
지난주 미팅을 요약하면 다음과 같았다. post 와 bias 문장을 멀게하면 좋을지, 가깝게 하면 좋을지를 연구 주제로 설정하고 이 둘을 비교하면 좋지 않을까 하는 새로운 관점을 생각해봤다.
1. CCPA (증폭 후 contrastive learning, 데이터 만드는 방법)
지금 CCPA 논문을 읽고 생각해볼 수 있는 것은
1. post 와 bias 문장을 멀게 학습시킬 경우
사실 최종적인 목표이긴 하나 CCPA의 아이디어에 따르면 증폭 후 멀게 하는 것이 '더' 멀게 할 수 있을 거란 이야기다. 2번을 잘 보자.
2. post 와 bias 문장을 가깝게 학습시킬 경우
다른 말로하면 non-bias 문장은 post 와 '처음엔' 멀게 학습시키고, 그 다음엔 Contrastive learning 으로 non-bias 문장은 가깝게, pos와 유사도가 높은 non-bias 는 멀게 학습시키는 아이디어어일 것 같다. 2의 경우까지만 수행하면 증폭이라는 것.
구체적으로 어떻게 데이터셋을 얻느냐? CCPA의 아이디어에서 가져온다면
-
데이터 셋을 마련한 다음
-
attribute word list (about gender) 을 준다. 전체 post 문장이 있고, 이 중 아래 att word list 에 해당하는 문장이 있다면 bias 문장이라고 가정한다. (bias 문장이라 설정한다.) 해당 att word 를 person 으로 바꿔 생성한 문장을 non-bias 문장이라 설정한다.
-
🤔 att word list 에 해당한다고 무조건 bias 문장이 아닌 게 문제다. 아니면 pretraining 자체는 post 에서 하고, 편향만 모아둔 데이터셋이 있다면 그걸로 fine-tune 하는 방식으로 가도 좋을 듯.
-
어쨌든 att word 는 다음과 같다.
{MALE, FEMALE}={(man, woman), (boy, girl), (he, she), (father, mother), (son, daughter), (guy, gal), (male, female), (his, her), (himself, herself), (John, Mary)}.
이렇게 post, bias, non-bias 문장셋이 완성된다면 처음엔 post-bias 페어를 가깝게(증폭), 다음엔 post-non bias 페어를 멀게한다. 편향의 증폭은 loss 를 cosine similarity 로 주면 된다.
그다음 contrastive learning 으로 ('더' 가까워진) post-bias 페어는 '더' 멀리 학습하고, post-non bias 페어는 가까이 학습한다.
- 🤔 또다른 질문으로, post-bias 사이가 '더' 멀어진다면 편향된 generation 을 하지않을까?하는 궁금증이 있다. 여전히 표현공간에 남아있는데.. 일단 post와 non bias 문장이 가까워졌으니 평균적으론 줄어들 거 같긴한데, 한 번 편향문장을 출력할 경우 굉장히 radical 한 표현이 나올 수도 있겠다는 생각이 든다.
2. DeCLUTR (contrastive learning for sentence embedding)
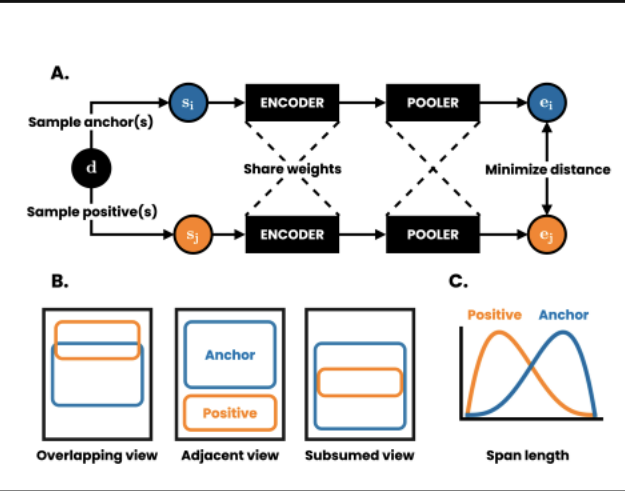
하나의 문서에서 앵커, postive 추출 후 (), Encoder 를 지날 땐 해당 문장을 토큰 단위로 임베딩 => Pooler 을 지날 때 인코딩된 것을 고정길이로 평균하여 문장 당 하나의 임베딩을 얻는다. 후에 contrastive learning.
cross entropy loss 에서 끝나는 것이 아닌 normalized temperature-scale cross entropy loss 를 사용한다.
이정도면 아이디어 정리가 다 된 것 같다.
