SimCTG Idea
기존에 SimCTG 의 loss function 을 이용해 훈련시키고자 하는 언어모델은 다음과 같았다. SimCTG를 왜 쓰는가? 의 문제.
- SimCTG 는 언어모델링 시에 Contrastive Learning 을 하기위해 끌고온 아이디어이다.
- Anchor 하나를 두고, Anchor 문장과 Anchor+ 문장은 가까이, Anchor- 문장은 멀리 학습시키는 게 목표이다.
- Anchor 문장은 '편향을 일으킬 수 있는 단어가 아예 제거된 문장'일 것이다. 예컨대 '자동차 사고를 낸 사람은 틀림없이 여자다.'라는 문장이 있으면
- Anchor 문장은 '자동차 사고를 낸 [Blank] 는 틀림없이 [Blank] 이다.' 가 될 것이고
- Anchor+ 문장은 '자동차 사고를 낸 사람은 틀림없이 그 사람이다. 가 될 것이며,
- Achor- 문장은 '운전에 미숙한 여자가 자동차 사고를 더 많이 낼 것이다'라는 편향을 근거로 '자동차 사고를 낸 사람은 틀림없이 여자다' 라는 문장이 될 것이다.
- 최종적으로 편향이 있는 문장과 그렇지 않은 문장을 분리하여 학습시키는 것이 목표.
SimCTG 코드 뜯어보기
그렇다면 본격적으로 코드를 뜯어보자.
코드는 깃헙에 올라온 오픈소스 SimCTG/lossfunction.py 파일 을 참조했다.
SimCTGLoss 에 들어간 함수는 init 제외 3개이다.
- build_mask_matrix
- contrastive_loss
- forward
하나씩 보자!
init 함수와 build_mask_matrix 함수 보기
import torch
from torch import nn
from torch.nn import CrossEntropyLoss
train_fct = CrossEntropyLoss()
class SimCTGLoss(nn.Module):
def __init__(self, margin, vocab_size, pad_token_id):
super(SimCTGLoss, self).__init__()
'''
margin: predefined margin to push similarity score away
vocab_size: the vocabulary size of the tokenizer
pad_token_id: indicating which tokens are padding token
'''
self.margin = margin
self.vocab_size = vocab_size
self.pad_token_id = pad_token_id먼저 SimCTGLoss 클래스를 선언하고 필요한 변수를 초기화하는 부분이다.
- margin: 실제 loss 계산에 앞 부분에 위치한 마진값을 의미한다.
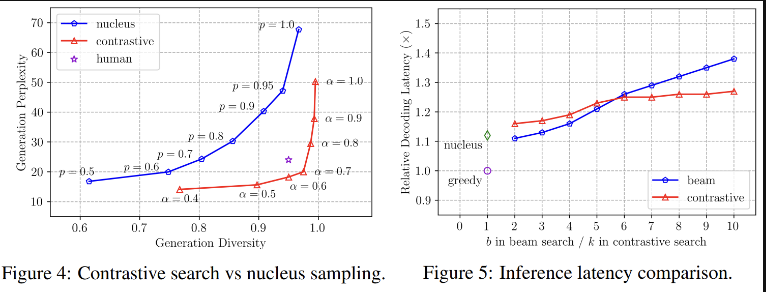
margin 에 대해 조금 더 생각해보자.. 마진이 너무 작으면(=0.5) 왜 (Perplexity 가 낮고, Diversity도 낮으며), 마진이 너무 크면(=1.0) 왜 (Perplexity가 크고, Diversity가 크게) 학습될까?
위의 정의에 따르면, (1) 마진이 너무 큰 경우(=1.0) 는 마진 - = 0으로 상쇄되어 0이 될 것이고, 그러면 온전히 다른 문장 간의 유사도 점수가 페널티가 될 것이다. (2) 마진이 너무 작은 경우(=0.5) 는 마진 - = -0.5 로 loss 가 없다고 판단하거나 있어도 조금, 이라 판단할 것이다. 다시 정리하면, (1)의 경우엔 다른 문장에 대한 페널티를 더 크게 주는 것이고, (따라서 Perplexity와 Diversity 가 클 것이다.) (2)의 경우엔 다른 문장에 대한 페널티를 작게 주는 것이다. (따라서 Perplexity와 Diversity가 작을 것)
이외에도 init 함수에는
- vocab_size: 사전 사이즈와
- pad_token_id: 어떤 토큰이 패딩 토큰인지 표시
하는 변수가 포함되어 있었다. 다음으로 build_mask_matrix 를 보자.
# the part for contrastive loss
def build_mask_matrix(self, seqlen, valid_len_list):
'''
(1) if a sequence of length 4 contains zero padding token (i.e., the valid length is 4),
then the loss padding matrix looks like
[0., 1., 1., 1.],
[1., 0., 1., 1.],
[1., 1., 0., 1.],
[1., 1., 1., 0.]
