YOLO version
✅ One Stage Detector
- YOLO v1, 2015.06 (150fps)
- SSD, 2015.12 (YOLO v1 의 떨어지는 성능을 잡은 모델이다. 후에 YOLO v2가 등장하는 계기가 되기도.)
- YOLO v2, 2016.12 (SSD와 대등한 수행성능, 시간도 더 빨라짐)
- RetinaNet, 2017.08 (성능은 더 높이고, 시간은 조금 떨어짐) -> Feature Pyramid Network
- YOLO v3, 2018.04 (이후로 YOLO v3 를 압도할만한 모델이 잘 안나옴)
- EfficientDet, 2019.11 (하드웨어의 향상;v100, YOLO v3보다 좋은 성능과 시간)
- YOLO v4, 2020.04 (v3보다도 진화.)
✅ Darknet 기반의 YOLO
YOLO의 경우 1저자가 만든 C로 작성된 Deep learning Framework 에서 탄생한다. 이 프레임워크의 이름이, Darknet이다. CUDA 와 인터페이스를 제공하도록.

✅ YOLO Version
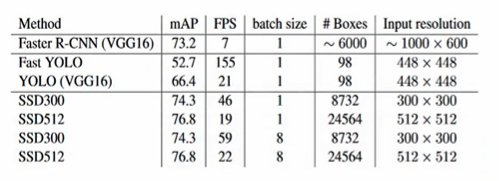
- V1: 빠른 Detection 시간, 낮은 정확도
- V2: 수행시간과 성능 모두 개선. SSD에 비해 작은 Object 성능에 대해선 저하.
- V3: V2 대비 수행 시간은 조금 느리다는 문제가 있으나, 성능은 대폭 개선되었다.
- V4: V3 대비 수행 시간은 약간 향상되었고, 성능은 대폭 개선되었다.
YOLO -V1
Yolo V1은 입력이미지를 S X S 그리드로 나누고,(ex. 7X7) 각 그리드 셀이 하나의 Object 에 대한 Detection 을 수행하게 된다.

- 하나의 셀이 하나의 Object Detect 만 수행하므로
- 큰 Object 는 인식되지 못하거나
- 하나의 셀 안에 여러 Object 가 있어도 딱 1개만 잡아내는 문제
가 존재한다.
✅ 네트웍 및 Prediction 값
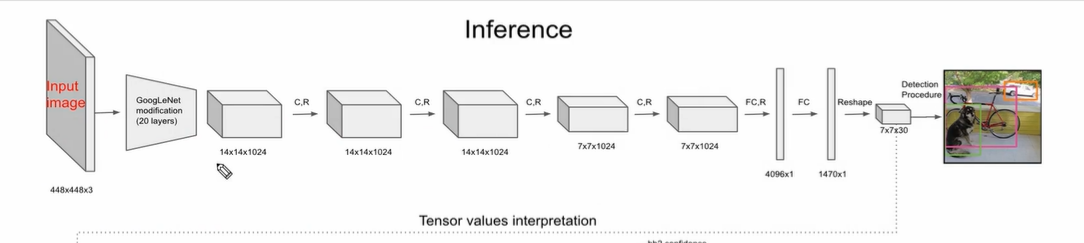
- backbone 은 VGG와 유사한 3X3 filter 로만 구성.
- GoogleNet modification 은 Inception 적용된 모듈에 3X3, 1X1, 3X3 을 적용시킨 것을 의미
- 최종적으론 그리드 셀 (7X7) 만큼의 output feature map 을 뽑는다. 7X7X1024 가 이에 해당하는 부분.
- 다음은 Dense layer 로 4096X1
- 다음은 Dropout 으로 1470X1
- Reshape 하여 7X7X30 으로 만들어준다. 30은 아래와 같은 정보를 말한다.
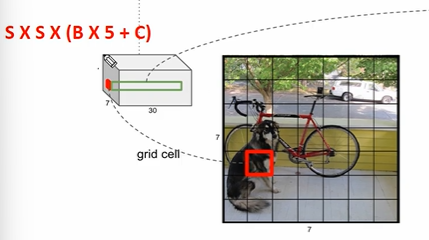
그리드 셀이 예측하는 바운딩박스가 2개일 때, 해당 바운딩박스마다 예측을 수행한다. 개별 바운딩박스별로 5개의 정보
- x, y, w, h : 정규화된 바운딩박스의 중심좌표, 너비 높이 길이
- confidence score : Object 일 확률 X IOU 값
따라서 바운딩박스 1개에 5가지 정보이므로 2개 = 10 가지 정보를 담고, 나머지 20개는 PASCAL VOC 기준 20개의 클래스의 확률을 담는다 따라서 그리드 셀마다 30개의 정보를 담아서 7X7X30 이 된다.
🤔 그런데 바운딩 박스 2개인데 어떤 클래스 확률 20개? 책임 바운딩박스를 정하는 것이고, GT와 IOU가 더 많이 겹치는 바운딩박스를 책임바운딩박스로 하여 해당 바운딩박스에 대한 클래스 확률 20개를 담는다.
YOLO V1 Loss
Yolo v1의 전체적인 식을 보면 다음과 같다.
