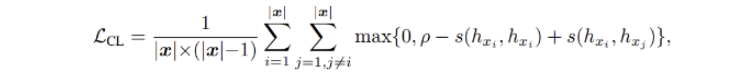
지난 번 글에서 Contrastice loss function 을 뜯어보았으니, 이번에는 현재 task 에 맞게 이를 수정해보자.
목표는
- anchor 을 도입하여 anchor와 anchor+, anchor 와 anchor-와의 cosine similarity 를 계산하는 함수,
- 정확히는 relu(margin - s(anchor, anchor+) + s(anchor, anchor-) 를 계산하는 것이다.
< contrastive loss 함수 (원본) >
def contrastive_loss(self, score_matrix, input_ids):
'''
score_matrix: bsz x seqlen x seqlen
input_ids: bsz x seqlen
'''
bsz, seqlen, _ = score_matrix.size()
gold_score = torch.diagonal(score_matrix, offset=0, dim1=1, dim2=2) # bsz x seqlen
gold_score = torch.unsqueeze(gold_score, -1)
assert gold_score.size() == torch.Size([bsz, seqlen, 1])
difference_matrix = gold_score - score_matrix
assert difference_matrix.size() == torch.Size([bsz, seqlen, seqlen])
loss_matrix = self.margin - difference_matrix # bsz x seqlen x seqlen
loss_matrix = torch.nn.functional.relu(loss_matrix)기존 함수에서는 score_matrix 에 배치 내 문장의 유사도 행렬이 들어오고, input_ids 에 배치 내 문장이 들어온다음, 동일 문장에서의 유사도만 계산하면 되었기에 diagonal 연산을 사용하면 되었지만 이제 그게 필요가 없다. 지금은 anchor 외에 인풋으로 들어올 다른 두 문장 세트 (편향이 없는 / 편향이 있는) 가 필요하며, 따라서 기존에는 문장 세트가 1개가 필요했다면 지금은 3개가 필요하다. 위를 수정하기 위해 일단 마지막 forward 함수의 cosine similarity 를 계산하는 함수로 먼저 가보자.
< forward 함수 (원본) >
# compute cl loss
norm_rep = last_hidden_states / last_hidden_states.norm(dim=2, keepdim=True)
cosine_scores = torch.matmul(norm_rep, norm_rep.transpose(1, 2))
assert cosine_scores.size() == torch.Size([bsz, seqlen, seqlen])
cl_loss = self.contrastive_loss(cosine_scores, input_ids)기존 hidden_representation 하나만 가져와서 계산이 가능했던 코드와는 달리 현재는 계산해야 할 것이 2가지이다. 하나는 앵커와 앵커+의 유사도, 다른 하나는 앵커와 앵커-의 유사도. 또한 이를 계산하기 위해선 L2 norm 으로 표현된 hidden representation 3개가 필요하다. 앵커와, 앵커+, 앵커- 이다. 2가지 유사도를 계산하게 되면 cl_loss 에 들어가야 하는 것은 총 4개의 인자로,
cl_loss(앵커와 앵커+ 의 유사도 행렬, 앵커와 앵커-의 유사도 행렬, 앵커+의 데이터, 앵커-의 데이터) 가 될 것이다. 여기까지 생각해내면 나머지는 loss_function 함수 내에서 쉽게 조작 가능하다. 일단 수정된 forward 함수 내에서의 코드를 보자.
< forward 함수 (목적에 맞게 수정) >
# compute cl loss (기존- anchor 로 가정)
norm_rep_anchor = last_hidden_states_anchor / last_hidden_states_anchor.norm(dim=2, keepdim=True)
# (anchor+)
norm_rep_plus = last_hidden_states_plus / last_hidden_states_plus.norm(dim=2, keepdim=True)
# (anchor-)
norm_rep_minus = last_hidden_states_minus / last_hidden_states_minus.norm(dim=2, keepdim=True)
# anchor 와 anchor+ cosine 유사도 행렬
cosine_scores_plus = torch.matmul(norm_rep_anchor, norm_rep_plus.transpose(1, 2))
assert cosine_scores.size() == torch.Size([bsz, seqlen, seqlen])
# anchor 와 anchor+ cosine 유사도 행렬
cosine_scores_minus = torch.matmul(norm_rep_anchor, norm_rep_minus.transpose(1, 2))
assert cosine_scores.size() == torch.Size([bsz, seqlen, seqlen])
# 기존 유사도 행렬, 데이터였던 것을 => 앵커와 plus 문장의 유사도 행렬과, 앵커와 minus 유사도 행렬로 변화
cl_loss = self.contrastive_loss(cosine_scores_plus, cosine_scores_minus, input_ids_plus, input_ids_minus)이에 맞게 contrastive loss 함수를 수정하자.
- 인자를 4개로 다르게 받았고
- 더이상 diagoanl 계산은 필요가 없음 (자기 자신 토큰 유사도 계산은 필요 X)
- 차이(difference_matrix) 를 기존 자기 자신 토큰 유사도 - 다른 토큰 유사도에서 => 앵커,앵커+ 유사도 - 앵커, 앵커- 유사도로 변경.
< contrastive loss 함수 (원본) >
def contrastive_loss(self, cosine_scores_plus, cosine_scores_minus, input_ids_plus, input_ids_minus):
'''
score_matrix: bsz x seqlen x seqlen
input_ids: bsz x seqlen
'''
bsz, seqlen, _ = score_matrix.size()
# 자기 자신의 유사도는 diagonal 연산으로 쉽게 구했지만 이제 필요가 없다. 주석처리.
# gold_score = torch.diagonal(score_matrix, offset=0, dim1=1, dim2=2) # bsz x seqlen
# gold_score = torch.unsqueeze(gold_score, -1)
# assert gold_score.size() == torch.Size([bsz, seqlen, 1])
# 차이를 기존 자기 자신 토큰 유사도 - 다른 토큰 유사도에서 => 앵커,앵커+ 유사도 - 앵커, 앵커- 유사도로 변경.
# difference_matrix = gold_score - score_matrix
difference_matrix = cosine_scores_plus - cosine_scores_minus
assert difference_matrix.size() == torch.Size([bsz, seqlen, seqlen])
loss_matrix = self.margin - difference_matrix # bsz x seqlen x seqlen
loss_matrix = torch.nn.functional.relu(loss_matrix)