SQL 에서 Group by case when 의 활용
다음과 같은 테이블이 있다고 하자.
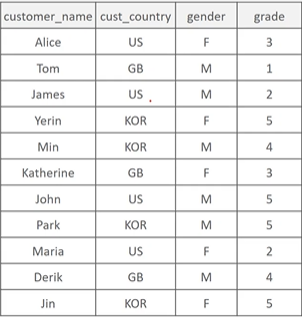
SELECT cust_country, sum(grade) total_sum
Sum(case when gender =='M' then grade end) male_sum,
Sum(case when gender =='F' then grade end) female_sum
FROM customer GROUP BY cust_country성별이 남성일 때 합하고, 여성일 때 합한다, cust_country 안에서! 다음과 같이 행이 KOR 남성 합, KOR 여성 합 이 아니라 한 행에서 남성 합, 여성 합의 열이 생긴다. 따라서 불필요하게 행이 길어지는 것을 방지할 수 있다.

지금 보다 중요한 것은 판다스이므로 판다스 문법에 대해 알아보자
Pandas Group by Case When 활용.
조건 걸기 > 데이터프레임1 > 중간자 > 데이터프레임2 > 조인 순으로 진행.
판다스에서는 case when 문법이 없다. 따라서
- 해당하는 조건을 대신 걸어 별도의 DataFrame 을 만든다
- 이들을 개별적으로 groupby 수행한다
- 개별 groupby 에 각각 함수 적용하여 DataFrame 을 만든다
- 이들을 조인하는 순으로 수행하는 수밖에 없다.
#조건 거는 컨디션 변수
Cond_male = customer['gender'] =='M'
Cond_female = customer['gender'] =='F'
#컨디션을 데이터프레임에 할당. 별도의 DataFrame
Cust_male = customer[cond_male]
Cust_female = customer[cond_female]
#Groupby 수행. 중간자 생성
Cust_male_group = Cust_male.groupby('cust_country')
Cust_female_group = Cust_female.groupby('cust_country')
#중간자에 함수 적용. 새로운 데이터프레임
Cust_male_grp_df = Cust_male_group['grade'].sum()
Cust_female_grp_df = Cust_female_group['grade'].sum()
#조인
Cust_case_df = cust_male_grp_df.merge(cust_female_grp_df, on = 'cust_country', how = 'outer'Feature Engineering
머신러닝 모델 성능 최적화의 방법들
Feature Engineering
알고리즘이 예측을 더 효율적으로 수행할 수 있도록 데이터를 가공하는 것을 feature Engineering 이라 한다.
- 기존 feature 들을 다양한 형태로 재가공
알고리즘 선택
선형, SVM, 확률, 트리 기반
boosting 계열 알고리즘 강세 (lightGBM)
Hyper parameter 튜닝
최적화된 알고리즘 하이퍼 파라미터를 튜닝하는 것.
🔽 Feature Engineering 주요 기법
-
스케일링
standardScaler, MinMaxScaler -
변환
로그변환
polynomial 피처 변환
PCA 변환 -
인코딩
레이블 인코딩, one-hot encoding -
결측치 / 이상치 치환
-
skew 데이터 세트 보정
오버 / 언더 sampling
추가로 업무적인 이해를 바탕으로 한 피처 재가공과 생산이 필요하다.
🤔: 업무이해가 바탕이 된 Feature Enginnering 이 필요하다는 것.
주요 접근 방식
업무적으로 중요한 feature들의 재결합 및 재가공을 수행한다
- 중요도가 높은 feature 들에 대해 재가공
- 주요 컬럼끼리 차, 합, 비율
- 다양한 agg
➡️ 업무적으로 의미 있는 컬럼 재생산하자
최근 데이터, 액티브한 데이터 위주 필터링 후 가공
- 시계열성 데이터의 경우 최근 데이터가 우선
➡️ 유효성을 잘 따지자
아직 데이터로 표출되지 않은 피처들을 도출하자.
지나치게 비슷한 피처를 많이 도출하는 것은 과적합의 문제를 가져오니 조심하자.
