분석을 위한 데이터 처리 기술 기본
데이터 관계 이해, GROUP BY 이용, Analytic window 함수 활용하기 가 기본으로 꼽힌다.
✅ 데이터 관계 이해
주어진 테이블을 보고 데이터가 어떤 관계를 맺는지 살피는 것이다. 데이터의 관계가 무엇일까?
- 1:1, 1:M, M:N 관계 살피기
- 테이블에서 행 별로 주인공 찾기.
- 분석 주요 차원/ 도메인 지식
테이블에서는 예컨대
product , oder-items , oders, customers 와 같은 정보가 있을 수 있다.
customers 와 oders 는 1:M 관계이다. 하나의 주문자가 주문한 여러 내용이 그곳에 담긴다. oders 과 oder items 는 또다시 새로운 1:M관계이고, oders 과 prodcut는 m:1 관계이다. 이처럼 각 도메인마다 가질 수 있는 관계는 다양하며, 변형 가능하다. 이를 이해하는 게 중요하단 말씀!
✅ GROUP BY 활용
실습할 때 Group by 는 꼭 사용해야 하는 함수로 꼽힌다.
- Group by, Group by Case when 의 자유로운 활용
- 집합의 변형
- 원하는 데이터 추출을 위한 변경, 조작, 가공
✅ Analytic window 함수 활용
SQL에서 주로 사용하는 함수로 보인다. 분석 함수로, 행 그룹의 값을 계산하고 행마다 일정한 결과를 반환한다.
Pandas join 을 적극적으로 활용하자
분석에 있어서 join 을 적극적으로 활용하면 기존 테이블에서 새로운 조합으로 원하는 정보 추출을 위한 관계를 형성할 수 있다. 지금은 merge 함수를 이용할 것이다!
join_result = x.merge(y, on = 'key' how =?)
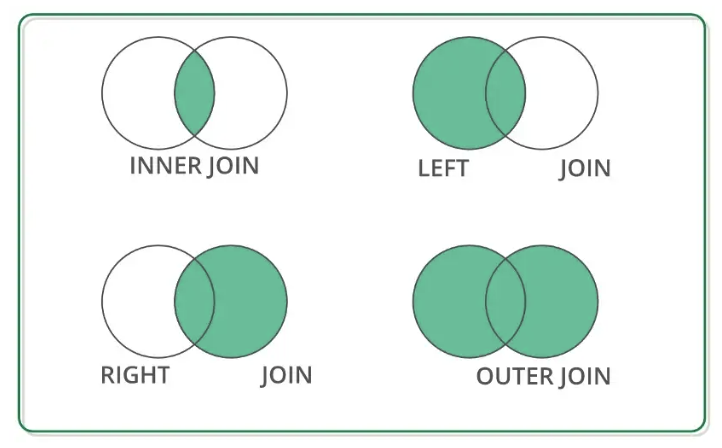
다음과 같은 문법에서 how 가 가질 수 있는 파라미터는 다음과 같다.
how = 'inner', how = 'left' , how = 'right' , how = 'outer'
이를 벤다이어그램으로 보자.
Pandas join 코드
import pandas as pd
d1 = {'customer_id':[1,2,3,4,5,6],
'product':['Oven','Oven','Oven','Television','Television','Television']
}
df1 = pd.DataFrame(d1)
d2 = {'customer_id':[2,4,6,8],
'state':['California','California','Texas', 'Hell']}
df2 = pd.DataFrame(d2)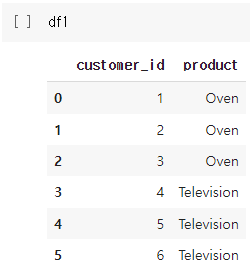
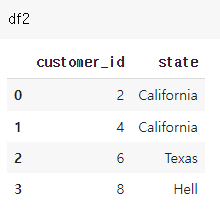
데이터 프레임 두 개가 완성되었다. 이제 이들을 병합해보자.
🔽 inner 조인 수행
#inner_join_result = pd.merge(df1, df2, on='customer_id', how='inner')
#inner_join_result
inner_join_result = df1.merge(df2, on='customer_id', how='inner')
inner_join_result기본적으로는 아래와 같이 코드를 짜는 것을 추천한다.
