
"Prompt Tuning Pushes Farther, Contrastive Learning Pulls Closer: A Two-Stage Approach to Mitigate Social Biases" 논문 리뷰.
Abstract
대부분의 debiasing techniques 는 Counterfactual Data Augmentation (CDA) 에 집중한다. 그러나 CDA 자체가 원본 코퍼스에서 살짝의 변형만 가하기에 다른 그룹 간의 표현상의 거리를 멀게 하는데 제한적이다.
따라서 이 논문에서는, adversarial training-inspired two-stage debiasing model using Contrastive learning with Continuous Prompt Augmentation (named CCPA) 을 제안한다.
- mitigate social biases in PLM's encoding.
- first stage - data augmentation method, 프롬프트 튜닝으로 다른 demographic groups 의 같은 페어를 멀리 학습
- second stage - contrastive learning, augmented sample pair 는 가깝게 학습하고 PLM 파라미터를 debiased 되도록 학습.
1. Introduction
최근의 연구들은 PLMs 가 demographic groups (gender, race, religion) 에 따른 사회적 편향을 학습하며, downstream task 에서 amplified 되고, 부적절한 outcome 을 내놓는다고 보았다.
이미 이와 관련하여 내놓은 해결책은 CDA 라 불리는 Counterfactual Data Aug. 이었다. 원본 코퍼스를 attribute words 로 변환하는 것. 예컨대
- RCDA 는 generator 를 도입하여 반대 의미의 문장을 만들고 학습시켰다.
- FairFil 은 positive 페어를 원본 코퍼스와 원본 코퍼스의 attribute words를 antonyms 로 변환시켜 얻었다.
- Auto-Debias 는 위키피디아에서 얻은 편향 문장들에서 attribute pair 을 얻어 증폭을 먼저 시킨다음, semantic alignment (Jensen-Shannon divergence) 을 수행했다.
이 방법들 모두 페어 간의 거리를 가깝게 하여 편향을 완화하고자 하는 것이지만 원본 코퍼스를 조금만 변형시키기에 demographic groups 간의 거리를 가깝게 제한한다. 결과적으로 모델 자체가 페어 간의 거리에 overfit 하는 현상이 발생.
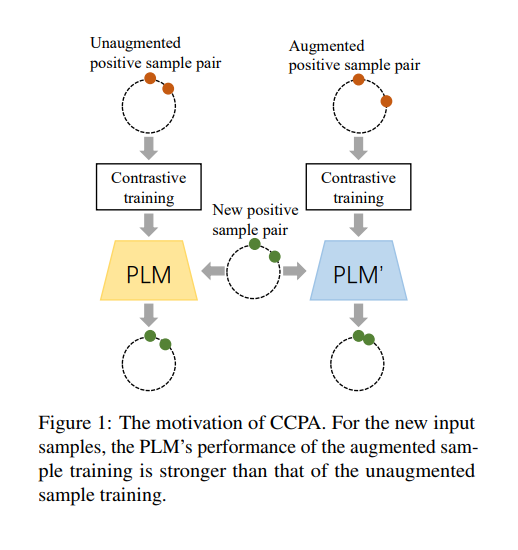
PLMs 인코딩에서 편향을 줄이기 위한 CCPA 방법을 살펴보자.
- adversial training 의 아이디어에서, 편향을 먼저 증폭한 후에 약화시키는 방법을 사용한다.
- 구체적으로, 먼저 CDA를 사용하여 원본 코퍼스의 attribute word 를 교체하여 counterfactual 페어를 만든다. (=different demographic groups)
- 그 후 positive sample 페어에 대해 augment => 프롬프트 튜닝으로 이 둘 사이 거리를 멀게 하고 different demographic groups 사이 편향을 증폭시킨다. (거리를 멀게한다는 것은 편향을 증폭시킨다는 것과 같다.)
- 다음에 contrastive learning 을 통해 positive pair 간 거리를 가깝게 하고 different demographic groups 사이 편향을 완화한다.
따라서 CCPA 는 샘플 페어간 표현 공간을 확장하여 모델이 과대적합되는 것을 방지한다. (기존 문제 해결) => 한정된 리소스로도 debiasing 에도 도움.
결과적으로 CCPA는 성 관련 편향을 완화하는데 성공하였으며, downstream tasks 에 있어서 PLM의 fairness 를 향상시키면서 언어모델로서 능력을 유지했다고 논문은 설명하고 있다.
2. Methodology
PLMs 에서 특히나 성 관련된 사회적 편향을 해결하기 위한 CCPA 를 살펴보자. 2가지 단계로 구성된다! 1) Continuous Prompt Tuning 2) Fine-Tuning with Contrastive Learning 이다. 전체적인 구성은 아래와 같다.
