
SSD 논문의 시초인 SSD: Single Shot MultiBox Detector 논문을 읽고 정리하고, 생각을 써보자. SSD가 등장하기 이전의 Object Detection tasks 에서는 two-stage detector 가 성능상의 이유로 주로 사용되고 있었는데, 결국은 2단계라고 하는 RPN 과 detector 의 과정을 거치면서 자연스레 속도가 느려진다는 단점을 여전히 않고 있었다. one-stage detector 인 YOLO v1이 SSD 논문 이전에 등장해서 속도를 줄여놨지만 YOLO의 경우 mAP 성능상의 문제가 있었다. 따라서 mAP와 detection 속도는 언제나 한번에 잡기 힘든 두마리 토끼같은 존재였는데 SSD가 등장하여 두가지 모두에서 performance 향상을 가져오게 된다. 확인해보자.
Abastract.
SSD 는 proposal generation 을 삭제하고 추가적인 pixel, feature 단계에서의 resampling 도 삭제하여 이 계산을 단일한 네트워크에 모두 포함시킨 모델이다.
이 방법을 적용시킴으로써 SSD는 proposal step 을 적용했을 때만큼 좋은 성능과 더 빠른 예측시간을 이뤄냈다.
- 300 X 300 input 에서 -> 74.3 mAP, 59 FPS
- 512 X 512 input 에서 -> 76.9 mAP (Faster RCNN SOTA 를 넘어섬)
코드는 여기에서 확인할 수 있다.
1. Introduction
SSD 와 이전 RCNN 계열 모델들과의 차이점은
- first deep network does not resample pixels or features for bounding box hypotheses
- 그러면서도 성능 유지이다.
bb 가정을 하지 않고, 픽셀이나 피처 상에서 resample 을 하지 않고 얻는 시간적 이점은 VOC2007 데이터에서 59FPS 로 mAP 74.3 을 달성했다는 것에 있다. (기존 FASTER RCNN 7FPS, mAP 73.2)
속도의 차이는
1. bounding box proposals
2. pixel, feature resampling stage
를 삭제하는 것에서 온다.
추가적으로 detection 성능을 더 끌어올리기 위해 작은 CNN 필터를 추가했다. 작은 CNN 필터는 오브젝트 카테고리 & offsets 를 예측하는데 도움을 주었다. 따라서 다른 각각의 필터에 / 다른 각각의 ratio detections 을 적용시켜 / 마지막 네트웍에서 계산하게 된다. 정리하자면 다음과 같다.
- SSD 는 같은 one-stage detector 계열에서의 먼저 제시된 YOLO v1 보다 빠르다, 그리고 Faster R-CNN 의 two-stage 계열보다 더 정확하다
- 핵심은 피처맵에 작은 CNN 필터를 적용하여 고정된 default bounding boxes 마다 category socres & box offsets 를 예측하는 것이다
- 성능을 높이기 위해서 피처맵의 사이즈를 다르게 하여 다른 스케일의 예측을 만들어낸다.
- PASCAL VOC, COCO, ILSVRC 에 SOTA 달성! (논문 발표 기준)
2. The Single Shot Detector (SSD)
2.1 Model
모델 전체를 통틀어서 중요한 부분은 다음과 같다.
➡️ Multi-scale feature maps for detection
: base network 뒤에 conv feature layers 부분이다. 가면 갈수록 이미지의 사이즈를 줄여가며, 다양한 스케일 상에서의 예측을 가능하게 하는 중요한 부분이다.
➡️ Convolutional predictors for detection
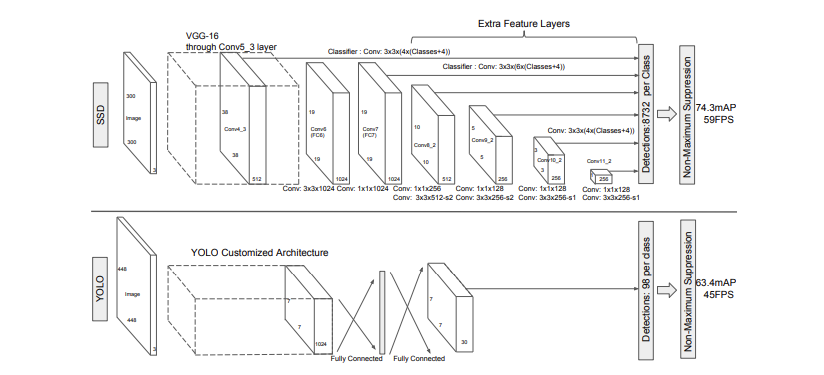
: 각각의 feature layer 들은 convolutional filter들을 활용해 고정된 set를 만들게 된다. 만약 feature layer size m X n with p 채널이 있다면, 3 X 3 X p 의 작은 커널 크기가 예측을 만들어내는 단위가 된다. (커널이 m X n 사이즈에 적용된다.)
- 예측에는 category 와 offset 을 예측하게 된다.
- offset 이란 각 feature map 내에서 bounding box 와 default box 의 상대적인 거리이다
➡️ Default boxes and aspect ratios
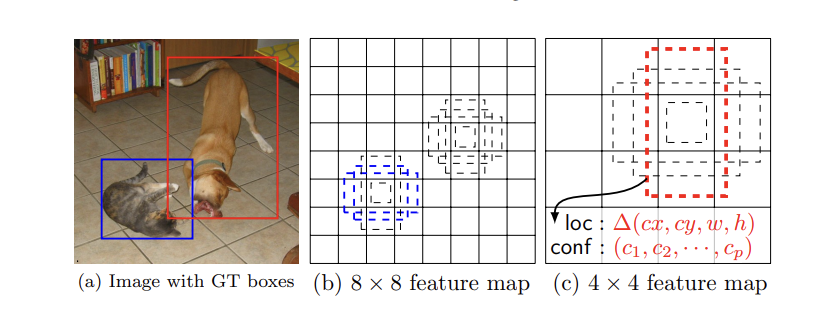
그렇다면 Defualt boxes 가 무엇이냐? 논문의 저자들이 각 피처맵 셀과 매핑한 default 인 bounding boxes 로 이해하면 된다. 이 셀마다 있는 default boxes 마다 offset 과, class scores 를 측정한다고 생각하면 된다. 따라서 그 위치에서 box k개를 설정할 때(각 셀에서 설정한 k의 개수는 조금씩 다를 수 있다.), 클래스의 수가 c개이고 offset 정보가 4이므로 피처맵의 한 셀에선 (c+4) X k 가 outputs 이 되고, m X n feature map 으로 모든 셀로 확장하면 (c+4)kmn outputs 이 된다. (사실 default box 는 Faster R-CNN의 anchor box 와 다를게 없다고 고백하고 있으나 다른 resolutions 의 피처맵에 적용했다며 차이를 두고있다..ㅎㅎ) 다른 사이즈의 피처맵에 default box 를 적용하니 효과적인 분리가 가능해진다. 사진을 참고하자!
2.2 Training