(2) if a sequence of length 4 contains 1 padding token (i.e., the valid length is 3),
then the loss padding matrix looks like
[0., 1., 1., 0.],
[1., 0., 1., 0.],
[1., 1., 0., 0.],
[0., 0., 0., 0.]
'''
res_list = []
base_mask = torch.ones(seqlen, seqlen) - torch.eye(seqlen, seqlen)
base_mask = base_mask.type(torch.FloatTensor)
bsz = len(valid_len_list)
for i in range(bsz):
one_base_mask = base_mask.clone()
one_valid_len = valid_len_list[i]
one_base_mask[:,one_valid_len:] = 0.
one_base_mask[one_valid_len:, :] = 0.
res_list.append(one_base_mask)
res_mask = torch.stack(res_list, dim = 0)#torch.FloatTensor(res_list)
#print (res_mask)
assert res_mask.size() == torch.Size([bsz, seqlen, seqlen])
return res_mask(1) 은 sequence length = 4, 제로 패딩인 경우 loss padding matrix를 보여준다. (valid len = 4)
(2) 는 sequence length = 3, 1 패딩 토큰일 경우 loss padding matrix 를 보여준다. (valid len = 3)
base_mask 는 (문장길이, 문장길이) 짜리 1로 채워진 행렬을 만들고 왼쪽 위=> 오른쪽 아래 대각선을 0으로 채운 행렬이다.
valid_len_list 각기 다른 문장 길이를 담고 있는 리스트를 돌며,
아까 만든 base_mask 에 행, 열로 valid len 가 넘으면 0으로 채우는 연산을 수행해준다.
one_base_mask[:,one_valid_len:] = 0.
one_base_mask[one_valid_len:, :] = 0.문장마다 이를 저장한 것을 res_mask 에 dim = 0 으로 쌓는다.
contrastive_loss 함수 보기
직접적으로 손실 계산하는 contrastive_loss 는 다음과 같은 인자를 받는다.
def contrastive_loss(self, score_matrix, input_ids):
'''
score_matrix: bsz x seqlen x seqlen
input_ids: bsz x seqlen
'''- score_matrix: bsz x seqlen x seqlen (배치사이즈, 문장최대길이, 문장최대길이)
- input_ids: bsz x seqlen (배치사이즈, 문장최대길이) 를 가지는 input 시퀀스이다.
bsz, seqlen, _ = score_matrix.size()
gold_score = torch.diagonal(score_matrix, offset=0, dim1=1, dim2=2) # bsz x seqlen
gold_score = torch.unsqueeze(gold_score, -1)
assert gold_score.size() == torch.Size([bsz, seqlen, 1])score_matrix 텐서로부터 배치사이즈와 문장길이를 가져온다.
gold_score 텐서를 만들기 위해 score_matrix 로부터 diagonal elements가 추출되는데, diagonal elements 란 여기서 자기 자신 토큰끼리의 유사도를 의미한다. 그리고나서, gold_score 에 추가적인 dimension 1을 준다.
difference_matrix = gold_score - score_matrix
assert difference_matrix.size() == torch.Size([bsz, seqlen, seqlen])difference_matrix 를 계산하기 위한 코드이며, 정확히는 gold_score (자기자신과의 유사도 행렬)과 score_matrix (각 토큰의 모든 쌍의 유사도 행렬) 의 차를 구한다.
loss_matrix = self.margin - difference_matrix # bsz x seqlen x seqlen
loss_matrix = torch.nn.functional.relu(loss_matrix)이제 loss 행렬을 게산하고, margin 에서 아까 구한 차이 행렬을 뺀다. 그러면 어떻게 되냐고?
margin - (gold score: 자신 토큰 유사도 - score_matrix: 다른 토큰 유사도) 를 계산하게 되며, 이 부분이 우리가 봤던 핵심 식이다! margin 은 역시나 positive and negative sample 사이에 얼만큼 최소한 떨어져 있을 지 정해주는 것이라 했다. 여기에 relu 를 한 번 적용시킨 이유는 max(0, 구한 값) 을 구현하기 위함이다! (음수가 되지 않도록) 정리하면, 기본적인 우리가 아는 loss 는 loss_matrix 에 저장된다.