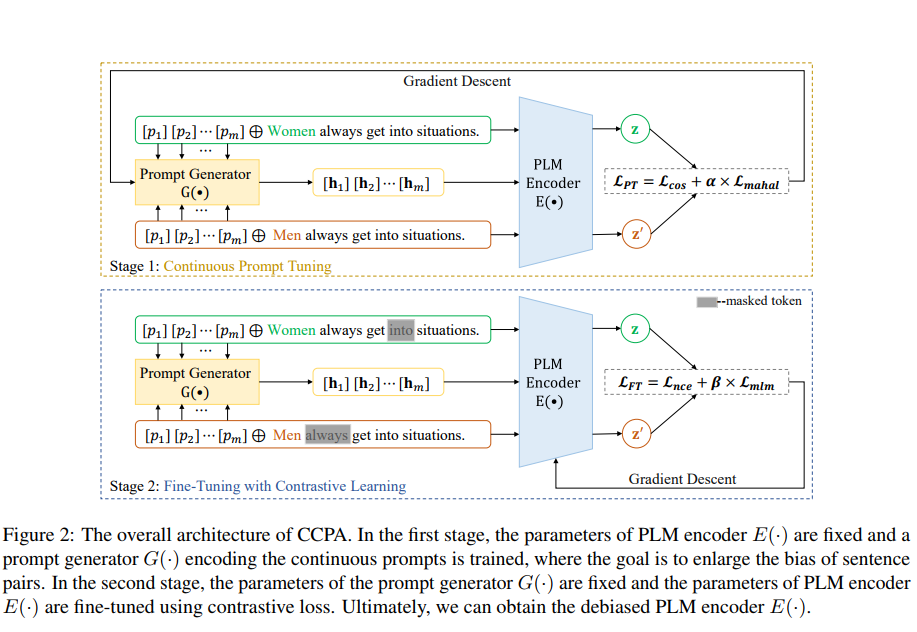
2.1 Pre-Processing based on CDA
먼저 훈련 코퍼스에 대해 전처리를 해줘야 한다. 전처리는 Counterfactual Data Augmentation 이라 불리며, 줄여서 CDA라 한다. 각각의 attribute words 리스트가 주어질 것이며, 각 attribute words 에 대해 들어온 문장의 다른 단어들은 그대로 두고 att word 와 반대되는 문장을 생성한다. (ex. male => female) 그러면 N개의 counterfactual pairs () 로 구성된 집합 S가 만들어질 것이다.
2.2 Continuous Prompt Tuning
Prompt-based learning 이란 모델이 풀어야 할 task 와 나아가야할 instruction 을 더 직접적으로 주는 맥락에 속한다. (손으로 직접 만드는 방법과 자동생성하는 방법이 있다.) (template + label word 형태이다) 프롬프트를 인간이 이해할 수 있는 자연어로 한정하지 않고(discrete prompt), 임베딩 공간에서 숫자로 가이드를 주는 것이 continuous prompts 이다. prompt learning 에 관해 잘 정리된 글 을 보자.
adversarial training 에서 아이디어를 얻어, 학습 과정이 복잡할수록 학습 능력이 증가한다고 보고, 위의 prompt tuning 을 통한 data augmentation 을 제안했다. (counterfactual pairs 간의 거리릘 멀게 하는 것이 목표.) 정리하자면 continuous prompt tuning = data aug. = add difficult information(concat) = amplify bias 와 같은 의미가 된다.
전처리를 통해 얻은 counterfactual pair (s, s') 마다 각 문장의 head 에 같은 프롬프트를 시퀀스를 concat 한다. 그러면 augmented pair () 가 그 문장의 표현을 얻기위해 들어간다. PLM의 encoder E()함수를 통과하면 각각으로부터 을 얻는다. G()함수는 프롬프트 시퀀스가 들어올 때 이를 인코딩하는 generator 이며, bidirectional LSTM 을 사용한다. 프롬프트 시퀀스의 각 토큰 p에 대해 임베딩 h는 아래와 같이 G를 통해 인코딩된다.
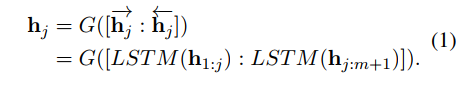
단계 1에서 training objective 는 의 거리를 멀도록 학습시키는 것이다. 그래서 Loss 자체는 Cosine Similarity 로 줘서 z와 z'의 유사도가 클수록 손실이 많도록 디자인한다. z와 z'는 다른 attribute 의 페어로 이 둘간의 유사도가 낮게 표현된다는 것은 두 다른 성별간의 편향이 극대화된다는 것을 의미한다.
