이전까지 학습한 모델들은 필수적으로 RP, Region proposal 역할을 하는 요소를 지니고 있었다. 대표적인 것으로 Selective Search(SS)나, RPN(Region proposal network) 라고 하는 것들이 있었으며, 이것들은 모두 Object Detection 을 위해 다음 네트워크에 어떤 영역이 오브젝트가 있을만한지 추천해주는 기능을 했다. 이를 Two-stage detector 라고 하며, 영역을 추천해주는 것 따로, 추천된 영역에서 바운딩박스를 확정하는 것 따로 이루어진 모델들을 뜻한다.
- Two-stage detector: RCNN -> SPPNet -> Fast RCNN -> Faster RCNN -> Pyramid Networks
그러나 Two-stage 의 경우 Detection 의 시간이 오래걸린다는 단점이 있다. 그 중에서도 빠른 Faster RCNN 도 7fps 니.. 문제가 있었다. 따라서 시간을 줄이기 위해 2가지 스테이지를 하나로 합치는 One-stage detector 가 등장한다.
지금 알아볼 것은 SSD라는, Faster RCNN 다음에 등장하고 속도가 빠르며, 성능(mAP) 또한 더 높은 모델이다. (One-stage 의 경우 YOLO가 가장 성행하고 있으나 아이디어들이 SSD에서 나왔다!) (더 뒤에 나올 Retina-Net 은 속도는 조금 떨어지지만 정밀도는 더 높인 모델이다.)
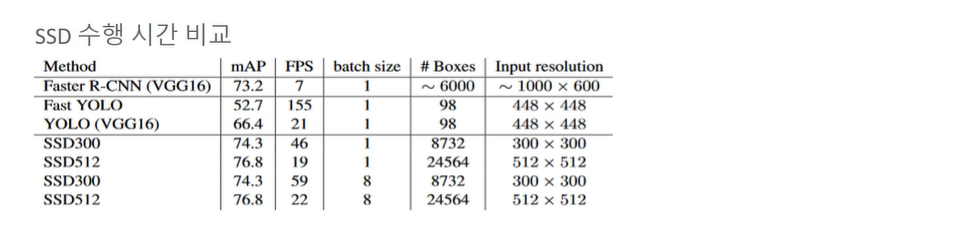
SSD 구조
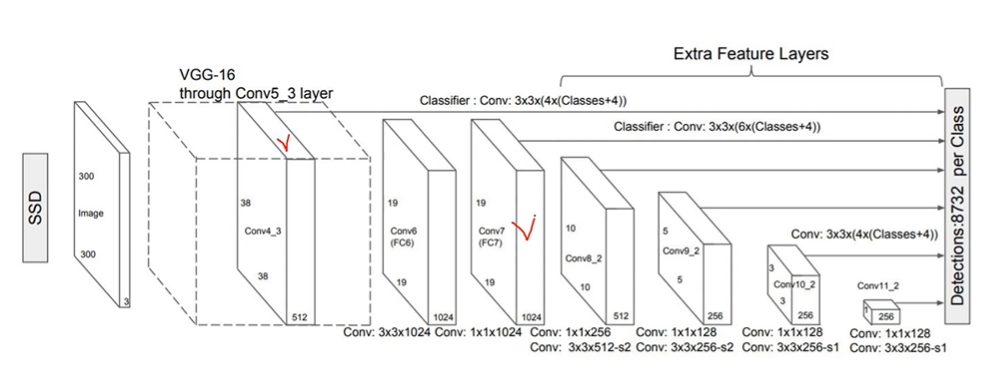
- 원본 이미지를 CNN 통과시켜서 피처맵을 결과로 한다
- 점점 작아지는 피처맵
- 피처맵에서 앵커 박스들이 Object Detection 과 Classification 을 추출하는 구조
따라서 SSD에서 중요한 것은 1. Multi Scale Feature Layer 2. Default Anchor Box 이다.