### input mask
input_mask = torch.ones_like(input_ids).type(torch.FloatTensor)
if loss_matrix.is_cuda:
input_mask = input_mask.cuda(loss_matrix.get_device())
input_mask = input_mask.masked_fill(input_ids.eq(self.pad_token_id), 0.0)input mask 는 input_ids 로부터 패딩 토큰을 identify 하기 위해 만들어졌다. 1로 초기화되며, input mask 내에서 패딩 토큰과 상승하는 공간을 0으로 채우는 연산을 수행한다. (input mask 는 배치 내 문장의 유효 토큰는 1, 패딩은 0으로 초기화)
valid_len_list = torch.sum(input_mask, dim=-1).tolist()
loss_mask = self.build_mask_matrix(seqlen, [int(item) for item in valid_len_list])
if score_matrix.is_cuda:
loss_mask = loss_mask.cuda(score_matrix.get_device())
masked_loss_matrix = loss_matrix * loss_maskvalid_len_list 는 배치 내 각 문장의 실제 시퀀스 길이를 구한다. 이후 loss_mask 가 전에 구현한 build_mask_matrix (시퀀스가 들어오면 패딩을 붙여주는 함수)를 통해 만들어지며, 이를 loss_matrix 와 곱해 구한 loss matrix 에서도 마스크가 붙은 loss 행렬을 구현한다. (loss_matrix 에 값이 있더라도, seqlen 에 따라 자르거나 0을 붙인다.) 정리하면, 메인이 되는 loss matrix 에 loss mask 를 곱한다. 그러면 유효 토큰이 아닌 loss 는 0이 된 masked_loss_matrix 가 만들어질 것이다.
loss_matrix = torch.sum(masked_loss_matrix, dim=-1)
assert loss_matrix.size() == input_ids.size()
loss_matrix = loss_matrix * input_mask
cl_loss = torch.sum(loss_matrix) / torch.sum(loss_mask)
return cl_loss마지막 dimension을 가져와 더한다는 것은 시퀀스 내에서 각 토큰별로 loss 를 계산하겠다는 것이며, 이 연산으로 인해 loss_matrix 가 (bsz, seqlen) 가 될 수 있게된다. 따라서 loss_matrix 의 사이즈는 input_ids 의 사이즈와 같을 것이다. 그리고 loss matrix 에 input mask 도 곱한다, 인풋 자체에 패딩처리가 된 단어는 loss 로 고려하지 않겠다는 것.
마지막으로 최종적으로 구한 loss_matrix 를 통해 cl_loss 가 계산될 것이다.
- 모든 loss 값을 더한 것을
- 배치 안의 원래 토큰의 개수로 나눈다. (하나의 토큰상에서 loss 의 평균 계산)
🤔 그런데 문장마다 valid token 은 정해져있기에 padding 의 위치도 같을텐데.. 왜 loss mask 와 input mask 를 분리해둔 것일까?
- input mask 는 loss matrix 와 요소별로 곱하기 위해 사용된다. (아마 shape 를 찍어보면 bsz x seqlen x seqlen 일 것이다.)
- loss mask 는 각 단어별로 loss sum 하고 loss matrix 가 bsz x seqlen 사이즈가 되었을 때 곱해주기 위해 있는 마스크라 생각하면 된다.
forward 함수 보기
def forward(self, last_hidden_states, logits, input_ids, labels):
'''
last_hidden_states: bsz x seqlen x embed_dim
logits: bsz x seqlen x vocab_size
input_ids: bsz x seqlen
labels: bsz x seqlen
'''forward 함수는 기본적으로 hidden state, logits, input_ids, labels 를 가져와 forward pass 하는 함수이다.
bsz, seqlen = input_ids.size()
assert labels.size() == input_ids.size()
assert logits.size() == torch.Size([bsz, seqlen, self.vocab_size])input_ids 로부터 배치사이즈와 시퀀스 길이를 얻고, 1) 라벨과 인풋 사이즈가 같은지 2) logits 이 bsz, seqlen, vocab_size(사전 사이즈) 의 크기를 올바르게 가지고 있는지 검사한다.
# compute mle loss
mle_loss = train_fct(logits.view(-1, self.vocab_size), labels.view(-1))MLE loss 를 먼저 게산하는 코드이다. CrossEntropyLossfunction 으로 계산하며, (train_fct가 그것이다.) predicted logits 와 true labels 간의 차이를 계산한다.
# compute cl loss
norm_rep = last_hidden_states / last_hidden_states.norm(dim=2, keepdim=True)
cosine_scores = torch.matmul(norm_rep, norm_rep.transpose(1, 2))
assert cosine_scores.size() == torch.Size([bsz, seqlen, seqlen])
cl_loss = self.contrastive_loss(cosine_scores, input_ids)norm_rep 은 임베딩 디멘션을 따라 last_hidden_states 를 정규화해주기 위한 코드이다. (L2 정규화를 뜻하며, 이제 A / ||A|| 와 같이 표현할 수 있다.
그 다음, cosine_scores 는 정규화된 norm_rep 행렬과 자기 자신의 transpose 를 곱하는 연산을 수행하며, 한 시퀀스 내에서 토큰간 유사도를 계산하기 위함이라고 생각하면 된다. 위 norm_rep 와 합쳐져서 시퀀스 내에서 'i번째'와 'j번째' 토큰의 코사인 유사도를 계산한다! (만약 코사인 유사도를 쓰고싶지 않다면 여기를 변경하자)
그 다음 계산된 cosine_score는 원 문장과 함께 contrastice_loss 를 계산하기 위해 투입된다.
return mle_loss, cl_loss마지막으로 MLE 와 CL loss 둘 모두를 반환하고, 비율에 따라 둘의 가중치를 조절할 것이다.
