
"Social-Group-Agnostic Bias Mitigation via the Stereotype Content Model" 논문 리뷰
Abstract
bias mitigation method 는 각 social attribute (gender)마다 social-group-specific word pair 가 필요하다. (man - woman) 이는 연구에 지속적인 제약이었으므로 이 논문에서는 Stereotype Content Model (SCM) 을 제안하고 있음.
SCM 은 stereotyping 의 내용을 이해하는 사회심리학적 모형임. SCM에서 제안하는 것은 Stereotype 의 내용이 두 심리학적인 공간인 'warmth' 와 'competence' 와 연결될 수 있다고 본 것이다. warmth: "genuine" - "fake", competence: "smart" - "stupid" 을 이용해서, LLM에서 편향 완화 연구를 진행했고, group-specific 으로 완화한 것과 비교될 수 있었다. 결과적으로 SCM 기반의 완화 방법이 더욱 좋았다는 것!
1. Introduction
편향성 완화에서 문제는 본질적으로 문제가 '비이론적'이라는 것이었으며, 'bias 를 구성하는 것이 무엇인지 정의하지 못했다는 것'이었다. 결국은 bias 라는 건 사람이 만든 글을 학습시킨 데이터에서 나오는 것으로, bias 를 완화시키기 위해서라면 social psychological theories of stereotyping 연구를 해야한다. => 그래야 피상적인 제거가 아닌 언어 임베딩에서의 편향 제거가 가능해진다.
대부분의 과거의 편향 완화는 group-specific 한 차원의 접근. 이 방법으로는 gender, race 등의 사회 그룹으로 정의된 공간에서의 편향 완화에만 머문다. (atheoritical) 특정 그룹의 편향 완화를 위해 도입된 리소스가 다른 그룹에서도 정확히 적용될 수는, '없다'. (만약 다른 리소스를 잘 준비한다고 하더라도, 모든 그룹에 대해 그렇게 해야하고, 모델의 표현력만 까먹을 뿐이다.)
논문에서 제안하는 것은 social-group-agnostic 한 접근이며, 모델 Stereotype Content Model (SCM)을 가져왔다. SCM은 interpersonal, intergroup intersaction 을 이해하기 위해 사회 심리학에서 도입된 이론적 프레임웍이다. SCM 에서 제안하는 것은 다음과 같다.
- 인간 Stereotype 은 두 주된 인간 인지 공간에서 발생한다
- 하나는 warmth 이며 (trustworthiness, friendliness)
- 다른 하나는 competence 이다. (capability, assertiveness)
- 따라서 다른 사람의 의도에 대한 인지는 warmth 이며, 자신 의도의 표현은 competence 이다.
- 또한 warmth 는 'friends' 와 'foes' 를 가르는 기준이 되며, competence 는 'social group status' 를 나타낸다
따라서 bias 공간을 정의하기 위해 이론적인 social stereotype 의 이해를 가져오고, 그것으로 편향을 완화하는 연구가 이 논문이다.
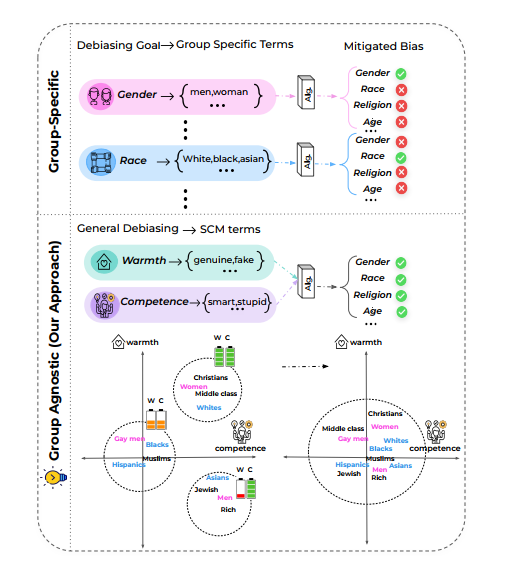
- SCM-base vs. group-specific base 와 비교
- religion, age 등 understudied attributes 에서도 동시에 편향 완화 가능
- 모델의 표현력 유지 입증
등을 논문에서 다룰 예정이다!
2. Background
2.1 Bias Mitigation in Word Embedding
이 논문이 영감을 받은 것은 2019년 발표된 Gonen and Goldberg 의 연구에서다. 이 연구에선 워드임베딩에서 gender bias 가 기존에 생각하던 것보다 더 깊은 문제이며, 단어를 'gender dimension'에 단순히 사영하는 것으로는 피상적인 접근밖에 되지 않는다고 보았다. 따라서 현재 이 논문은 지금 도입하는 이론적 접근이 -심리학적 편향 공간을 제거할 수 있다고 본다.