SSD 주요구성 요소
-
- 윈도우 사이즈는 고정, 이미지 scale 을 조정하는 Object Detection (-> 이미지 피라미드)
-
- 다른 크기의 Feature Map 을 이용한 Object Detection
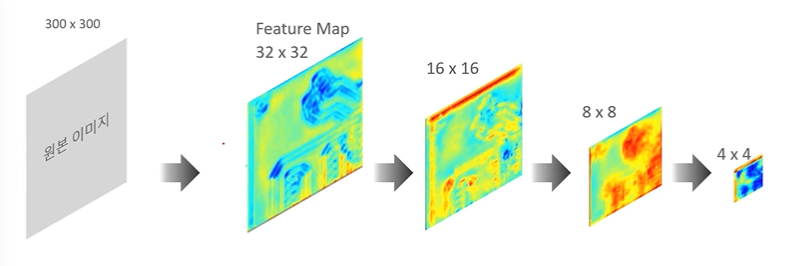
- 다른 크기의 Feature Map 을 이용한 Object Detection
-
CNN연산을 통해 피처맵 사이즈가 작아지며 이미지의 추상적인 정보로 변하게 된다
-
4 X 4 는 핵심 중에 핵심 정보.
-
개별 Feature Map 에 대해 모두 Object Detection 을 수행한다.
-
따라서 같은 윈도우를 가지고도 피처맵 사이즈에 맞게 작은 Object, 큰 Object 를 모두 잡아낼 수 있게된다.
-
Feature Map 의 크기가 작을수록, 더 큰 이미지를 찾을 수 있다.
-
- Anchor Box 기반의 Object Detection 모델 - Faster RCNN
RPN이 하는 역할을 Detector 도 거의 동일하게 2번 수행한다. RPN에서는 20,000개의 Anchor box 들이 분류와 회귀를 수행하게 된다.
- Anchor Box 기반의 Object Detection 모델 - Faster RCNN
-
- Anchor box 를 활용한 Object Detection
anchor box의 역할을 RPN에서만으로 한정한 것이 Faster RCNN 계열이었다면, 역할을 확장해 anchor box 가 object detection 하는데에도 활용을 해보자!라는 것이 SSD, YOLO이다.
- Anchor box 를 활용한 Object Detection
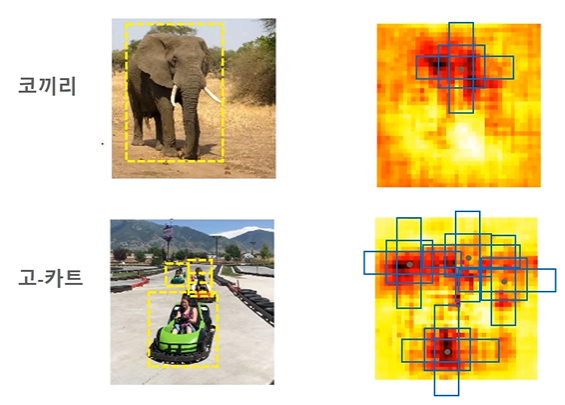
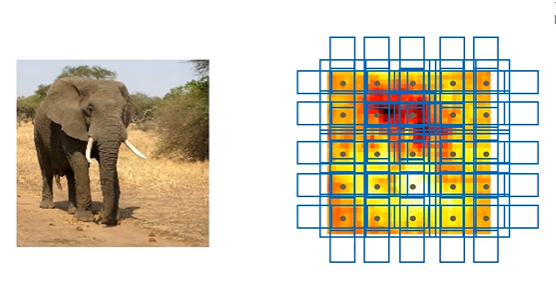
- 코끼리 이미지 -> 피처맵에서 활성화된 부분이 object 일 확률이 높다
- 피처맵 16 X 16 이라 한다면, 각 포인트에 모두 앵커박스(9)를 할당한다.
- 앵커박스 중 GT의 영역과 가장 가까운 박스에, 영역 정보 뿐 아니라 해당 피처맵에서 해당 박스가 코끼리라는 정보까지 준다.
- 고-카트도 마찬가지로 해당 피처맵이 들어왔을 때 앵커박스에게 바운딩박스의 위치 + label 은 고-카트라는 정보를 준다.
정리하자면, 개별 anchor 박스가 두가지 정보를 가질 수 있도록 학습한다.
1. anchor box 와 겹치는 feature 맵 영역의 오브젝트 클래스 분류
2. GT box 예측할 수 있도록 수정된 좌표
따라서 새로운 test 데이터가 들어오면 개별 anchor 박스는 피처맵을 보고, anchor 박스마다 오브젝트 클래스를 알 뿐만 아니라(Softmax) 수정좌표도 예측할 수 있도록 한다. 아래의 경우는 5X5 피처맵의 예시.
