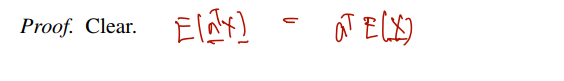다변수 확률 분포에서의 정의는 이변량 확률벡터를 다변량 벡터로 확장하기만 하면 된다. (단변량 vs. 다변량, 다변량일 경우 random vector 에 속함을 기억하자. 다변량 내에서도 bivariate r.v 가 조금 더 특수한 상황이고, 일반적으로 multivaritate 를 말한다면 이변량을 넘어서는 일반적인 다변량 확률벡터로 이해하자.)
Definition (Joint distribution). Let d∈N. X:=(X1,X2,…,Xd)T is called a (multivariate) random vector ((다변량) 확률벡터) if X(⋅) is a multivariate function that maps c∈C to X(c):=(X1(c),X2(c),…,Xd(c))∈Rd, i.e., X:C→Rd11
조금 더 간단한 정의는 다음과 같다.
An equivalent definition is that X is a random vector if each component of X is a random variable.
각 random variable 을 모은 random vector 라 보고 넘어가자.
vector X에 대한 notation 과 space of X는 다음과 같다.
We will use the vector notation X=⎣⎢⎢⎢⎢⎡X1X2⋮Xd⎦⎥⎥⎥⎥⎤=(X1,X2,…,Xd)T,
The space of X is D={x∈Rd:x1=X1(c),x2=X2(c),…,xd=Xd(c),c∈C}.
다변량 확률벡터에 대해서도 joint cdf 와 joint pmf, joint pdf 를 정의하는 것이 가능하다. 이미 익숙한 내용이지만 차이점을 중심으로 눈여겨 보자.
The joint cdf (결합누적분포함수) of X is defined by
FX(x):=P(X1≤x1,X2≤x2,…,Xd≤xd)
joint cdf 는 각 확률변수가 주어진 값보다 각기 작거나 같은 확률을 and 로 연결한 것이다.
A random vector X is called discrete if there exists a countable subset S⊆Rd such that P(X∈Sc)=0. For a discrete r.v. X, the joint pmf (결합확률질량함수) is defined by
pX(x)=P(X=x)
pmf 는 X 가 discrete 일 경우 각 확률변수가 주어진 값을 가질 확률로 정의하면 된다. discrete 이고 정의부터 그 외의 subset 에 대해선 확률이 0인 것을 감안하면, SX=supp(X):={x∈Rd:pX(x)>0} 임이 자연스럽다.
마지막으로 X가 continuous 일 경우에 어떠한 nonnegative function g가 다음을 만족시킨다면 (non-negative function 의 적분으로 정의되는 cdf가 있다면) 그 g는 joint pdf이며, fX(x). 와 같이 적는다.
(다음이 존재; 어떤 함수를 x1, x2, ...xd까지 적분하여 joint cdf가 되는 nonnegative function 존재.)
변환의 기댓값은 이변량/단변량을 다변량으로 확장시킨 것 외에 같은 form 으로 이해 가능하다. 만약 헷갈린다면.. 1.8절로 돌아갔다 오자.✅
mgf 는 그냥 X 대신에 random vector X가 들어가며 이 역시 나머지는 같다.
mgf. Let X1,…,Xd be random variables and suppose that E{exp(t1X1+⋯+tdXd)} exists for −hi<ti<hi for some hi>0(i=1,…,n). Then the moment generating function (mgf) of the joint distribution of the random variables is
MX(t)=E{exp(t1X1+⋯+tnXn)}
2.7 Transformation of random vectors
random vector X에서 Y로의 변환에 대해 알아보도록 하자.
Consider transforming d random variables X1,⋯,Xd to d random variables Y1,⋯,Yd s.t. y1=u1(x1,⋯,xd),⋯,yd=ud(x1,⋯,xd).
2.7.1 One-to-one transformation case
여기서는 랜덤벡터의 변환을 one-to-one 인 경우와, many-to-one 인 경우 두 가지로 나누어서 구할 것이다. 먼저 X와 Y의 1-1 경우에 대해 알아보자. Y의 표현은 다음과 같이한다. 이 경우 랜덤벡터가 어떻게 구성되는 지 확인할 수 있다.
변환에서 중요한 것은 pdf of Y를 pdf of X와 Jacobian 을 가지고 쓸 수 있다는 것이었다. 다음은 pdf of Y를 구하는 방법.
fY(y)=fX(w1(y),…,wd(y))∣J∣,y∈SY
w=(w1,…,wd):=u−1 는 X에서 Y의 변환인 u의 inverse transformation 이다.
J=∂x/∂y∈Rd×d be the Jacobian of the transformation x=w(y). -> x를 y로 편미분 한 것의
determiannt 를 곱해주면 됨.
