지난번 살펴보았던 코드는 다음과 같다.
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group = df.groupby('occupation')
# occupation_group.mean() 을 여기서 한번 실행하면 KeyError 발생
df.loc[df['gender'] == 'M', 'gender'] = 0
df.loc[df['gender'] == 'F', 'gender'] = 1
occupation_group.mean()['gender'].sort_values(ascending=False)전에도 살펴보았듯이, 한 행에 대한 boolean 정보는 row 값이다. 따라서 df.loc[ , ] 이렇게 들어가줘야 하는데, 여기서도 그랬다.
성별이 M인 것, 성벌 이렇게 설정을 해서 넣어주면 된다. M 은 0으로, F은 1로 처리를 했다.
그렇게 해서 'gender' 행에서 평균을 낸 것이다. 평균을 낸 것에서 그치지 않고 오름차순 정렬을 해준다. sort_values 를 해주기 위해선 무엇으로? 가 필요하고, 그것이 mean().['gender'] 이다.
11 데이터 합치기
데이터를 합치는 (병합하는) 4가지 방법
✅ Inner join
두 프레임 중 겹치는 부분만 가져와서 병합하겠다는 것이다. 특정 컬럼에 대해서 수행하며, 컬럼에 같은 값이 있으면 가져와 재구성한다. 코드는 다음과 같다.
import pandas as pd
(파일을 가져왔다는 전제 하에)
pd.merge('왼쪽 파일', '오른쪽 파일', on = '가져오고 싶은 컬럼')
inner join 은 그 자체가 디폴트 값이라 더이상 파라미터를 전하지 않는다. 물론 how = 'inner' 을 추가해도 동작은 한다.
price_df = pd.read_csv('downloads/vegetable_price.csv')
quantity_df = pd.read_csv('downloads/vegetable_quantity.csv')
pd.merge(price_df, quantity_df, on = 'Product', how = 'inner')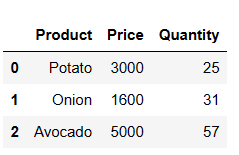
✅ Left outer join
letf outer join 은 왼쪽 부분은 모두 가져와서 병합하겠다는 것이다. 오른쪽도 해당 컬럼에 값이 있으면 가져오고, 없더라도 NaN 으로 처리해 가져온다. 코드는 다음과 같다.
import pandas as pd
(파일을 가져왔다는 전제 하에)
pd.merge('왼쪽 파일', '오른쪽 파일', on = '가져오고 싶은 컬럼', how = 'left')
pd.merge(price_df, quantity_df, on = 'Product', how = 'left')
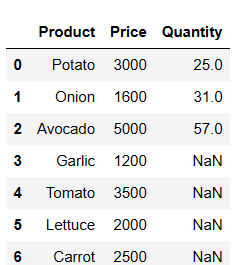
✅ Right outer join
Right outer join 은 오른쪽 부분은 모두 가져와서 병합하겠다는 것이다. 왼쪽도 해당 컬럼에 값이 있으면 가져오고, 없더라도 NaN 으로 처리해 가져온다. 코드는 다음과 같다.
import pandas as pd
(파일을 가져왔다는 전제 하에)
pd.merge('왼쪽 파일', '오른쪽 파일', on = '가져오고 싶은 컬럼', how = 'right')
pd.merge(price_df, quantity_df, on = 'Product', how = 'right')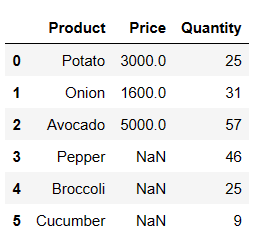
✅ full outer join
full outer join 은 모든 해당 부분을 가져와서 병합하겠다는 것이다.
import pandas as pd
(파일을 가져왔다는 전제 하에)
pd.merge('왼쪽 파일', '오른쪽 파일', on = '가져오고 싶은 컬럼', how = 'outer')
pd.merge(price_df, quantity_df, on = 'Product', how = 'outer')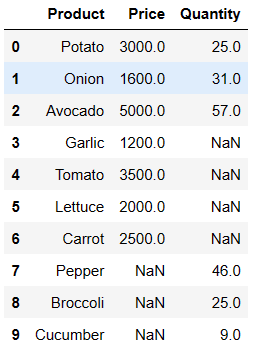
12 박물관이 살아있다
import pandas as pd
museum = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
number = pd.read_csv("data/region_number.csv", dtype={'지역번호': str})
# 여기에 코드를 작성하세요
data = pd.merge(museum, number,on = '지역번호', how = 'left')
datamuseum 이 다루고 싶고 필요한 본 정보 + number 가 매칭이 필요한 부가정보이므로 left outer join 한다.