SSD Network 의 구성
SSD 네트웍과 YOLO v1 네트웍의 구성을 보자.
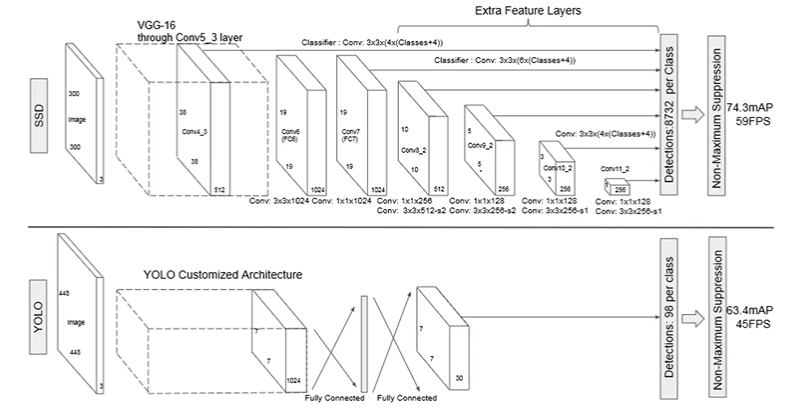
SSD
원본이미지: 인풋으로 들어가는 이미지이다.
- size: 300 X 300 또는 512 X 512
Backbone: 피처맵을 만드는 CNN모델, 논문에선 VGG-16을 사용했지만 ResNet, Inception 등 다양하다. 피처맵에서는 서로 다른 크기의 피처맵, 다른 위치의 앵커박스 각각에서 Object Detect 를 할 수 있는 앵커박스(Default box) 정보를 만들어 다음 네트워크로 전달한다.
- input: 300 X 300 또는 512 X 512 이미지
- output: Feature map (Conv4_3, Conv6, Conv7, Conv8_2, Conv9_2, Conv10_2, Conv11_2)
각 앵커박스는 어떻게 학습시킬까?
1. 각 피처맵 별로 Conv 연산을 한다. (3X3(4X(Classes + 4)) -> 3by3으로, 하나의 위치에서 4개의 앵커박스가 존재하며, 개별 anchor 박스는 클래스 명과 좌표값 정보를 전달한다. (주의: 38X38 피처맵에서 3X3 연산을 수행한다는 것.)
-
모든 피처맵 별로, 앵커박스 별로 Conv 연산한 값을 보내면 8732 개가 모이게 된다.
-
많은 박스를 추려내기 위해 개별 오브젝트별로 Detect 된 것 중 가장 높은 것 하나만 추린다. (Non-Maximum supression, NMS)
2에서는 어떻게 box 의 수가 3732개일까?
Conv 연산의 크기는 3X3 고정이라 할 때, 각 피처맵 사이즈가 38, 19, 10, 5, 3, 1이라고 하면
38X38X4 + 19X19X6 + 10X10X6 + 5X5X6 + 3X3X4 + 1X1X4 = 8732 이다. 뒤에 붙는 4, 6 숫자는 각 point 에서 앵커박스의 수이다.
38X38X4 개의 박스에서의 연산을 내부적으로 보자.
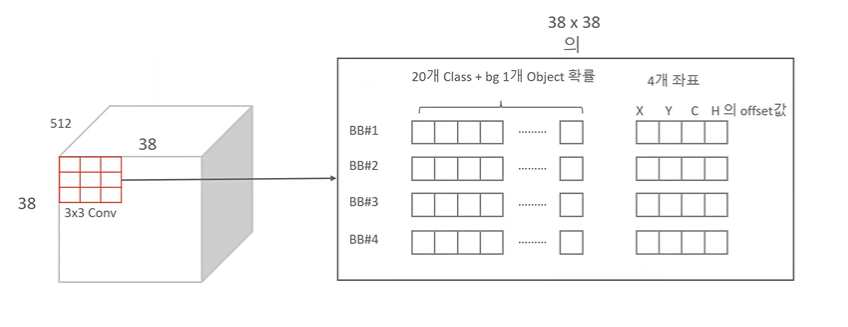
- 3X3 Conv 연산이므로 38, 38 번 움직이며(Point가 된다) 아래를 계산한다.
