reshape(행,열)
일련의 배열을 추출한 뒤 배열.reshape(행,열) 을 찍어주면 해당 배열이 행, 열 수에 맞게 이차원 배열로 정렬된다. 사진의 픽셀 개념이라 생각하면 편하다. 그런데 시각화를 하기 위함이지, 그 이상으로 학습이나 검증 과정에선 원래의 일반적인 배열을 사용해야 한다는 점.
astype(np.unit8)
dtypes 를 찍으면 int64, float, object 등 각 컬럼의 타입이 나오는데, 해당 데이터 프레임의 칼럼 사이 모든 타입이 같을 때는 df.astpye('타입') 을 하면 그 타입으로 한 번에 바뀐다. 추가적으로 원하는 컬럼만 바꾸고 싶을 경우에는 astype({'column' : 'type'}) 로 표시해주면 된다.
cross_val_score(모델, 입력데이터, 라벨, cv값, scoring = 'accuracy')
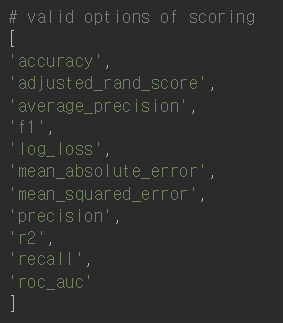
교차검증을 위한 코드이다. 인자를 받아서 성능을 반환하는 함수이다. cv 개수에 맞춰 성능을 반환한다. scoring 뒤에는 각각 다음과 같은 scoring 방법이 존재한다.
cross_val_predict(모델, 입력데이터, 라벨, cv값)
일반 predict 와 다르게 cv 를 이용한 예측값이다. 폴드에서 얻은 각 예측값을 반환한다. 분류 단원에선 이렇게 만든 예측값을 오차 행렬을 만드는 데 사용한다. 오차 행렬은 (진짜 라벨, 예측값) 을 인자로 받는다.
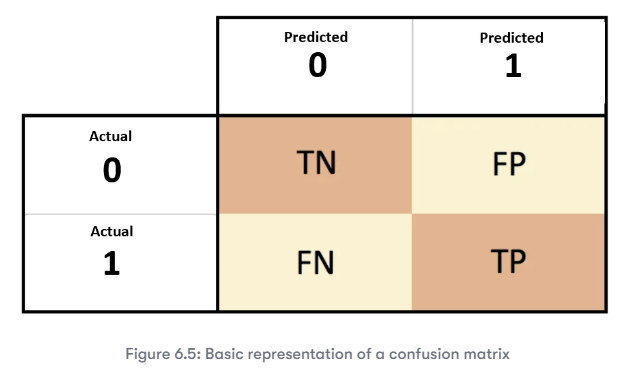
confusion_matrix(진짜 라벨, 예측값)
을 넣어주면 2X2 로 다음과 같은 행렬을 반환한다.
여러 떠도는 행렬의 이미지가 많지만 적어도 sklearn 이 반환하는 오차 행렬은 다음에 맞춘다.
precision_score(진짜 라벨, 예측값)
recall_score(진짜 라벨, 예측값)
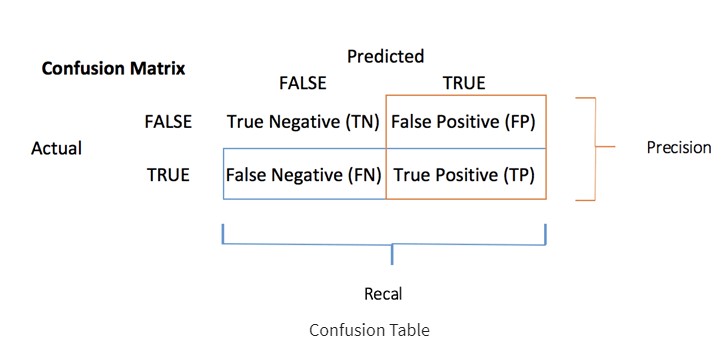
각각 정밀도와 재현율을 반환한다.
역시나 아까 봤던 행렬 기준으로 계산한 정밀도 (= 정확도) 와 재현율은 다음과 같다.
decisoin_function()
predict_proba()
사이킷런의 분류기에서 예측의 불확실성을 추정하는 함수 두 가지이다. 이진탐색에서 임계값은 각각 0, 0.5이다.
decision_funciton() 의 경우 결과값은 (n_samples, n_classes) 이며 각 샘플이 하나의 실수값을 반환한다. 이 값은 특정 클래스에 데이터 샘플이 속한다고 믿는 정도를 의미한다. 반환값이 양수면 양성 클래스, 음수면 음성 클래스 를 의미하는 것!
predict_proba() 의 경우 역시나 결과값은 (n_samples, n_classes) 각 클래스에 대한 확률이며 0과 1 사이의 값을 갖는다. 클래스의 확률 합은 항상 1인 것이다!
precision_recall_curve(진짜 라벨, 예측값)
roc_curve()
roc_auc_score()
둘 모두 sklearn.metrics 에서 임포트 해주는 메서드다.
fit() 과 fit_transform()
fit_transform() 은 말그대로 fit() 과 transform() 을 한 번에 처리할 수 있게 해주는 메서드이다. 학습한 것을 적용하는 과정까지 포함된 것!
from sklearn.preprocessing import StandardScaler
#scaler정의
scaler = StandardScaler()
#train data에 scaler를 fit
scaler.fit(X_train)
#train data 변환
X_train_scaled = scaler.transform(X_train)
#test data 변환
X_test_scaled = scaler.transform(X_test)