이번엔 OpenCV 가 아닌 Tensorflow Hub 에서 모델을 가져와보자.
해당 모델들은 https://tfhub.dev/ 에서 확인할 수 있다. 사이트를 들어가보면, 도메인에 맞는 다양한 모델들을 확인할 수가 있다.
ssd 모델을 검색해서 아무거나 들어가보면
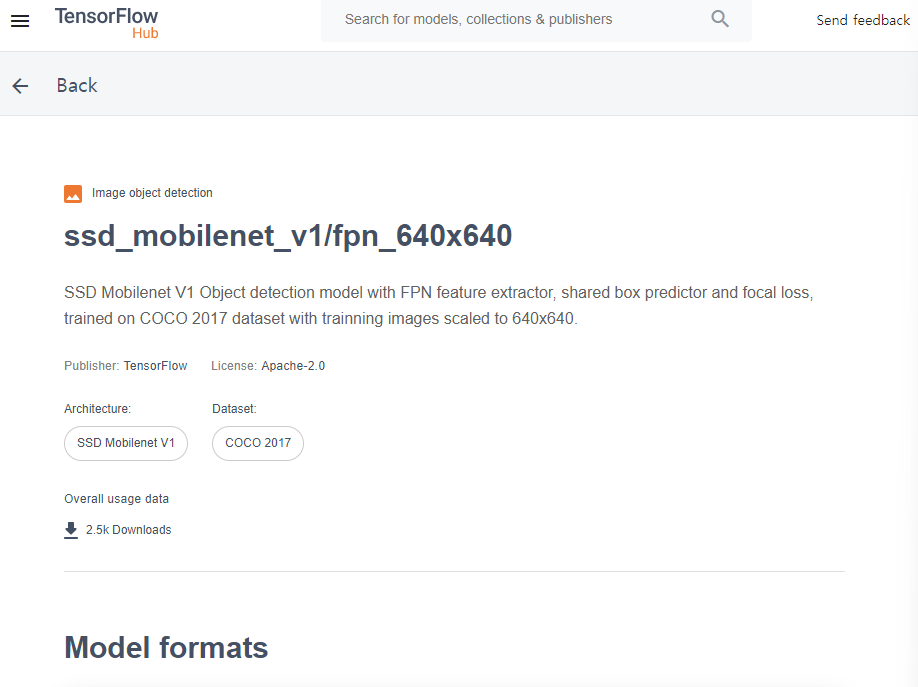
이렇게 모델 정보 (input output shape)와 모델 사용법이 적혀있는 것을 확인할 수 있다!
✅ 라이브러리 임포트
tfhub 을 이용하기 위해선 tensorflow_hub 를 임포트해줘야 한다.
import tensorflow as tf
#tensorflow_hub import 수행.
import tensorflow_hub as hub
import matplotlib.pyplot as plt✅ TF Hub 에서 SSD Inference 모델 다운로드 후 Inference 수행
TF Hub 를 둘러보며 사용하고자 하는 모델을 찾자. 나의 경우 Object Detection 카테고리에 들어가면 나오는 ssd_mobilenet_v2 를 이용했고, 해당 링크 (https://tfhub.dev/tensorflow/ssd_mobilenet_v2/2) 를 타고 들어가보면 URL 을 바로 복사하여 사용할 수 있게 되어있다.
- 다운로드는
hub.load(URL)로 한다. - 입력 이미지로 numpy array, tensor 모두 가능하나
tf.uint8이 필요하다 - 또한 4차원이어야 한다. 이러한 정보는 해당 페이지의 Input 에 보면 명시되어 이싿

# https://tfhub.dev/ 에서 ssd 로 해당 pretrained 모델의 URL 가져옴.
module_handle = "https://tfhub.dev/tensorflow/ssd_mobilenet_v2/2"
detector_model = hub.load(module_handle)
import cv2
import numpy as np
import time
# 1. numpy array 로 가져오는 경우 + 4차원 변경
img_array_np = cv2.imread('/content/data/beatles01.jpg')
img_array = img_array_np[np.newaxis, ...]
print(img_array_np.shape, img_array.shape)
start_time = time.time()
# image를 detector_model에 인자로 입력하여 inference 수행.
result = detector_model(img_array)
# 2. tensor 로 가져오는 경우 + tf.uint8 변경 + 4차원 변경
img_tensor = tf.convert_to_tensor(img_array_np, dtype=tf.uint8)[tf.newaxis, ...]
start_time = time.time()
# image를 detector_model에 인자로 입력하여 inference 수행.
result = detector_model(img_tensor)둘 모두 시간을 찍어보면 0.04-0.05로 40, 50ms 안에 처리가 되는 것을 확인할 수 있다.
print(result) 하여 결과를 출력하면 다음과 같다.