2.2 Bias Mitigation in Language Models
최근의 흥미로운 연구로는,
- Yang et al. (2023) 이 제안한 "A DEbiasing PromT (ADEPT): 프롬프트 튜닝으로 DPCE 의 성능을 이김
- Yu et al. (2023) 이 제안한 partitioned contrastive gradient unlearning (PCGU): 마스크드 언어모델을 훈련시키기 위한 gray-box 방법으로, 특정 도메인의 편향에 기여하는 가중치에 대해 최적화하는 방법
등이 있다.
2.3 The SCM and Language
결국은 이 논문이 베이스로 깔고 있는 SCM이 중요한데, 이와 관련한 논문들도 나열하고 있다.
- Nicolas et al. (2021): warmth, competence 를 측정하기 위한 딕셔너리 제안
- Cao et al. (2022): 언어 모델의 고정관념을 알아내기 위한 도구 Agency-Belief-Communion (ABC)
- Davani et al. (2021): SCM 을 딕셔너리를 적용하여 소셜 그룹 편향을 양적화, 편향이 warmth, competence 임베딩에서 보여질 수 있음을 보임
- Ungless et al. (2022): SCM 을 이용하여 편향 완화에 도전, 필요한 벤치마크에만 적용.
아마 Davani et al, Ungless et al. 의 논문을 보고 이 논문을 쓸 생각을 하지 않았나..싶다.
3. SCM-Based Bias Mitigation for Static Word Embeddings
중요한 것은 Bias Subspace와 Algorithm 이다.
- Bias subspace: 많은 subspace 중 알고리즘이 타깃하여 작동할 공간
- Algorithm: bias subspace 에서 어떻게 임베딩이 조작될 것인지.
3.1 Identifying a Bias Subspace
전체 임베딩 공간에서 debiasing algorithm 은 bias subspace 에서 작ㅇㅇ할 것이다.
bias concept 단어 쌍으로 이루어진 D = {(d+, d-), ... (d+, d-)} 가 주어질 때, bias subspace 란 전체 행렬 C에서 첫 k개의 주성분을 뜻한다.
3.2 Debiasing Algorithms
W는 단어 사전을 뜻하며, w, w' 등은 임베딩, 편향 제거 후 임베딩을 뜻한다.
✅ Hard Debiasing (HD)
성별과 관련해서, HD는 단어를 gender subspace 에 사영시켜 얻은 공간을 없앤다고 했는데 이 논문에선 그것이 실제로는 옳은 방법이 아니라고 한다. (non-gendered words 와의 거리가 모두 같아지므로 옳은 방법이 아님)
✅ Substraction (Sub)
bias subspace v를 단어 벡터에서 제거.
✅ Linear Projection (LP)
모든 단어 w를 편향 공간에 사영한 후 기존 단어 임베딩에서 이를 제거.
: v는 w를 편향공간 v에 사영해서 얻은 것.
✅ Partial Projection (PP)
LP를 발전시키기 위해, 각 단어의 벡터의 성분(편향 공간에 사영된) 에 따라 projection 을 다양하게 한 것.
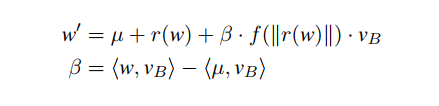
뮤는 단어 임베딩의 평균을 의미하고, r(w) 는 단어 임베딩에서 bias 에 사영시킨 부분을 제외한 것이고, f() 는 smoothing function 으로써 unintended bias 를 제거하고 definitional bias 는 보존한 것이다.
3.3 Static Word Embedding Benchmarks
2가지가 있다.
-
Embedding Coherence Test (ECT): Spearman rank correlation, rank order 와 각 그룹의 professions 평균 임베딩 사이 코사인 유사도를 뜻한다. 만약 ECT = 1 이라는 것은 각 그룹이 직업과 같은 순서로 연관도를 가진다는 것이며, 이때 편향이 없다고 할 수 있다.
-
Embedding Quality Test (EQT): 편향 완화 후 성능을 측정하는 것이다. ratio of unbiased analogies to all analogies 를 뜻한다. 만약 1이라면 가장 이상적이며 낮을수록 편향된 것을 뜻한다.
3.4 Proposed Method
3.5 Results - Bias Reduction