(Example)
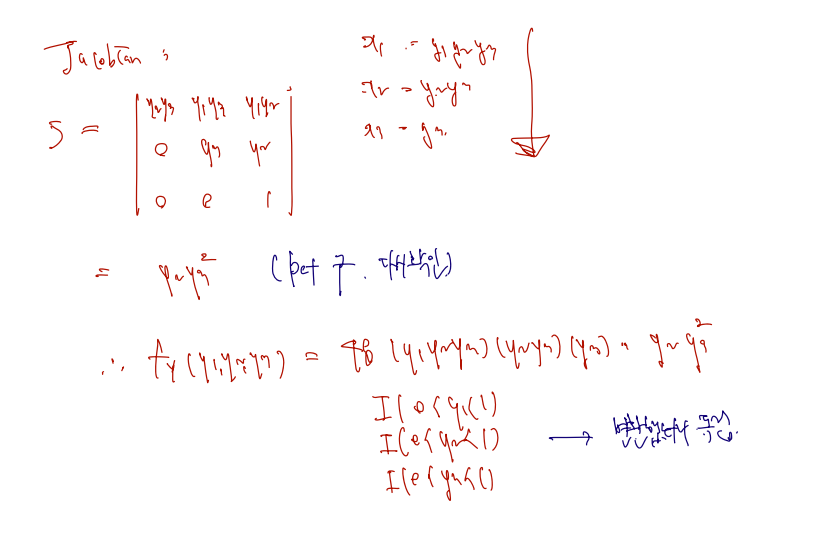
Let X=(X1,X2,X3)T have the joint pdf f(x1,x2,x3)=48x1x2x3, 0<x1<x2<x3<1. Let Y1=X1/X2,Y2=X2/X3 and Y3=X3
Find the joint pdf of (Y1,Y2,Y3).
X에서 Y로의 변환이 g라고 할 때, g가 injective 임을 보인다.
주어진 x1, 2, 3 사이의 부등식을 이용해 support of Y를 새롭게 쓴다.
Jacobian 을 쓰고 determiant 를 구하는데, 변수를 헷갈리지만 않으면 어렵지 않게 구할 수 있다.
pdf of X와 Jacobian 의 곱의 형태로 pdf of Y를 완성한다. Support of Y를 다시 써주면 완성.
이 문제에서처럼 변환 전에는 그렇지 않았던 변수가 변환 후 독립성이 확인되는 경우가 있을 수 있다.
2.7.2 Many-to-one transformation case
many-to-one 의 정의는 다음과 같다.
Definition. (many-to-one transformation case)
A map u:X→Y is called k−1 ( k to one), if there exist A1,⋯,Ak such that ⋃i=1kAi=X and Ai∩Aj=ϕ for i=j (i.e., A1,⋯,Ak exhaustive sets), and AiuY is injective for each i=1,⋯,k.
집합 A의 각각의 합집함이 X가 되고, 어떤 임의의 i, j에 대해서도 겹치지 않을 때 (다시 말해 X의 사상을 1-1로 뜯을 때)
각 A에 대해 Y로의 1-1 transformation 을 만족하면 된다.
(many-to-one 의 pdf 표현에 대해선 충분히 이해하지 못했다. 다시 이해한 후 설명을 추가할 예정)
2.8 Linear combinations of random variables
rancom variables (vectors)에 linear 변환을 한 것의 expetation, covariance, variance에 관심을 기울이자.
먼저 Let X1,…,Xn be r.v.s and define T=∑i=1naiXi for some constants a1,…,an. 라 하자. 이는 기존에 우리가 알던 변수 X에 대해 단순히 ai 가 곱해진 형태이며, 아래와 같은 주장들이 가능해진다.
기댓값) Then, E(T)=∑i=1naiE(Xi).
linearity of expectation
공분산) 또다른 W를 같은 Y에 대해 bi 가 곱해진 변수로 이해할 때,
Let X1,…,Xn,Y1,…,Ym be r.v.s and define T=∑i=1naiXi and W=∑j=1mbjYj for some constants a1,…,an,b1,…,bm. If E(Xi2)<∞ and E(Yj2)<∞ for i=1,…,n and j=1,…,m, then
Cov(T,W)=i=1∑nj=1∑maibjCov(Xi,Yj)
bi-linearity
분산) Let X1,…,Xn be r.v.s and define T=∑i=1naiXi. If E(Xi2)<∞ for i=1,…,n, then
독립조건 가) 여기에 독립 조건이 추가된다면 Let X1,…,Xn be independent r.v.s and define T=∑i=1naiXi. Then,
Var(T)=i=1∑nai2Var(Xi)
사실은 이 주장들은 covariance matrix 를 시각적으로 떠올려보거나 chapter 2.5의 properties of covariance 내용을 쓰면 수식으로 쉽게 쓸 수 있는 내용이다. 처음이라 생송할 수 있지만.. 이러한 곱의 형태나 linearity 를 이용해 쪼개는 것에 익숙해지면 보다 쉽게 covariance 를 이해할 수 있을 것으로 느껴진다. 일단 부단히 써보는 것.. 중요.