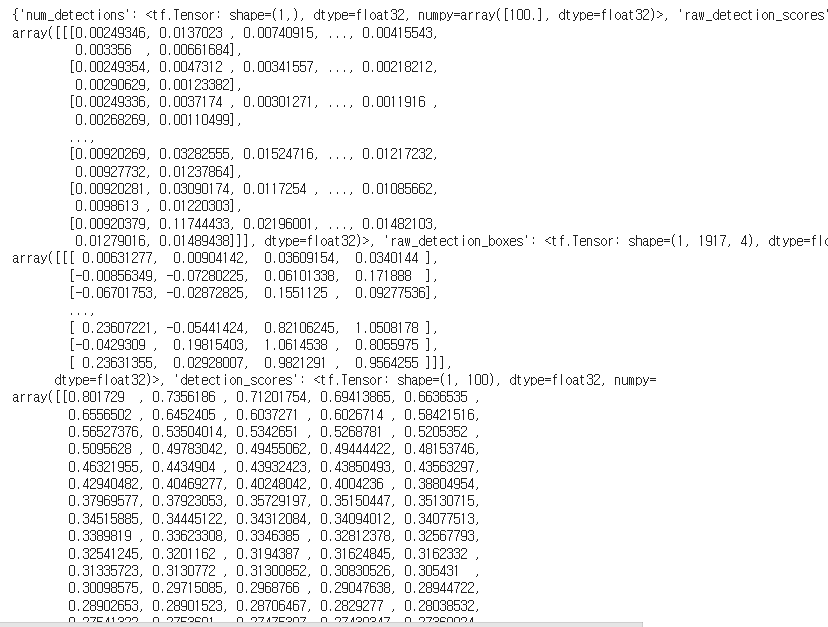
- 딕셔너리 형태로 반환된다
- 각 키들을 확인해보자.
print(result.keys())
# detect 결과는 100개를 기본으로 Detect 함(즉 Detect된 오브젝트는 무조건 100개. 그래서 tensor(array)는 100개 단위)
print(result['detection_boxes'].shape, result['detection_classes'].shape, result['num_detections'].shape, result['detection_scores'].shape)아래와 같은 결과를 반환한다.
dict_keys(['num_detections', 'raw_detection_scores', 'raw_detection_boxes', 'detection_scores', 'detection_classes', 'detection_boxes', 'detection_multiclass_scores', 'detection_anchor_indices'])
(1, 100, 4) (1, 100) (1,) (1, 100)- detection boxes는 어떻게든 100개를 맞추도록 되어있다. (그러다보니 score가 낮은 박스들도 많다.) 1장, 100개, 4개 정보를 의미
- num_detections 는 이미지 수
- detection scores 는 해당하는 점수이다.
✅ Inference 결과를 이미지로 시각화
이제 result 에 담긴 정보를 이미지로 띄워주자. 사용하기 편하도록 numpy array 로 결과를 바꿔준다. key 는 그대로 두고 해당하는 value 값들만 numpy 로 바꿔주자.
# result내의 value들을 모두 numpy로 변환.
result = {key:value.numpy() for key,value in result.items()}# 1부터 91까지의 COCO Class id 매핑.
