Pretraining and Fine-tuning
1) Transfer learning
Transfer learning 이란 이미 pretrained 된 모델을 가지고 fine-tune 하는 일련의 과정을 의미한다. 모델을 다시 훈련하는 이유는 복잡한, specific 한 그 downstream task 문제를 잘 풀기 위해서였다.
2) Pre-trained Language Model
Transformer + Transfer Learning
기본 구조는 Transformer 로 하되, Transfer Learning 을 적용할 수 있다. (학습 방법)
-
Pre-training
구조를 가지고 언어 모델링을 잘 하자가 목표이다. 같은 Transformer 라 하더라도, Encoder only, Encoder-Decoder, Decoder only 등 다양함을 알아두자. -
Fine-tuning
Pretrained LM 을 가지고 원하는 문제를 풀고싶을 때 진행하는 추가적인 학습이다. 여전히 같은 Transformer 구조를 가지고 학습한다. - 사전 학습된 PLM 까지 학습
vs. Fine-tuning 이 아니라 특성 추출기만으로 사용할 수도 있다. PLM은 벡터 표현을 뽑아내는 역할만 하고, output-layer 만 학습시킨다. (이걸 transfer learning 으로 봐야할지?)
3) Transformer Architecture
Transformer 는 "Attention is All you need" 논문에서 제안된, Encoder-Decoder 모델이다. 기계번역이라면, Encoder 는 소스 언어, Decoder 는 타깃언어의 시퀀스를 각각 처리한다. (인코더가 생성한 문맥 정보를 받아 디코더가 동작한다.)
4) Transformer + Transfer Learning
트랜스포머 인코더만 (구조를) 가져왔다고 가정하자. 이를 가지고 언어 모델링을 목표로 pretraining, fine-tune 할 수 있다. - Encoder Only PLM 이다.
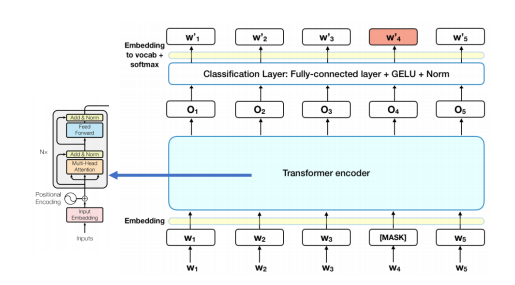
BERT
1) Overview of BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) 논문의 Encoder-Only 모델을 보자.
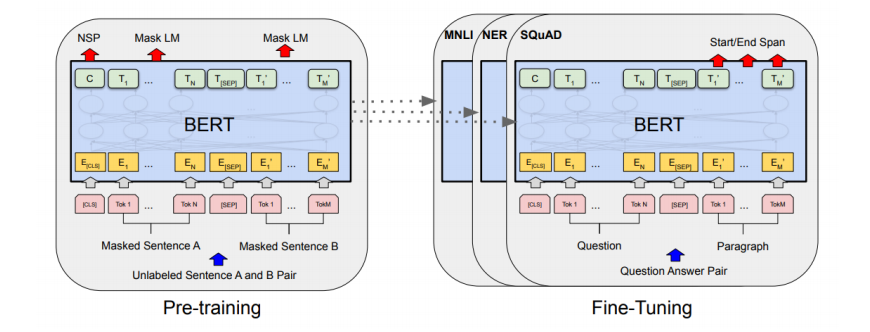
왼쪽은 Pre-training, 오른쪽은 Fine-tuning. 하나씩 알아보자.
2) Pre-training BERT
- do not use traditional left-to-right / right-to-left language models to pretrain
- 기존 LM 이라 함은 이전 단어들이 나왔을 때, 다음 단어를 예측하는 것이었다
- 그러나 이 방법은 디코더를 학습시킬 때 조금 더 적합해보인다. Encoder 연산은 representation 을 만들어내는 데 역할이 있으므로, 다음 단어를 예측하는 방식으로 훈련하는 것 외에 다른 방식을 생각해내게 된다.
따라서 BERT 가 제시한, LM을 학습시키기 위한 방법은 다음과 같다.
- Masked LM
- Next Sentence Prediction
✅ Masked LM
Encoder 를 가지고 Bidirectional으로 LM 을 학습시키기 위한 방법이다. (self-attention의 개념과 유사)
- 입력 토큰의 일부 비율을 무작위로 mask 처리한다.
- 비율은 토큰 개수의 15%
- 만약 비율이 너무 크면 문맥을 학습하지 못할 것이고, 비율이 너무 작으면 수렴까지의 시간이 많이 소요될 것이다
- 마스킹 된 토큰을 예측한다.
