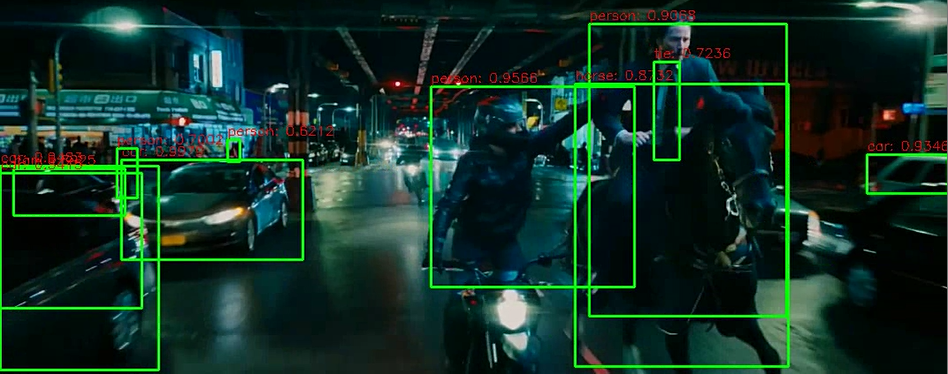
✅ Video Detection 함수 생성
이제 기본 틀이 되는 함수 형태로 생성해보자.
def do_detected_video(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
img_frame = get_detected_img(cv_net, img_frame, score_threshold=score_threshold, use_copied_array=False, is_print=is_print)
vid_writer.write(img_frame)
# end of while loop
vid_writer.release()
cap.release()➡️ 함수실행
do_detected_video(cv_net, '/content/data/Jonh_Wick_small.mp4', './data/John_Wick_small_02.mp4', 0.2, False)모던 Object Detection 모델 아키텍처
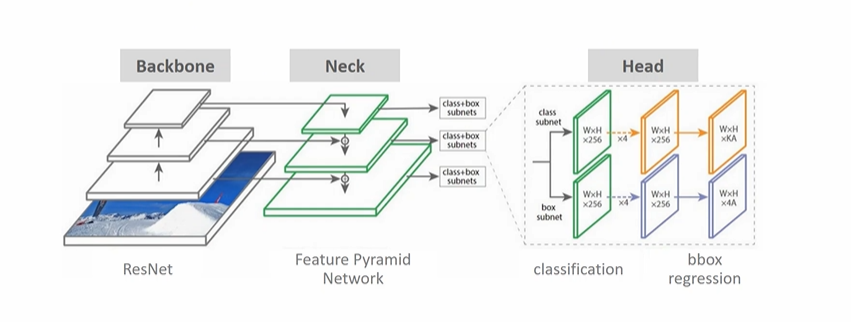
2020년 정도부터 대두된 최신의 Object Detection 모델의 아키텍처이다.
Backbone 은 이미지 분류에서 많이 쓰이는 모델을 포함한다. 이전에는 VGGNet 을 많이 썼으나, 최근에는 이 backbone 의 이미지 분류모델로 ResNet 을 사용한다. 결국 backbone 의 주요 역할은, 원본 이미지를 받아 주요 피처들을 담는, 추상화된 피처맵을 만들어내는 것이다. (깊이가 깊고 크기는 작아진다.)
이전에 Obeject Detection 만해도 backbone, Head 는 등장했었는데 Neck 이란 또 무엇일까? backbone 과 Head 를 연결하는 요소로써, FPN을 지칭한다. 이전 backbone 에서 가로 세로 크기는 줄어들고 더 깊어진다면, Neck 의 경우에는 다양한 사이즈의 피처맵을 받아 정보들을 추출한다. 마지막 레이어에서 가장 작은 피처맵(추상화된)만 쓰는 것이 아니라, 다양한 깊이의 여러 피처맵 역시 정보를 추출하는 용도로 사용한다는 것이다. 이렇게 정보를 담아내면 결국 작은 object 에 대해서도 detection해내는 것이 가능해진다. (덜 추상화된 이미지에서도 detection 을 수행하므로)
마지막으론 Head 에선 우리가 원하는 분류와 회귀를 수행한다.
✅ Feature Pyramid Network (FPN)
작은 오브젝트들은 어떻게 Detection 할 것인가에 대한 고민의 결과물이다. 결과적으로 FPN을 사용하면 그렇지 않았을 때보다 작은 Object 들을 더 잘 Detect 할 수 있으며, 상위 피처맵의 추상화된 정보와 하위 피처맵의 정보를 결합하는 역할로 기능하게 된다.
