BCEWithLogitLoss vs. MultiLabelSoftMarginLoss
1. BCEWithLogitLoss
BCEWithLogitLosss 는 하나의 single class 에 대해서 BCELoss 와 sigmoid layer 를 합쳐둔 loss 이다. BCELoss 로 하나의 클래스에 대해서 확률 값이 logit 형태로 나오게 되면, logit 을 또다시 인풋으로 하여 sigmoid 에 넣어주게 되면 0과 1 사이의 실수값을 반환하게 된다. BCEWithLogitLoss 는 따라서 BCELoss + sigmoid 라 생각하면 된다.
파이토치 문서를 보면 코드는 다음과 같은데,
torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)이때 두 가지 버전으로 사용할 수 있다.
-
reduction = 'none' 일 경우
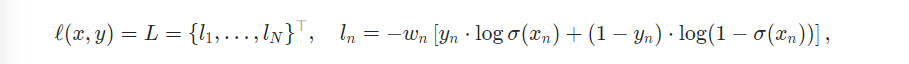
-
reduction = 'mean' 일 경우 (default)

1 의 경우에는 하나의 행에 클래스 수만큼 각각 single class 에 대해서 loss 를 계산하게 되므로 클래스 수만큼 loss 를 반환하게 된다. 그러나 2. 의 경우는 행 자체의 loss 를 원하는 경우로, 클래스 수가 아닌 클래스 수에 따라 평균을 낸 평균 loss 가 도출되게 된다. (배치당 값 1개)
# bsz = 4, 클래스 개수 7이라 할 때 정답
target = torch.randint(0, 2, [4, 7], dtype=torch.float32)
# logit
output = torch.randn([4,7]) # A prediction (logit)다음과 같이 정답값과 logit 예측값을 준다고 했을 때,
- reduction = 'none'인 경우
bce_criterion = torch.nn.BCEWithLogitsLoss(reduction='none')
bce_criterion(output, target)
예측값과 정답값의 차이에 sigmoid 를 씌운 값이고, 따라서 배치사이즈 X class 수 그대로 값이 나오게 된다.
- reduction = 'mean'인 경우
bce_criterion_mean = torch.nn.BCEWithLogitsLoss(reduction = 'mean')
bce_criterion_mean(output, target)
배치사이즈만큼 값들을 모아 평균 내기 때문에 다음과 같이 결과가 나오게 된다.
2. MultiLabelSoftMarginLoss
두번째로 MultiLabelSoftMarginLoss 의 경우 멀티 라벨의 수만큼 평균 낸 값을 loss 로 반환한다. 다시말해, 1과 거의 비슷하지만 각 행의 값을 평균 낸 것과 같다.
코드는 다음과 같은데
torch.nn.MultiLabelSoftMarginLoss(weight=None, size_average=None, reduce=None, reduction='mean')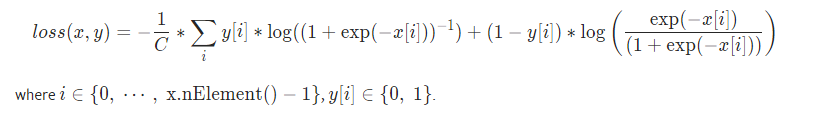
식을 보면 BCEWithLogitLoss 와 같지만 클래스 수인 C로 나눈 것을 확인할 수 있다.
위의 코드에서 output, target 값은 그대로 유지한 채로 criterion 을 multi 로 바꿔서 사용해보면
multi_criterion = nn.MultiLabelSoftMarginLoss(reduction='none')
multi_criterion(output, target)
다음과 같은 값이 찍히는 것을 확인할 수 있다. 이 값들은 아까 4행 7열로 찍힌 bce_criterion 을 행별로 평균 낸 것이다. 정리하자면 BCEWithLogitsLoss(reduction='none') 을 행별로 평균 낸 것 (.mean(axis=-1)) 이 MultiLabelSoftMarginLoss(reduction='none') 인 것이다!
또한 reduction = 'none' 을 사용하지 않고 'mean' 을 쓴다면 두 값이 완전히 같아진다.
Multi-label classification 전처리 모듈
from sklearn.preprocessing import MultiLabelBinarizer
binarizer = MultiLabelBinarizer()
binarizer.fit_transform([(1,2), (3,), (1,3)]) 1행에는 1,2 라벨이 있음을 뜻하며, 2행에는 3 라벨만 있음을 뜻한다. 3행에는 1, 3라벨이 있음을 뜻한다.

결과는 다음과 같이 있으면 1, 없으면 0으로 출력된다.
따라서 fit_transform 안에 이진화 가능한 값들을 넣으면 된다.
예컨대 데이터프레임의 label 열에 가능한 multi-label 들이 있을 때, 다음과 같이 코드로 치면 된다.
labels = binarizer.fit_transform(df['label'].values)
labels 또는


