
구체적인 contrastive learning 을 적용한 연구인 fairfil 논문에 대해 리뷰하고자 한다.
Abstract
proposed the first (당시 기준) neural debiasing method for a pretrained sentence encoder.
-
transforms the pretrained encoder outputs into debiased representations via fair filter network.
-
contrastive learning framework (preserves rich semantic information)
결과적으로 성능이 좋은 debias 인코더를 만드는데 성공하였고, post hoc 라고 하는 방법은 retraining 이 필요없게 함.
1. Introduction
문장 인코더로 높은 성능을 낸 ELMo, GPT, BERT 등도 fairness of pretrained text encoders 에는 관심을 받지 못했다.
Fairness 문제는 곧 social bias 문제이며, 민감한 몇 가지 주제들 (성별, 인종, 지역)에 따른 unbalanced model behaviors 를 말한다.
-
measure bias degree of models - word embedding level (Caliskan et al. 2017; Chaloner & Maldon ado 2019; Brunet et al 2019), Word Embedding Association Test(WEAT)
-
Sentence Encoder Association Test (SEAT)
논문 이전에는 그래도 문장 임베딩에 있어서 bias 를 어떻게 '측정'할 것인지에 대한 연구에 그쳤고, debiasing method 라 해봤자 word level method (Bolukbasi et al. 2016) 로 제한되었다.
- 문장 debiasing method 와 관련해서는 Liang et al (2020) 의 Sent-Debias 논문이 있다. (PCA로 biased direction vectors 를 제거) 그러나 문장 임베딩 공간에 대한 선형성 가정, 방향에 있어 학습 데이터 의존 등은 generalization 을 방해하는 요소였다.
따라서, 이 논문에선 neural debiasing method for pretrained sentence encoders 를 제시한다.
- pretrianed encoder 로 fair filter network 를 훈련한다
- filter 라는 것은 인풋은 원래 문장의 임베딩이며, 네트워크를 통과하면 debiased embedding 이 튀어나오는 것을 의미한다
- debiased 임베딩과 이에 상응하는 augmentation (같은 의미이지만 성별이 다른) 사이에 공통된 정보를 최대화하는 학습
- 문장에서 민감한 단어까지 없애기 위하여 debiased 임베딩과 sensitive 단어 임베딩의 사이에 공통된 정보를 최소화하는 학습
2. Preliminaries
Mutual Information (MI) 는 두 변수에 사이에 "정보의 양"에 대한 척도이다. 수학적 정의는 아래와 같다.
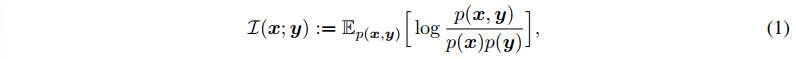
- p(x, y) 는 두 변수에 대한 joint distribution (동시에 등장) 이고 p(x), p(y) 각각은 x, y의 marginal distribution (하나는 고정, 나머지 하나가 등장할 확률) 이다.
- 따라서 각각이 등장할 확률에 비해 그 문장이 동시에 등장하는 확률이 차지하는 비율이 높을수록 mutual information 이 높다고 추정하는 것이나..
- p(x, y) 기대값을 추정하는 것이 어려워 상한과 하한을 추가한 접근이 도입되었다
- InfoNCE (Gutman, 2010) 는 MI의 maximization task 에 적용되어 (하한), 배치 내의 샘플 페어 (x, y) 가 하나씩 주어질 때 아래와 같은 학습 가능한 score function 으로 게산이 가능하다.
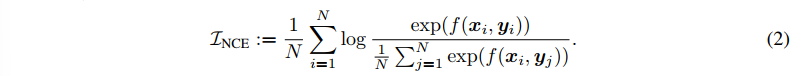
- MI 의 minimizatino task 에 적용되는 contrastive log-ratio upper bound (ClUB, 상한) 로 계산하며 (Chent et al) p(y|x) 라 하는 조건부 확률에서 q(y|x) 라 하는 variational approximation 을 추론하는 것이다.
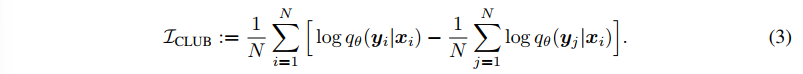
- 🤗🤔왜 InfoNCE가 하한이고 CLUB 이 상한인지 조금 애매하다, 다시 돌아오자!
어쨌든 이 두가지 지표를 문장 인코더에서 편향을 제거하고 의미를 보존하는 estimator 로 사용한다.