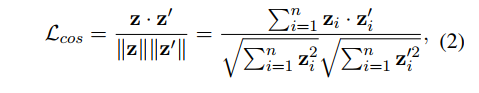
그러나 본래 분포에서 의미관계를 고려하여 적당한 제약이 필요하므로 Mahalanobis 거리가 loss fucntion 의 규제로 채택된다. 이 규제 덕분에 augmented smaples 역시나 본래 데이터 코퍼스의 분포를 유지하면서 다양해질 수 있다. (의미를 지킨다.) z는 프롬프트 임베딩이 포함된 것까지 모든 배치를 뜻하며, 모든 배치에서 S, 즉 프롬프트 임베딩을 제외한 표현을 뺀다. 따라서 프롬프트끼리의 공분산을 따지는 것으로 분산이 줄이는 방향으로 학습한다.
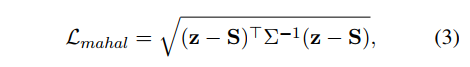
최종적으로 이 둘을 더하여 구성한 loss 는 generator G()를 학습시킬 떄만 사용하며 PLM 의 파라미터는 고정된다. (이렇게 고정해야만 편향을 증폭시키는 prompt emeddings 를 얻을 수 있다, 편향된 generator 탄생)

2.3 Fine-Tuning with Contrastive Learning
그다음 논문에서는 PLM의 인코딩은 편향을 줄이는 쪽으로 학습하자고 한다. (아까 얼려둔 것을 풀자!) 목표는 counterfactual pairs 간 유사도를 최대로 학습하여 다른 attribute 그룹 간 표현의 일치를 이뤄내는 것이다.
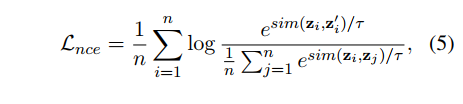
이번 단계에서는 오직 PLM의 파라미터만 학습하고 프롬프트 임베딩은 고정하도록 한다. 처음에는 (편향이 증폭되었으니) Loss 가 굉장히 클 것인데, 이를 이용하여 학습을 더 해주고, 다른 그룹 간 차이를 줄여주어 그룹에 독립적인 표현을 학습할 수 있다.
bias 를 신경씀과 동시에 언어모델로써의 기능도 잘 하기위해 mlm loss 도 이용한다. 따라서 PLM 인코딩을 학습시키는 loss 는 다음과 같다.
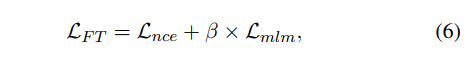
3. Experiments
답해야 할 질문은 다음과 같다.
-
PLM 인코딩의 편향을 완화하기 위해 CCPA는 얼마나 효과적인가?
-
CCPA 의 어떤 요소가 영향을 줬는가?
-
CCPA가 언어모델링의 능력을 유지할 수 있는가?
-
attribute word list 는 생각보다 간단하다.
{MALE, FEMALE}={(man, woman), (boy, girl), (he, she), (father, mother), (son, daughter), (guy, gal), (male, female), (his, her), (himself, herself), (John, Mary)}. -
데이터셋은 5개를 사용하였다.
-
모델은 tasks-agnostic debiasing models 를 사용했다. (CDA, Dropout, Sent-Debias, FairFil, INLP, MABEL, Auto-Debias)
-
비교군은 DistilBERT, ELEATRA 와 이를 baseline으로 적용한 모델들
-
Metric 은 Internal bias 로 SEAT(다른 att와 target concept 사이 관련도를 평가), StereoSet(PLM의 편향을 평가하기 위해 fill in the blank template 이용), CrowS-Pairs(mask 된 토큰이 편향 문장에 할당되는 비율)
-
external bias 로 Bias-in-Bios(남자 예측 tpr, 여자 예측 tpr의 차이가 없을수록 좋음), Bias-NLI(그 문장이 neutral 인지 아닌지 예측하여 빈칸 채워넣기)가 있다.
3.3 Debiasing Performance Analysis
3.3.1 Internal Debiasing Results
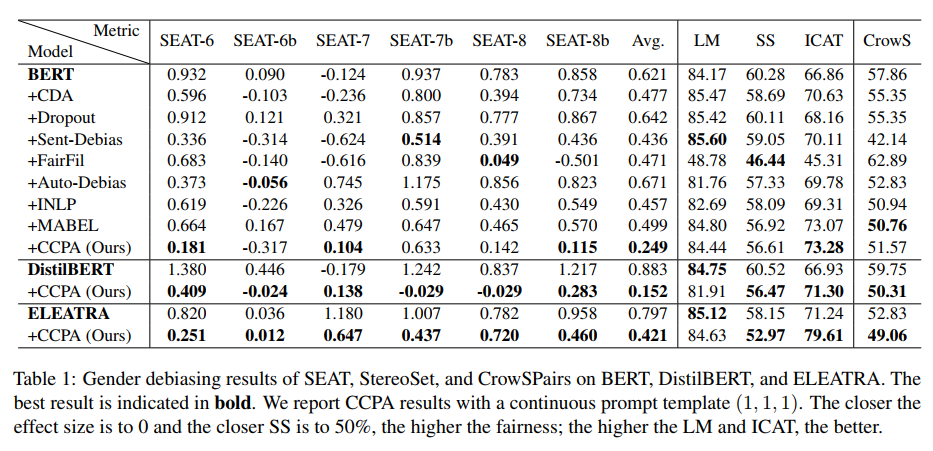
BERt, DistilBERT, ELEATRA 를 베이스라인으로 3가지 메트릭에 대해 평가한 결과다.