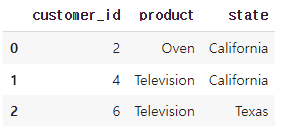
공통된 2,4,6 출력
🔽 left Outer 조인 수행
left_outer_join_result = df1.merge(df2, on='customer_id', how='left')
left_outer_join_result왼쪽 테이블은 모두 포함하고, state 가 없어도 NaN 으로 넣고 출력
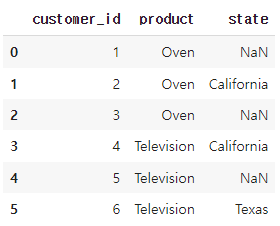
🔽 right Outer 조인 수행
right_outer_join_result = df1.merge(df2, on='customer_id', how='right')
right_outer_join_result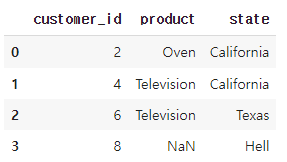
🔽 Full outer join 수행
full_outer_join_result = pd.merge(df1, df2, on='customer_id', how='outer')
full_outer_join_result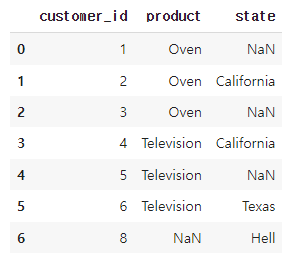
Group by 의 사용
데이터 분석의 기초로 Group by 를 잘 사용하는 것도 중요하다고 보았다. Group by 의 사용을 sql 코드로 보자.
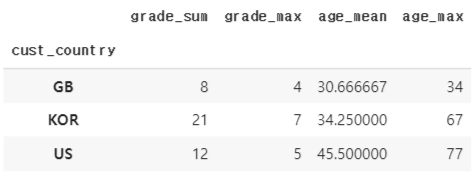
SELECT cust_country, sum(grade) total_sum FROM customer GROUP BY cust_country
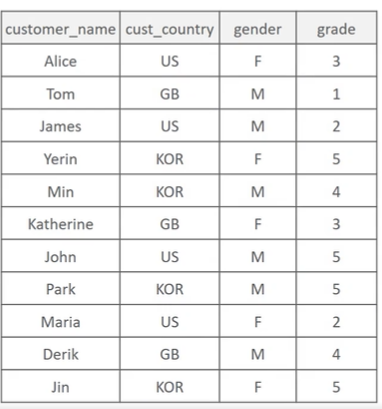
다음과 같은 테이블에서 위 sql 코드의 역할은 무엇일까?
cust_country 열을 선택하고, grade 의 합을 구하는데 cust_country 를 기준으로 묶는다. 다음과 같이 된다.
이를 pandas 에서 구현하려면 조금 복잡하긴 하지만 코드를 봐보자.
Cust_group = customer.groupby('cust_country')
Cust_df = pd.DataFrame()
Cust_df['sum_grade'] = Cust_group['grade'].sum()
Cust_df['max_grade'] = Cust_group['grade'].max()
Cust_df['avg_age'] = Cust_group['age'].mean()
Cust_df['max_age'] = Cust_group['age'].sum()합, 최대, 평균, 합을 나이와 grade에서 각각 구해봤다. 이게 싫다면 agg()를 사용하자.
agg()는 agregation 하려는 컬럼값과 함수를 Dictionaty 값으로 입력하여 단순화할 수 있는 도구이다.
Cust_group = customer.groupby('cust_country')
agg_dict = {'grade' : ['sum', 'max'],
'age': ['mean', 'sum']
}
Cust_df = Cust_group.agg(agg_dict)
따라서 Group by는 정리하여 동일한 값을 가진 행을 요약행으로 그룹화해서 특정 함수 (count, max, min, sum, avg)와 함께 분석, 통계를 낼 수 있는 도구이다.
Group by 를 자유롭게 사용
group by 를 자유롭게 사용할 수 있을 때 까지 실습해보자. 다음은 데이터프레임을 만드는 코드이다.
import pandas as pd
cust_dict = {
'customer_name':['Alice', 'Tom', 'James', 'Yerin', 'Min', 'Katherine', 'John', 'Park', 'Maria', 'Derik', 'Jin'],
'cust_country':['US', 'GB', 'US', 'KOR', 'KOR', 'GB', 'US', 'KOR', 'US', 'GB', 'KOR'],
'gender':['F', 'M', 'M', 'F', 'M', 'F', 'M', 'M', 'F', 'M', 'F'],
'grade':[3, 1, 2, 5, 4, 3, 5, 7, 2, 4, 5],
'age':[25, 34, 26, 33, 67, 29, 54, 21, 77, 29, 16]
}
customer = pd.DataFrame(cust_dict)
customer.head(11)
(시작) .groupby('column') 으로 DataFrameGropby 를 생성
기존데이터프레임.groupby('원하는 컬럼')
을 사용하면 DataFrameGroupby 타입의 메서드를 받아들일 수 있는 데이터 프레임이 생성된다.
(기존 데이터프레임과 새로 만들 데이터 프레임의 중간자 역할을 해줄 것이다.)
