YOLO v2
YOLO v1, v2, v3 비교
v2에선 v1보다 수행 성능과 시간을 모두 향상시켰다.
- 원본 이미지 크기: 446 X 446 / 416 X 416 / 416 X 416
- Feature Extractor: Inception 변형 / Darknet 19 / Darknet 53
- Grid 당 Anchor box 수: 2개 / 5개 / Ouput Feature Map 당 3개
- Anchor box 크기 결정 방법: - / K-means Clustering / K-means Clustering
- Output Feature Map 크기 : 7X7 / 13X13 / 13, 26, 52 3개의 Feature map 사용
- Feature Map Scaling 기법: - / - / FPN
YOLO v2의 특징으로는 다음과 같은 것들이 있다. (후에서 구체적으로 서술하겠다.)
- Batch normalization
- High Resolution Classifier: Feature Extractor 부분은 freeze 후 classifier 레이어(Conv Head)를 높은 resolution(416X416 => 448X448)으로 fine-tuning 하는 것이다.
- Grid 셀별로 5개의 anchor box 에서 obj Detection
- Direct Location Prediction
- Darknet-19 Classification 모델을 선택했다
- Classification 레이어를 Fully connected 가 아닌 Fully conv 레이어로 변경.
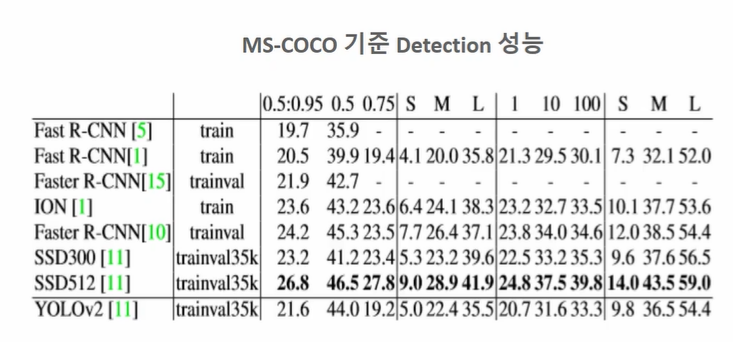
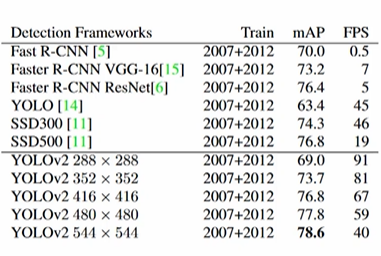
YOLO v2 의 Detection 성능은 다음과 같다.
Yolo -v2 의 특징을 보다 구체적으로 보자.
1. Anchor Box로 1 Cell 에서 여러 개 Object Detection 한다
한 셀에서 5개의 anchor box 들이 만들어지며, 여러개 object Detection 이 가능해진다. 기존에는 그저 2개의 box 만 셀마다 만들었지만 변화된 v2에서는 K-means Klustering 을 통해 이미지 크기와 Shape ratio 에 따른 군집화 분류를 하여 anchor box 크기를 결정하게 된다.
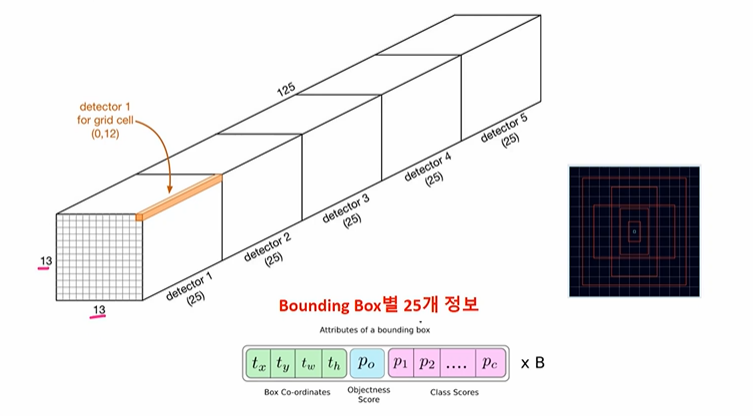
- output feature map 의 사이즈는 13 x 13 이다
- 한 셀에 5개의 anchor box 가 할당이 되는데, 이것이 detector1~5에 각각을 나타낸다
- 그럼 각 detector 의 25개 정보는 무엇인가? box 좌표 4 + Ojbectness socre 1 + class scores 20(PASCAL VOC class 수) 이다.
- 따라서 detect 의 단위가 한 셀이 아닌 한 셀에 속하는 5개의 anchor box 가 좌표 정보도 가지고, class score 도 예측함을 뜻한다. 따라서 anchor box 에 맞는 여러개의 object 를 Detect 할 수 있을 것이다
2. Direct Location Prediction
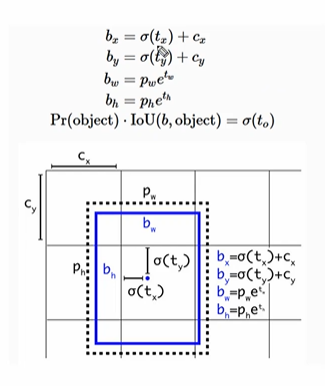
- tx, ty (바운딩박스의 중심점), tw, th 는 모델이 예측하는 offset 값이다
- 실제 예측 bbox 의 중심좌표와 size 는 bx, by, bw, bh 이다. bx, by의 경우 t값에 시그모이드 (0-1)를 적용한 후 셀 자체의 중심좌표를 더하여(C) 계산한다. 따라서 최종 예측 좌표가 bx, by 가 셀을 벗어나지 않도록 할 것이다.
