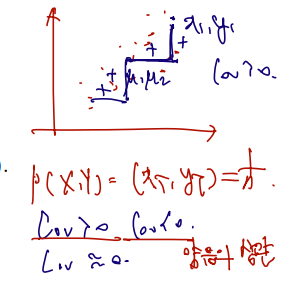
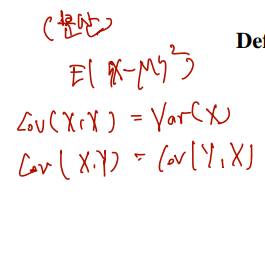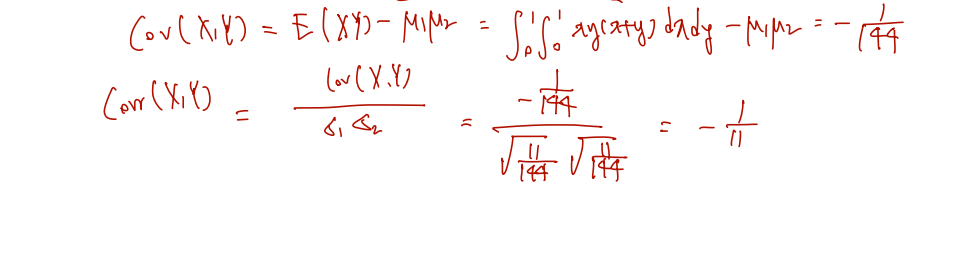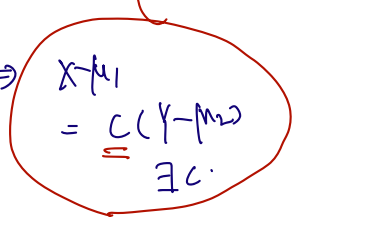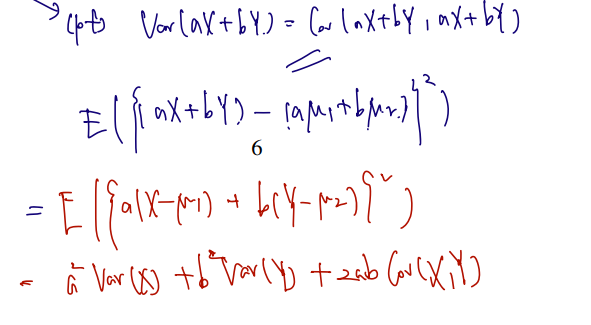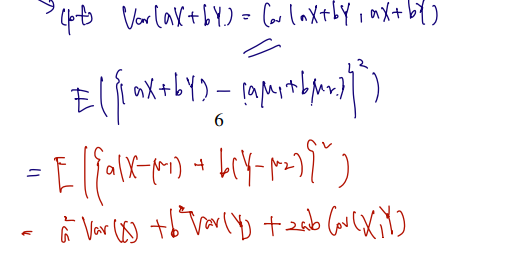Similarly, μ2=E(Y)=127 and σ22=Var(Y)=14411. Then,
joint pdf 가 주어질 때 X and Y의 coefficient 를 구하는 문제.
coefficient 를 구하려면 먼저 covariance 를 구해야 하고, 그러려면 E(XY)와 X, Y의 각 평균 값이 필요하다.
E(XY)는 joint pdf 가 이미 주어졌으므로 서로 다른 변수에 대해 (support 에 대해) 두 번 적분하여 구할 수 있고, 각각의 평균은 marginal distribution 을 구하는 technique.
이 문제에선 joint pdf 가 x+y로 대칭의 형태를 이루고 있으므로, X에 대해 분산과 평균을 구했다면 이를 Y에 대한 상황에서도 동일하다고 보면 쉽다.
Theorem (Cauchy-Schwartz inequality).
For any random vectors (X,Y) whose covariance exists,
∣Cov(X,Y)∣≤Var(X)Var(Y)
Thus,
−1≤Corr(X,Y)≤1
r.v's X,Y가 주어질 때 두 변수의 Covariance 는 (절댓값은) 각각의 variance 의 곱에 루트를 씌운 값보다 항상 작거나 같다는 것이다. 그렇다면 궁금한 것은.. 등호는 과연 어떤 case 에서 성립하느냐이다. 등호가 성립하는 조건은, 한 변수를 다른 변수의 상수배처럼 쓸 수 있을 경우이다.
이는 Corr(X, Y)가 1또는 -1인 경우에 속하며, 이 경우 한 변수를 다른 한 변수의 선형 변환으로 쓸 수 있다.
ρ=1(ρ=−1) iff there exist a>0(a<0) and b∈R s.t. P(Y=aX+b)=1.
→ (Covariance and) correlation measures only a linear relationship.
다음은 covariance의 성질을 확인하고 마무리하자.
Theorem (X와 Y가 독립이라면 Cov, Corr 는 모두 0이다.)
If X and Y are independent random variables, then Cov(X,Y)= 0 and hence Corr(X,Y)=0.
Proof sketch. From the independence, E[(X−μ1)(Y−μ2)]=E[(X−μ1)]E[(Y−μ2)]=0.
증명은 간단히 Cov의 정의로부터 시작하여, 독립일 경우 두 변수 곱으로 연결된 Expectation 을 각각의 expectation 곱으로 꺼낼 수 있음, 각 (변수 - 평균)의 expectation 은 항상 0임을 쓴다.
이에 대한 역은 참이 아님에 유의한다. 즉, $\operatorname{Cov}(X, Y)=\operatorname{Corr}(X, Y)=0, 이라 하더라도, X와 Y가 dependent 일 수 있다.
(c.e.)
Theorem (Properties of covariance).
If X and Y are any two r.v.'s. Then,
(i) Cov(X,X)=Var(X);
(ii) Cov(X,Y)=Cov(Y,X);
(iii) For any a,b,c,d∈R,Cov(aX+c,bY+d)=abCov(X,Y);
(iv) For any a,b∈R,
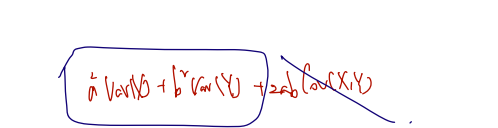
Var(aX+bY)=a2Var(X)+b2Var(Y)+2abCov(X,Y)
1, 2번은 쉽게 생각해볼 수 있고 3, 4번이 중요하다. 3번은 각 변수를 선형 변환한 것의 Covariance 가 Covariance 에 그만큼의 실수배를 취함을 말하고 있다. 이는 X, Y에 대해 실수배해줄 때는 분명 변수에 대해 편차를 바꿀 수 있으므로 Covariance 에 반영이 되고, 뒤에 무언가를 더하는 것은 편차를 바꾸지는 않는다고 직관적으로 이해 가능하다. 4번의 증명은 아래와 같다.
만약 4번에 X와 Y가 independent 라는 조건이 더해진다면? Cov = 0이므로, 앞쪽의 각 변수의 variance 끼리만 더해주면 된다.