BERT 의 경우, CCPA는 SEAT 의 3가지 평가요소에서 optimal results 를 보였다. (평균 또한 가장 우수) 또한 StereoSet 에서의 결과는 CCPA가 언어모델로써 BERT 의 능력을 약하게하지 않고 살짝 높인다는 것을 알려준다. LM과 SS에서 모두 최고의 성능은 아니지만 ICAT에서는 다른 모델보다 우수하다.
DistilBERT, CCPA의 경우 대부분이 SEAT에서 최고성능을 달성했으며 CrowS에서도 가장 이상적. LM점수는 떨어졌고, 그 이유는 아마 Semantic information 때문이지 않을까..(too much debiasing)
ELEATRA, CCPA의 경우 기존보다 LM을 제외한 모든 성능에서 우위를 기록했다.
3.3.2 External Debiasing Results
CCPA의 external debiasing 에 대해 확인하기 위해 BERT 를 파인튜닝했다. Bias-in-Bios tasks 에서 CCPA는 GAP(rms)를 제외하고 gender fairness 를 달성했다.
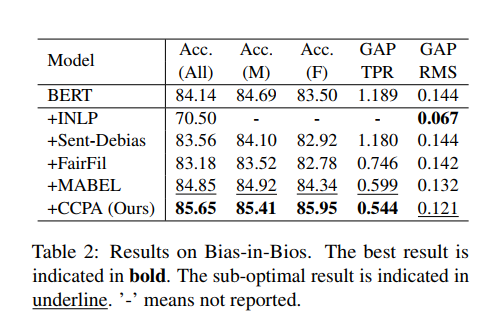
Bias-NLI tasks 에서 CCPA는 모든 metric 에서 sub-optimal 을 달성했다.
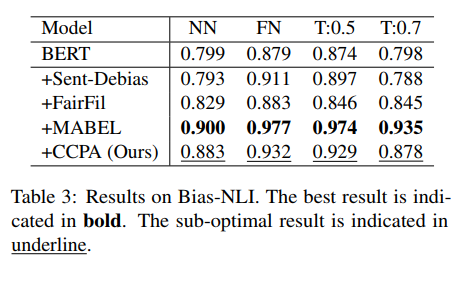
MABEL은 NLI tasks 자체를 활용하여 훈련한 debiasing method 이기에 그 다음을 차지한 CCPA가 더 의미있다고 할 수 있다.
Language Modeling Capability Analysis
GLUE benchmark 의 9개 tasks 에 대해 성능을 측정했다. CCPA는 BERT 의 성능과 견줄만하며, 평균 점수가 거의 동일하다.
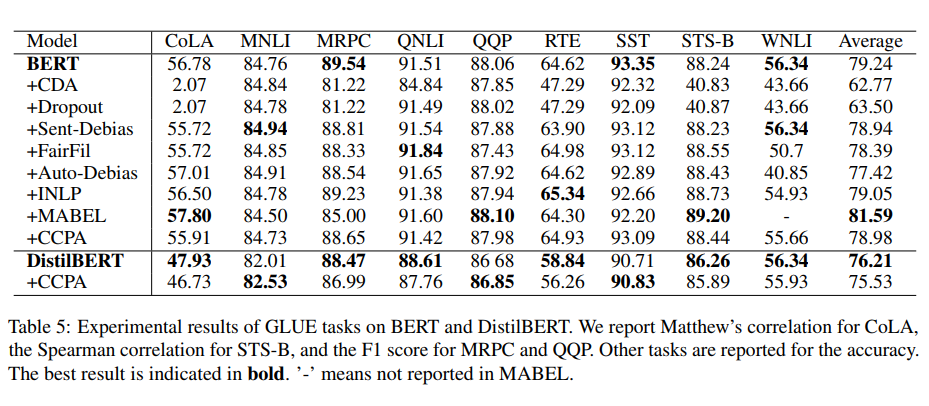
5. Conclusions
- CCPA: two stage debiasing model that combine contrastive learning with continuous prompts
- continuous prompt stage: generator encoding train, to increase distance between counterfactual pairs
- fine tuning stage: contrastive learning to reduce distance augmented sample pairs.
- stronger debasing ability + LM capability