- bw, bh 의 경우 기본 anchor box size 에 X e^tw, e^th 를 하여 각각 구한다.
3. V2 Loss

- v1과 유사한 loss 를 사용한다
- B가 5개로 바뀌게 된다
- Confidence score 에 시그모이드를 한 번 적용하게된다
4. Passthrough module 를 통한 fine grained feature
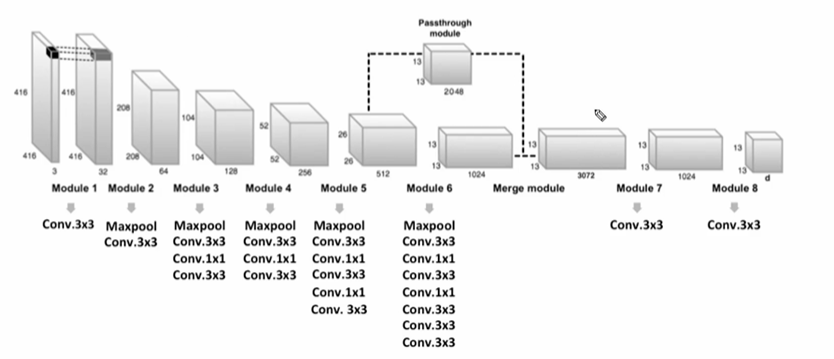
좀 더 작은 오브젝트를 잡아내기 위한 노력이다. 최종적으로 만들어내는 feature map 은 위처럼 굉장히 추상화(feature map size 가 작아질수록 추상화되겠지?) 된 형태인데, 이렇게 될 경우 작은 오브젝트를 잡아내지 못한다. 따라서 이를 해결하기 위해 13X13 으로 넘어가기 전, 26X26에서 13X13를 만들되 채널을 4배하여 연산이 아닌 reshape 만 해주는 과정을 거치게 된다. (13X13X2048 로 정보의 변화 X)
이렇게 만든 passthrough module 의 결과물을 기존 26X26에 conv 연산한 13X13X1024 의 결과와 merge 하게된다. (13X13X2028과)
5. Multi-Scale Training
학습 시 10회 배치마다 입력 이미지 크기를 320부터 608까지 동적으로 변경한 접근이다.
5. Darknet 19 Backbone
VGG-16 아키텍처의 경우 연산량 30.69 BFLOPS 인데 비해 Darknet-19의 경우 5.58 BFPLOPS 로 향상시키고, Accuracy 도 91.2% 로 VGG보다 높았다. 또한 VGG 16의 마지막 fully connected layer 를 제거하고, conv layer 를 적용했다는 점이 Darknet19에서의 변화라 할 수 있다.
YOLO v3
2018년도에 등장한 YOLO v3 는 FPN을 도입함으로써 예측 시간, 예측 정확도를 더욱 향상시켰다. 확인해보자!
FPN? Feature map 의 최상위에서는 추상적이지만 학습이 많이 진행된 Object detection 을 수행하고(기존), 하위에서는 학습이 되지 않았지만 상세한 형태까지 잡는 feature map을 가진다. FPN의 경우 한 단계 상위의 (추상화된) feature map 의 conv 결과와 하위의 feature map 을 합쳐서 feature map 을 추출하고 predict 하게 된다. 이경우 상위 + 하위 feature map이 되어서 추상 + 상세의 효과를 누릴 수 있게된다. (🤔 단순히 합치면 size 가 맞지않으므로 상위 conv 결과에 하위 feature map 사이즈에 맞춰 upsampling 을 한 번 적용한다.)
이를 반복 수행하여 각각의 합쳐진 feature map 마다 predict 을 수행하는 모델이 FPN이다. 이러한 FPN구조를 YOLO v3가 차용한 것!
YOLO v3 의 특징은 다음과 같다.