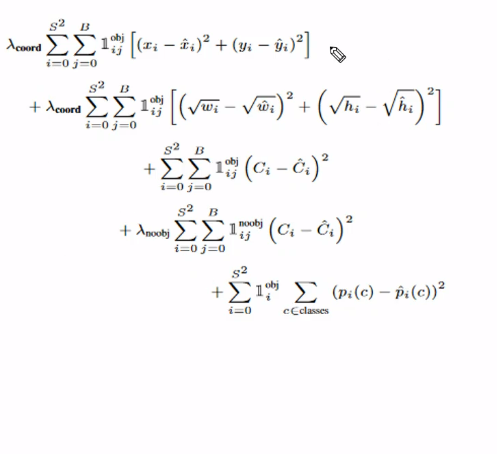
식은 + 4개에 5부분으로 연결되어 있다. 첫 번째 더해지는 값은 bbox의 x, y좌표 loss, 두번째 더해지는 값은 bbox 의 너비, 높이 loss 이다. 3,4 는 confidence score loss, 5는 classification loss 이다. 곱해지는 람다 값은 각각 가중치이다. 1,2 의 경우 5정도의 값을, 4의 경우 0.5 정도의 값을 곱하는 것으로 알려져있다.
✅ bbox 중심 x, y loss
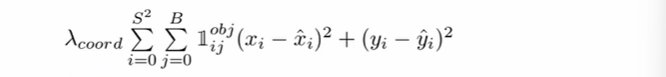
- S는 grid cell (S X S)
- B는 셀마다 bbox 개수 (2개로 설정)
따라서 총 7 X 7 X 2 = 98개의 bbox 가 만들어지고 - : 예측 x 좌표, : GT x좌표
- : 예측 y 좌표, : GT y좌표
오차 제곱을 해주고, 98개의 bbox 중 obj 만 1로 친다. (obj 예측을 책임지는 bbox 만 loss계산에 포함)
✅ bbox 너비, 높이 loss
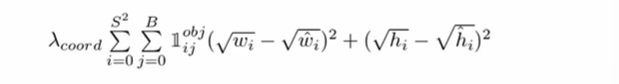
역시나 같은 S, B 값을 가지고
- : 예측 너비 좌표, : GT 너비좌표
- : 예측 높이 좌표, : GT 높이좌표
값을 가진다. 제곱근을 해준 이유는 크기가 큰 오브젝트의 경우 오류가 상대적으로 커지기 때문에 이를 방지하기 위해서이다.
✅ Object Confidence Loss
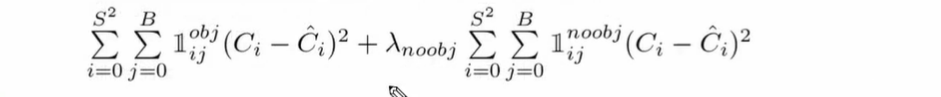
- 예측된 Objedt Confidence score 와 Ground Truth 의 예측 오차
- Object 가 있는 bbox confidence loss 와, Ojbect 가 없어야하는 bbox 의 confidence loss 를 합한다. (해당 ojbect 의 책임 bbox 가 아닌데도 불구하고 confidence 한 것에 대해 loss 를 주겠다는 것)
✅Classification Loss
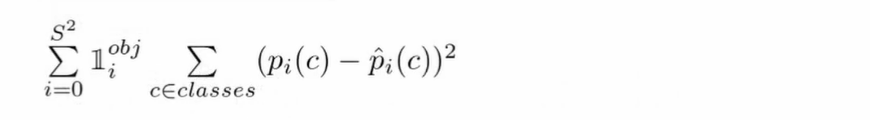
- Object 를 책임지는 bbox 에 대해 class 별로 loss 계산. classificatoin 확률 오차의 제곱으로 계산한다.
YOLO-V1 Detection - NMS
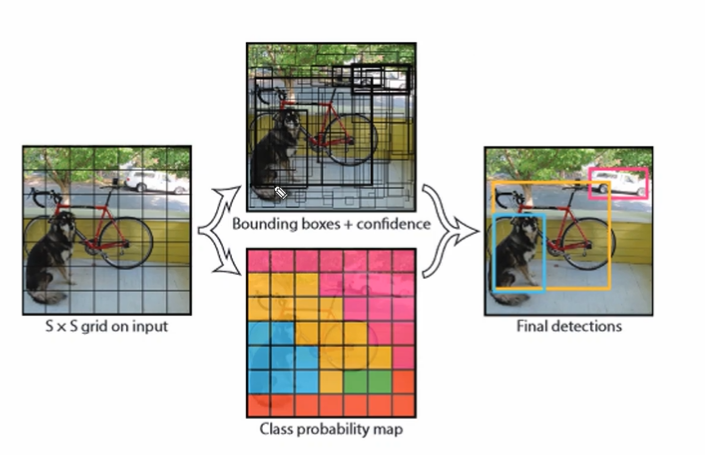
위의 그림처럼, 셀 별로 예측을 수행한다음 NMS 를 통해 필터링하게 된다.
🤔 NMS? Non Max Suppression!
최종 bbox를 예측하는 과정이다.
- 특정 confidence 이하는 제거
- 가장 높은 confidence 순으로 정렬
- 가장 높은 confidence 를 가진 bbox와 IOU와 겹치는 부분이 IOU treshold 보다 큰 bbox 는 모두 제거 (중복되는 bbox를 제거하는 알고리즘)
- 남아있는 bbox 에 대해 3번 step을 반복
그러나..
YOLO V1 은 결정적으로 Detection 시간은 빠르나, Detection 성능이 떨어졌고 특히나 작은 Object 에 대한 성능이 나빴다.