labels_to_names = {1:'person',2:'bicycle',3:'car',4:'motorcycle',5:'airplane',6:'bus',7:'train',8:'truck',9:'boat',10:'traffic light',
11:'fire hydrant',12:'street sign',13:'stop sign',14:'parking meter',15:'bench',16:'bird',17:'cat',18:'dog',19:'horse',20:'sheep',
21:'cow',22:'elephant',23:'bear',24:'zebra',25:'giraffe',26:'hat',27:'backpack',28:'umbrella',29:'shoe',30:'eye glasses',
31:'handbag',32:'tie',33:'suitcase',34:'frisbee',35:'skis',36:'snowboard',37:'sports ball',38:'kite',39:'baseball bat',40:'baseball glove',
41:'skateboard',42:'surfboard',43:'tennis racket',44:'bottle',45:'plate',46:'wine glass',47:'cup',48:'fork',49:'knife',50:'spoon',
51:'bowl',52:'banana',53:'apple',54:'sandwich',55:'orange',56:'broccoli',57:'carrot',58:'hot dog',59:'pizza',60:'donut',
61:'cake',62:'chair',63:'couch',64:'potted plant',65:'bed',66:'mirror',67:'dining table',68:'window',69:'desk',70:'toilet',
71:'door',72:'tv',73:'laptop',74:'mouse',75:'remote',76:'keyboard',77:'cell phone',78:'microwave',79:'oven',80:'toaster',
81:'sink',82:'refrigerator',83:'blender',84:'book',85:'clock',86:'vase',87:'scissors',88:'teddy bear',89:'hair drier',90:'toothbrush',
91:'hair brush'}키 매핑까지 끝냈다면 익숙한 함수를 거의 변함없이 사용하면 된다. 달라진 점은
- numpy array -> tensor 로 변환, tf.uint8, tf.newaxis 사용
- 결과는 다시 numpy array 로 반환 (딕셔너리 구조)
- result['detection_scores'], ['detection_boxes'], ['detection_classes'] 이용. 인덱싱은 [0, i]
- 0은 이미지 0번을 뜻하며 i는 object 번호임. 100개
import time
def get_detected_img(model, img_array, score_threshold, object_show_count=100, is_print=True):
# scaling된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
height = img_array.shape[0]
width = img_array.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img_array.copy()
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# cv2로 만들어진 numpy image array를 tensor로 변환
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.uint8)[tf.newaxis, ...]
#img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)[tf.newaxis, ...]
# ssd+mobilenet v2 모델을 다운로드 한 뒤 inference 수행.
start_time = time.time()
result = model(img_tensor)
# result 내부의 value를 numpy 로 변환.
result = {key:value.numpy() for key,value in result.items()}
# detected 된 object들을 iteration 하면서 정보 추출. detect된 object의 갯수는 100개
for i in range(min(result['detection_scores'][0].shape[0], object_show_count)):
# detection score를 iteration시 마다 높은 순으로 추출하고 SCORE_THRESHOLD보다 낮으면 loop 중단.
score = result['detection_scores'][0, i]
if score < score_threshold:
break
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
box = result['detection_boxes'][0, i]
''' **** 주의 ******
box는 ymin, xmin, ymax, xmax 순서로 되어 있음. '''
left = box[1] * width
top = box[0] * height
right = box[3] * width
bottom = box[2] * height
# class id 추출하고 class 명으로 매핑
class_id = result['detection_classes'][0, i]
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
if is_print:
print('Detection 수행시간:',round(time.time() - start_time, 2),"초")
return draw_img여러가지 사진으로 테스트해보면 알겠지만, 수행시간은 짧으나 성능이 그렇게 만족스럽진 못하다는 것을 확인할 수 있었다. 불필요한 것을 잡는 문제..
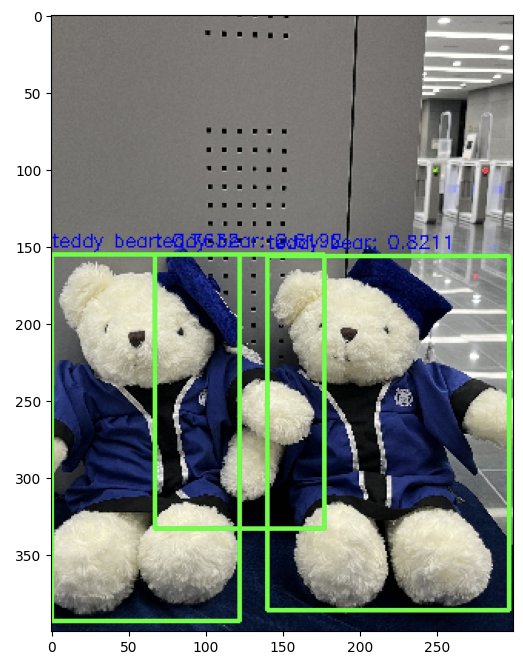
정리
빠르고 성능 좋다고 (그 당시에 자랑했던) SSD 논문을 가지고 실제로 Inference 한 결과 빠른 건 체감이 가능했으나 (CPU 환경에서도 속도가 느리지 않았다) 성능 자체는 Faster RCNN 과 비슷하거나 좋지 못했다. 특히나 잡지 말아야 할 Object 를 불필요하게 중복으로 잡는 문제가 있어서.. 더 최신의 YOLO를 공부할 이유가 생긴 거 같다 ㅎㅎ