- FPN 유사 기법 적용, Feature map Output 에서 각각 3개의 서로 다른 크기와 scale 을 가진 anchor box (13, 26, 52 셀마다 3개)로 detection 수행
- Backbone 성능향상 - Darknet 53
- Multi Labels 예측: Sigmoid 기반 logistic classifier 로 개별 Object 의 Multi labels 예측
1. YOLO v3 모델 아키텍쳐
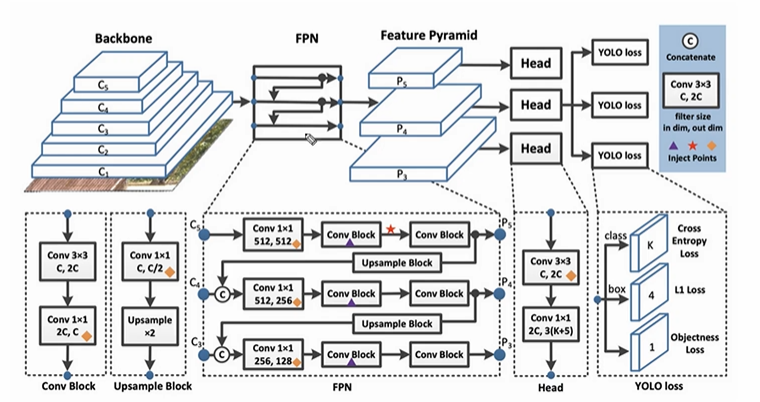
- 이미지에서 feature 맵을 추출한다
- C5, C4, C3 을 가지고 위에서 설명한 방식대로 FPN을 수행한다 (Conv, Upsample, predict)
- 결과적으로 3개의 다른 예측을 만들어낸다 (13X13, 26X26, 52X52)
- 논문에서 제시한 이때 레이어 번호는 각각 82, 94, 106이다
- 각 Head 에선 Conv 연산을 적용 후
- 각각 Loss 를 측정하고 역전파하게된다
- 이때 각 Head 에선 class, box, objectness 에 대한 loss 를 계산한다
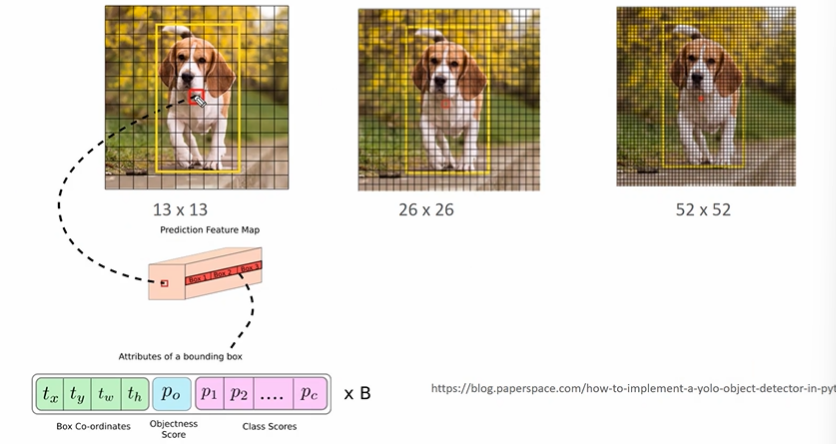
- Output Feature Map의 모습이다 (서로 다른 크기 3개)
- Feature map 13X13 을 예로들면 13 X 13 X 3의 anchor box 와 한 박스당 25의 정보를 갖게될 것이다. (따라서 총 정보의 수는 13 X 13 x 3 X 25 라 할 수 있다)
- class scores 의 경우 PASCAL VOC가 20개, MS COCO 가 80개이므로 각각 25, 85라 생각하자
- 13 X 13은 큰 Obejct 를, 52 X 52 는 작은 Object 를 detect 할 것이다
FPN을 적용함으로써 보다 많은 정보들을 추출한 것이 눈에 띈다.
2. Darknet-53

- Residual block
- BFLOP/s 의 성능이 우수하고 (초당 연산 속도 좋음)
- 152개 층과 같은 acc
- ResNet 보다 적은 FPS (채널 수 최적화)
3. Training
- Multi-scale training
- Augmentation
- Normalization
4. Multi Labels 예측
Softmax 보다 logistic regression 이나 binary classification을 여러번 적용(multi label)하는 것이 성능이 좋다는 것! 선택의 문제를 독립적인 True or False 문제로 변환한 것이 Multi Labels 문제이다.
5. YOLO v3 성능비교
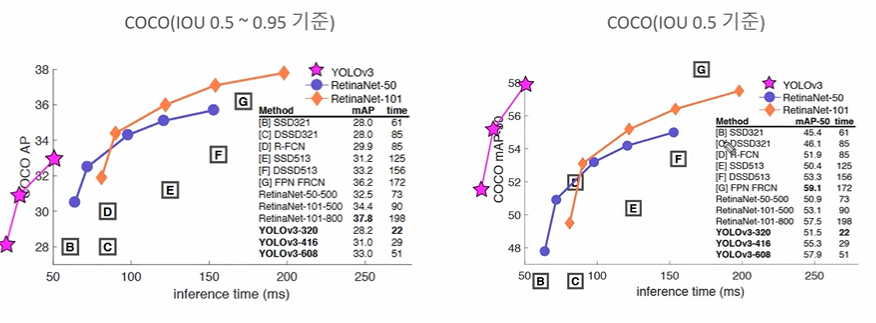
- Inference 속도가 좌표 축을 뚫었다
- Retinanet 의 경우 Inference 하면 큰 차이가 없고
- COCO 의 경우 IOU 0.5에서 예측 성능 역시 거의 같다고 볼 수 있다