- 각 point 에서 박스 4개를 가진다. (행 4개)
- 각 행의 열에서는 다음과 같은 정보를 가진다.
- Pascal VOC 의 경우 20개 클래스이므로, 20개 클래스 + 1개 background 중 어디에 속하는지의 확률과 (21개의 Softmax 확률)
- 4개의 좌표 열 추가로.
✅ Multi Scale Feature Map과 anchor box 효과
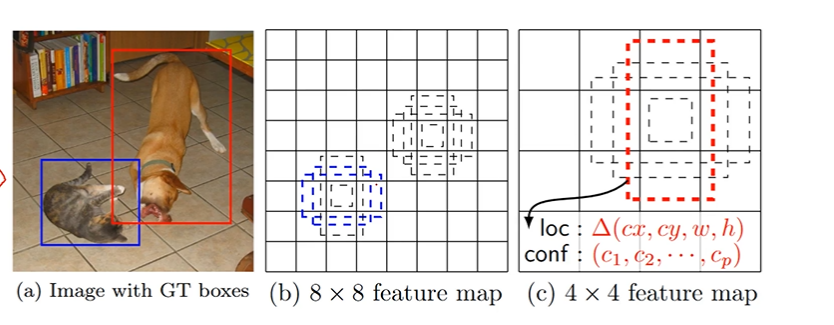
- 8X8 피처맵에서는 파란색만 정답으로 인정할 수 있다. (GT와 matching 된 앵커박스가 존재)
- 4X4 피처맵에서는 빨간색을 정답으로 인정할 수 있다. (GT와 matching 된 앵커박스가 존재)
- 따라서 Multi Scale Feature Map 내에서 Anchor box가 꼭 필요하다 할 수 있다.
- anchor box 는 어떤 역할을 하느냐? 이 정보를 기억하고 있다가 a과 같은 피처맵이 들어왔을 때 좌표, label 을 예측한다.
🤔 anchor box 가 기억하는 좌표는 자신 좌표가 아닌 자신 박스와 매칭되었을 때 GT와의 offset 을 최적으로 맞춰나가기 위한 좌표이다. 따라서 이동좌표가 필요.
SSD Training
matching 전략
SSD는 앵커박스가 분류도, 회귀도 모두 수행한다고 했다. bounding box 와 겹치는 IOU가 0.5 이상인 Default Anchor box 의 분류, 회귀의 최적화 하급을 수행한다.
Loss fuction
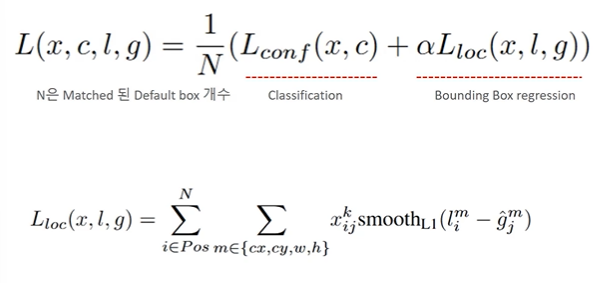
- 회귀의 경우 GT box 와 Defulat box 의 각 센터값이 가로 세로 offset 을 최소화할 수 있도록 학습한다.
Performance

- 성능을 보면 Data Aug. 가 필수적인 것을 확인할 수 있다.
- Ratio {1/2, 2} {1/3, 3} 을 모두 포함하는 것이 좋다는 것이 확인되었다
- atrous VGG 16 을 포함하는 것이 '살짝' 더 낫다.
Data Aug.
one-stage 의 경우 작은 object 를 Detect 하기 어려운 문제가 있다. 이러한 문제는 Data augmentation 으로 해결할 수 있다.
- GT object 와 IOI가 0.1, 0.3, 0.5, 0.7, 0.9가 되도록 object 이미지를 잘라냄
- 잘라낸 이미지를 랜덤하게 샘플링
- 샘플 이미지는 0.1-1사이로, ratio 는 1/2-2 사이로 크기를 맞추고
- 개별 이미지를 300X300 으로 고정. 50%는 flip.