- 마스크 위치의 벡터가 원래 단어를 맞추는 방식으로 학습한다. emb_dim 의 벡터를 가지고, 구체적인 단어를 Softmax() 로 예측하고, 실제 단어와 비교해서 loss 계산을 학습하는 방식이다.
그러나, 이렇게 mask 를 사용하여 pre-train 을 하면 fine-tune 시에 환경이 달라진다는 문제가 생긴다 - fine-tuning 은 마스킹을 하지않는다 - 따라서 마스크의 이용이 fine-tuning 에서 문제가 생길 수 있음을 알아두자. 빈칸맞히기는 잘하는데, 그것만 잘하면 되나..? 하는 느낌.
위의 문제를 해결하기 위해, 마스킹되는 입력 토큰을 다른 토큰으로 변환한다. 15% 의 마스크 내에서
-
(Mask) 그 중 80% 는 마스크 처리를 그대로 한다.
-
(Same) 10%는 그대로 둔다
-
(RND) 10%는 랜덤한 단어를 넣는다.
이 비율은 실험적으로 결정된 것이며, fine-tuning 성능까지 고려했을 때 가장 높은 성능을 내는 비율이다.
✅ NSP
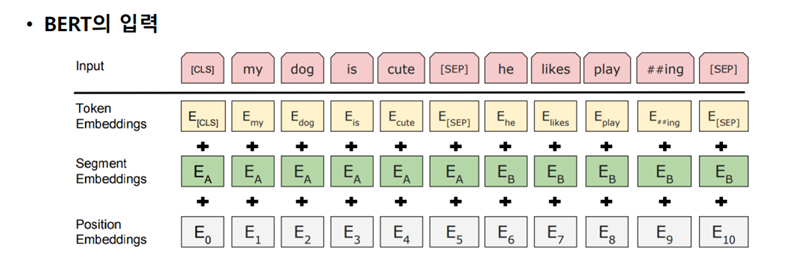
단어 수준이 아닌 문장 관계를 이해하는 모델을 훈련하기 위한 방법이다. 문장의 시작과 끝을 표시하는 [CLS], [SEP] 토큰을 사용한다.
- [CLS] 토큰 - 분류를 위해
- 문장 가장 앞에 [CLS] 토큰을 삽입한다
- CLS설명
- [SEP] 토큰 - 두 문장의 구분을 위해
- 별도의 두 문장 사이에 [SEP] 토큰을 삽입한다
- NSP 학습
- 50% 는 A다음에 B가 딸려오는 set로 선택한다. (IsNext)
- 50%는 랜덤한 문장 2개를 그냥 선택한다. (NotNext)
- 결론적으로, CLS A SEP B SEP 사이사이에 MASK를 맞추기도 하고, A와 B가 IsNext인지 NotNext 인지 분류하는 문제도 푼다.
하지만 이후 연구에서 NSP 학습이 필수가 아닐 수도 있다는 실험 결과가 존재하긴 한다...
✅ Pre-training Details
- Data: Wikipedia, BookCorpus
- 64 TPU chips for 4 days
- BERT-base: 12layer, 768hidden, 12head
- BERT-large: 24layer, 1024hidden, 16head
3) Fine-tuning BERT
✅ 1. Sentence Pair Classification Task
두 문장의 관계를 파악하는 Task 이다. 두 문장을 SEP 토큰으로 연결한 토큰들을 입력으로 받고, CLS 토큰에 output layer 를 적용하여 예측한다.
- MNLI: entailment, contradiction, neutral
- QQP
- RTE
✅ 2. Single Sentence Classification Tasks
한 문장 내에서 내용을 파악하는 task로, 입력으로는 단일 문장의 입력 토큰을 받고 CLS 토큰에 output layer 를 적용하여 레이블을 예측한다.
- SST-2: 이진 감정 분류 데이터셋이다. positive, negative 라벨.
- CoLA: 언어적 허용 가능성 또는 문법적 판단을 위한 데이터세트이다. acceptable, unacceptable 라벨.
이것들을 다같이 모아둔 걸 GLUE benchmark dataset 으로 평가할 수 있다.
Other Encoder Only LM
1) RoBERTa
RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019)
- BERT 와 같은 구조에 더 큰 데이터로 더 오래 학습
- Dynamic masking: 에폭마다 다른 masking 사용
- NSP 삭제
2) SpanBERT
SpanBERT: Improving Pre-training by Representing and Predicting Spans (2020)
- 인접한 단어 범위인 span을 마스킹해서 pretraining 을 더 어렵고 유용하게 만듦. 따라서 Span 을 예측하는 NLP task 에서 유리하다. (QA task)
3) ELECTRA
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (2020)
- 마스크에 대해 만들어진 토큰의 정답을 구분하는 loss 적용
- GAN 의 아이디어를 활용