출력해보면 일반 데이터프레임과 같다.
cust_group = customer.groupby('cust_country')
cust_group.head()
이제 cust_country 는 중간자임과 동시에 어떤 정보를 넣어도 국가별로 계산해주는 데이터프레임이 된다!
(참고) 개별로 agg 컬럼 및 agg 연산별 호출
현재 cust_group 에는 위에서 보았듯 일반 데이터프레임인데 메서드를 받으면 국가별로 계산해줄 준비가 되어있다.
🗝️ 이때 어떤 것을 계산할지는 agg 컬럼이라 하고 어떤 계산을 할지는agg 연산 이라 한다. agg는 aggregation 의 약자니까 당연하다!
새로운데이터프레임['column'] = 중간자['agg 컬럼'].sum()
를 활용하면 기존 데이터프레임의 agg 컬럼을 불러오고, agg 연산을 해줘 새로운 데이터프레임의 열에 할당해줄 수 있다.
이를 사용하면 agg 컬럼을 기존 데이터프레임에서 가져오고, 그를 기준으로 더한 값을 새로운 데이터 프레임에 지정한 컬럼 이름에 할당해서 더해줄 수 있다.
#새로운 데이터프레임
cust_agg = pd.DataFrame()
#국가별 grade sum, max 할당
cust_agg['sum_grade'] = cust_group['grade'].sum()
cust_agg['max_grade'] = cust_group['grade'].max()
cust_agg.head()
#국가별 나이 mean, max 할당
cust_agg['avg_age'] = cust_group['age'].mean()
cust_agg['max_age'] = cust_group['age'].max()
cust_agg.head()
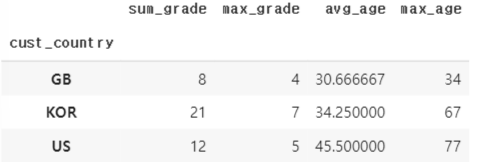
(도움) 키 컬럼을 인덱스로 올려주기
이때 새로운 데이터프레임의 국가 cust_country 를 올려줘보자.
데이터프레임.resst_index()
를 활용하여 데이터프레임의 인덱스로 변환시켜줄 수 있다.
cust_agg = cust_agg.reset_index()
cust_agg.head()
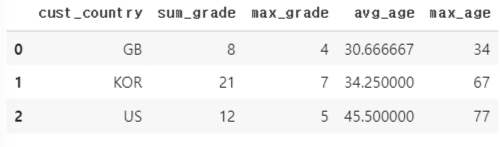
**(참고) agg 함수를 이용해서 agg 연산 인자를 리스트에 입력.
중간자['agg 컬럼'].agg(['agg 연산1', 'agg 연산2'])
를 이용하면 아까 했던 연산 .sum() 과 .max() 를 리스트에 넣어 ['sum', 'max'] 와 같이 한 번에 작성한다.
따라서 네 줄에 걸쳤던 코드가 두 줄로 변한다!
#agg 연산 인자를 리스트에 넣어주기
cust_agg1 = cust_group['grade'].agg(['sum', 'max'])
cust_agg2 = cust_group['age'].agg(['mean', 'max'])
print(cust_agg1.head())
print(cust_agg2.head())
현재는 다른 데이터프레임에 있어서 합쳐주면 다음과 같다.
cust_agg = cust_agg1.merge(cust_agg2, on='cust_country', how='left')
cust_agg.head()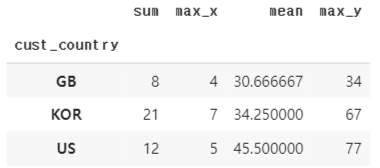
(main 방법) agg 인자로 agg 칼럼 명과 agg 연산 함수 리스트를 기재한 딕셔너리 입력
사실 이게 메인 방법으로 활용하면 가장 깔끔한 방법이다.
딕셔너리 = { 'agg 컬럼' : ['agg 연산1', 'agg 연산2']
'agg 컬럼' : ['agg 연산3', 'agg 연산4']
}
새로운 = 중간자.agg(딕셔너리)
agg_dict = {
'grade':['sum', 'max'],
'age':['mean', 'max']
}
cust_agg = cust_group.agg(agg_dict)
cust_agg.head()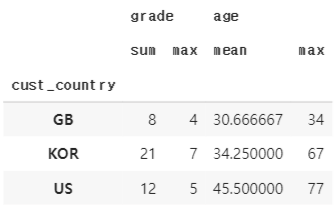
현재 agg.columns 는 다음과 같아서 이를 _ 로 반복문을 돌며 연결시킨다.

cust_agg.columns = [('_').join(column) for column in cust_agg.columns]