3. Method
E() 를 이제부터 pretrianed sentence encoder 라 하자. z = E(x), x는 단어가 모인 시퀀스이다. z 임베딩에서 편향을 제거하기 위해, 이후에 fair filter network f() 를 적용한다. d = f(z). fair filter 을 훈련하기 위해서 3가지 단계가 필요하다.
- 각 인풋 시퀀스 x에 대해 augmented sentence x' (bias direction 은 다르고, 의미는 같은) 을 만든다
- z = f(x), z' = f(x') 사이에 mutual information 을 최대화한다. (InfoNCE, contrastive loss)
- d와 민감 단어 (시퀀스 x 안의)의 mutual informationo 은 최소화한다
1) Data augmentation with Sensitive attributes
T = {D1, D2, .. DK}
- T 는 senstivie topic 을 나타내고 "gender"
- 따라서 {D1, D2} = {'MALE', 'FEMALE'} 이 있을 수 있다.
따라서 단어 w가 주어질 때, 그 단어가 w(boy) = Dk(male)에 해당이 된다면, 그 단어는 언제나 다른 민감 단어 u(girl) = Dj(female)로 바꿀 수 있다고 보았다.
위의 정의에 따라 시퀀스 x로부터 x' 를 만들었고, 이는 bias direction 만 다르고 같은 의미를 가진 문장이다.

2) Contrastive learning framework
얻은 x' 문장으로 (x, x') 를 sentence pair 로 구성한다. 이제는 fair filter f() 를 훈련시키기 위해 contrastive framework 를 적용할 차레이다. 두 단계로 구성된다.
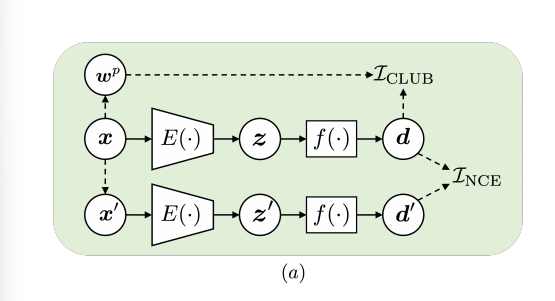
(1) pretrained encoder E() 로 (x, x') => (z, z') 를 얻는다. 이 역시나 다른 bias direction 을 가진 비슷한 의미의 문장일 것이다.
(2) f()에 두 문장을 주고, debiaed embedding 인 (d, d') 를 얻는다. (d, d') 의 mutual information 을 최대화하는 방식으로 두 표현을 의미적으로 유사하게 학습시키는 것이 목표이다.
이때는 maximization task 이므로 InfoNce 를 사용하고, loss 의 하한을 낮추려고 (공통된 정보에 제한을 덜 두도록) 할 것이다. 구체적인 NCE loss 식은 아래와 같다.
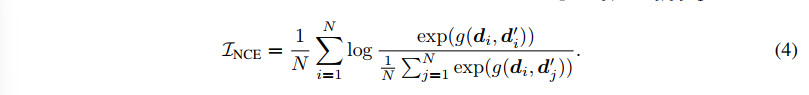
3) Debiasing Regularizer
(d, d') 의 MI를 최대화한다고 모든 편향이 사라지는 것은 아니다. debiased representation d에서 추가적으로 단어에 대한 편향도 없애기 위해, 시퀀스 x에서 민감 단어 w와의 MI를 최소화한다. 이때는 MI 상한을 loss 로 잡아 이를 minimization task 에 적용하고, 따라서 아래 CLUB 식이 도입된다.
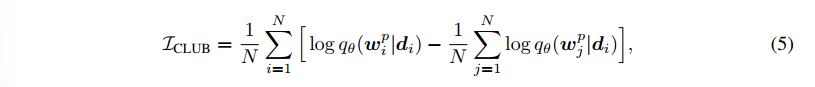
논문의 표현을 빌려 정리하자면,
maximizing NCE loss 로는 enlarge the overlapped area of d and d',
minimizing CLUB loss 로는 shirk the biased shadow parts 가 된다.

5. Expreiments
Bias eval metric
WEAT 의 확장판인 Sentence Encoder Association Test, SEAT 이용. (May et al., 2019)
- WEAT 는 두 attribute words(A,B) 와 두 target words(X,Y) 를 비교하여 bias 를 평가

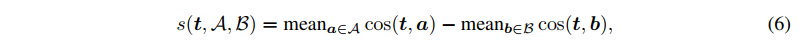
각 단어 임베딩 t(target)를 검사하는 것이며, 그 단어 임베딩 t와 boy, t와 girl 의 유사도가 비슷할수록 (떨어진 거리가 같을수록 fair 하다고 보는 것)
WEAT 는 이걸 문장으로 바꿔서 비교한 것이다.