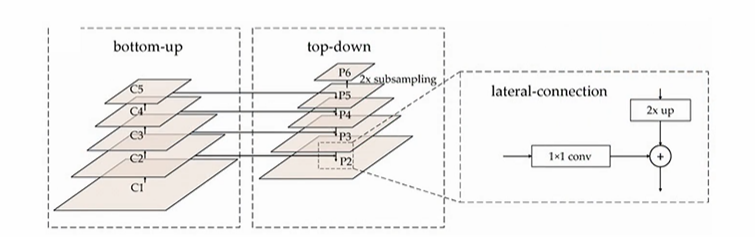
사실 이 Neck 부분엔 다양한 변종들이 가능하나, 결국은 이 FPN의 파생이라고 한다. 피처맵에 전달할 때에는 top-down 할 때 상위피처맵의 추상화된 정보는 2X 사이즈를 up하고, bottom-up 에 2X 된 것과 동일한 사이즈의 피처맵을 가져와서 더한다. 결과적으로 2배 커진 사이즈의 피처맵이 down 에서 만날 수 있는 구조이다. (결합) 만약 이 과정을 생략하고 bottom-up 에서 바로 Object Detection 을 수행한다면 그것이 SSD라 불리우는 Single shot detector 이다.
✅ FPN을 활용한 Faster RCNN RPN
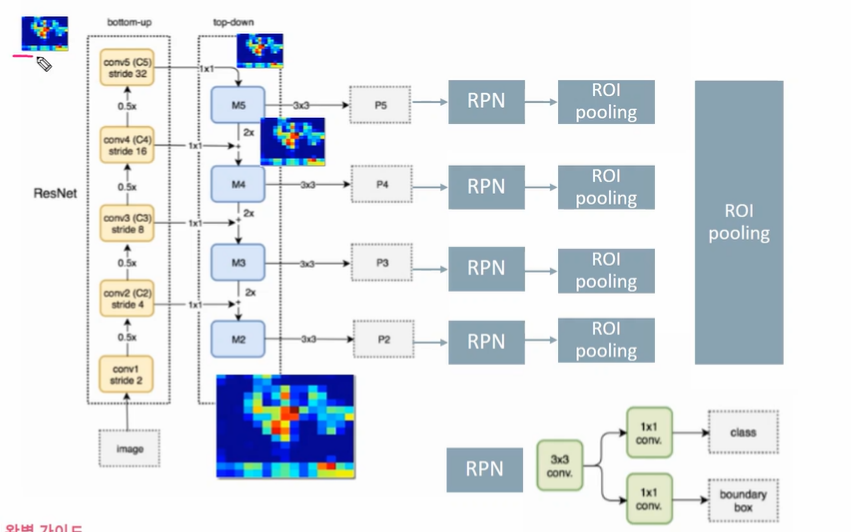
bottom-up 으로 표시된 부분이 backbone 이며, top-down 과 옆의 p2-p5 가 neck 에 해당하는 부분이라고 할 수 있다. top-down 의 가장 위 피처맵(기준)을 만들기 위해, 그 아래로 내려가며 2X + 1X 연산을 수행해 가장 아래의 피처맵까지 완성할 수 있다. (크기만 표현되어 있다, 덜 추상화된 피처맵을 더하므로 구성 내용은 다를 것이다.)
완성된 피처맵을 (p2, p3, p4, p5)가지고 RPN을 수행한다. RPN의 연산은 이전에 살펴본 바와 같이 3X3 conv, 1X1 conv 연산 2개로 구성된다. 각각의 ROI pooling 을 통해 최종적으로 분류와 회귀를 수행한다.
MMDetection 의 모델 아키텍쳐
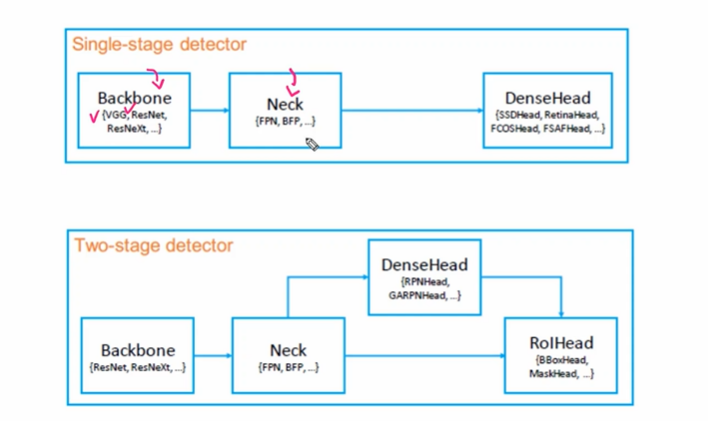
- single stage 의 경우 backbone -> Neck -> DenseHead
- Two-stage 의 경우 backbone -> Neck -> DenseHead -> ROIHead
Two-stage Detector 같은 경우 DenseHead 에 해당하는 부분이 RPN이 된다. 영역을 추천하는 부분이다! SSD의 경우 이 네트워크를 제거하고 Neck 에서 바로 head 로 넘어간다.