결국 0에 까까워질수록, 그 임베딩이 fair 하다는 결론을 도출할 수 있다.
Encoders
1) pretrained BERT + directly learn FairFil
2) BERT post tasks: fix parameters of the FairFil => fine tune BERT + FairFil (FairFil no longer update)
downstreamtasks?
1) STT-2: sentiment classification task on the Stanford Sentiment Treebank dataset
2) CoLA: sentiment classification task on the Corpus of Linguistic Acceptability (문법적 정확성 판단)
3) QNLI: binary question answering task on the Question Natural Language Inference dataset
Training of FairFil
- fair filter network 는 FNN + ReLU 의 한 층으로 표현된다.
- InfoNCE 의 score fuction g 는 FNN 2층이다
- CLUB의 variational approximation q 는 multi-variate Gaussian distribution 이다.
Results
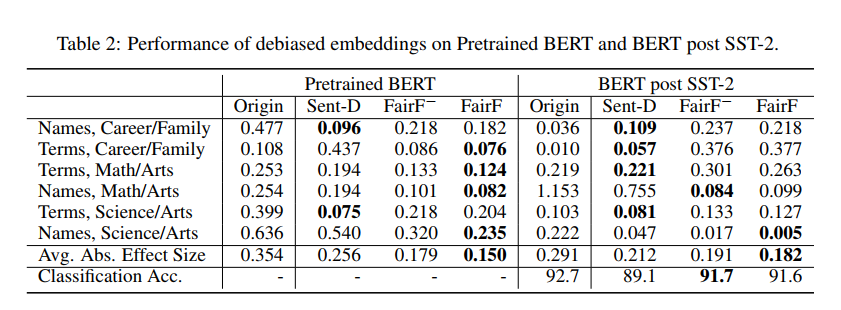
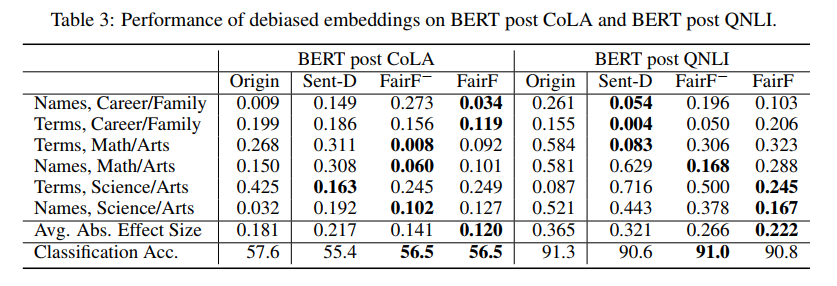
위 두 결과는 debaised embeddings 에 대한 SEAT 평가와 downstream classification accuracy 를 보여준다.
-
비교대상은 original BERT, Sent-Debias, FairFIl-(without debiasing regularizer), FairFil
-
다수의 individual SEAT TEST 에서 더 낮은 bias 를 획득함
-
downstream task 에서 의미적으로 더 나은 성능을 보였는데, 그건 PCA를 활용하여 bias direction 을 제거하는 방식의 Sent-Debias 보다 fairfilter 에서 의미를 보존할 수 있기 때문이다.
Analysis
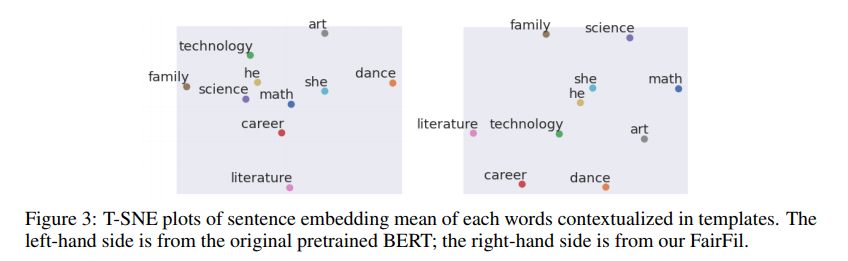
왼쪽보다 오른쪽에서 he, she 와 다른 단어들의 거리가 더 일정해진 것을 확인할 수 있다. 그 전에는 남자는 과학, 기술, 여자는 미술, 춤.
6. Conclusion
debiasing method for large-scale pretrained text encoder neural networks. fair filter takes original embeddigns and outputs the debiased sentence embeddings.
Train fair filter? contrast learning framework. maximize MI between d, d'. minimize MI d, w.
