[Paper] A survey of the State of Explainable AI for Natural Language Processing
[Natural Language Processing]

- Reason for read: get better understanding of expalinable, interpretable AI system especially for Natural language processing / What is interpretabiltiy and how it is measurable. / what are further ideas for extension?
Intro
-
traditional NLP system: while box; rules, decision tress, hidden Markov models, losistic regressions, and others
-
Recent years: black box techniques; deep learning models, language embeddings as features
-
recent methods come at the expense of models becoming less interpretable.
-
explainability from the perspective of an end user whose goal is to understand how a model arrives at its result -> outcome explanation problem.
-
분류
- 1) 각 예측에 대해 individually 하게 설명하는지 / models prediction as a whole 설명인지.- 2) explanation 이 post-processing 이 필요한지 / 아닌지.
- 3) 생성형인지 / visualize 형태인지.
Categorization of Explanations
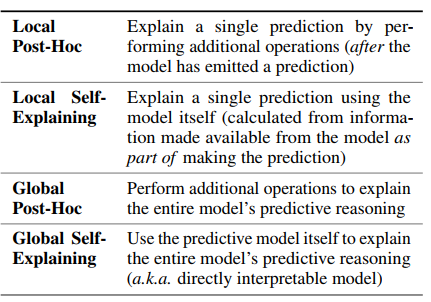
1. Local vs. Global
- local; 특정 인풋에 대한 모델의 예측 설명. (대다수) -> prediction 을 justify 하기에 좀 더 적합하다고 할 수 있음.
- global; 특정 인풋과는 독립적으로 모델의 예측 과정이 어떻게 이루어지는 지 설명. (소수의 paper)
2. Self-Expalining vs. Post-Hoc
-
Self-explaning; 예측과 동시에 explanation 을 생성하는 것. (모델의 예측 결과 자체가 이유가 되는 모델들이 여기에 속한다. 예컨대 모델 전체의 과정을 설명할 수 있으면서 예측 자체가 설명이 되는 모델들로 고전적인 Decision trees, rule-based 등이 있음. / feature saliency (attention) 등은 특정 인풋에 대한 설명으로 local 이지만 예측한다는 것은 feature 확정이 있다는 것이므로 local self-expalining 에 속한다.)
-
post-hoc; 예측이 만들어진 이후에 설명을 만들기 위한 additioanl operation 이 필요한 경우. LIME 은 surrogate model 이라는 추가 모델을 사용해 local explanation을 덧붙임.
Aspects of Explanations
1) explanation 을 끌어내기 위한 방법론에 따른 분류이며, 2) presentation 에 따른 분류이기도 하다. 가장 중요한 분류.
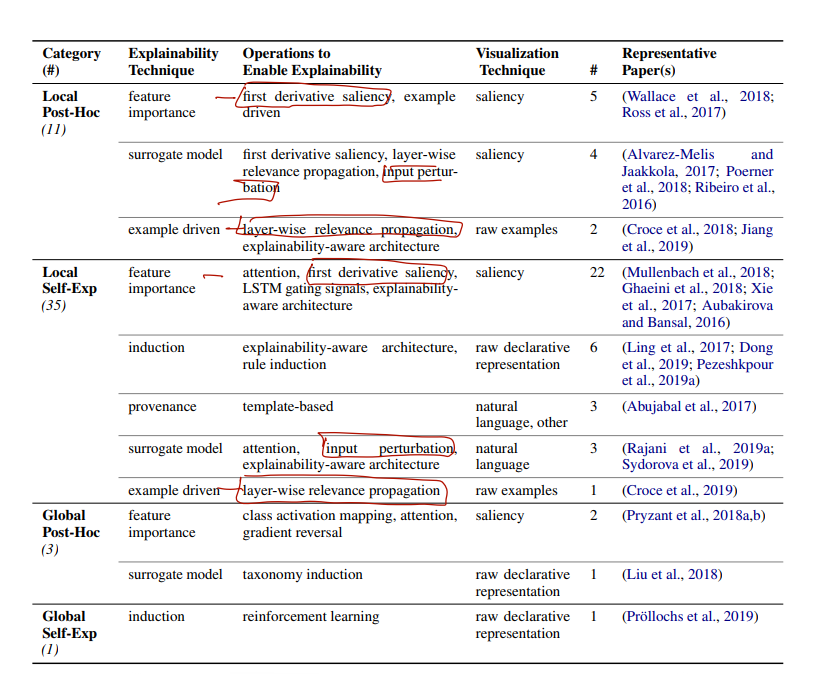
1. Explainabilbity techniques
-
Feature importance; final prediction 으로 가기 위한 서로 다른 feature 의 중요성을 조사하는 것. latent features, attention mechanism, first-derivative saliency 등. (근데 paper 들이 좀 올드하다.)
-
Surrogate model; second, explainable model 에 의한 설명. LIME 이 대표적 예시이며, 이 논문은 input perturbation 이라는 인풋으로 surrogate model 을 만들어 냄. 그러나 fidelity 문제.
-
Example-driven; input-prediction 에 대한 설명을 위해, input 과 의미적으로 비슷한 다른 input-label 쌍을 찾아 설명하는 것.
-
Porvenance-based; prediction-derivation 의 모든 과정을 펼쳐서 보여주는 것. (직관적)
-
Declarative induciton; rules, programs 등 인간 수준의 represenation 으로 설명을 끌어내는 것.
(여전히 방법론이나 paper 들이 올드해서, 몇가지 핵심적인 것만 읽고 넘어가야겠다.)
2. Operations to Enable Explainability
-
First-derivative saliency; gradient-based explanations 으로, input i가 output o에 미치는 기여도를 o를 i에 대해 미분해서 계산. (NN-based models 에 적합 / 어떤 layer에 대해서도 계산 가능. / feature imporatnace 계산 목적으로 사용 가능.)
-
Layer-wise relevance propagation; 이전 방법이 각 input 이 output 에 미치는 기여도를 기준으로 feature importance 를 계산한다면, feature importance 를 계산한다는 목적은 같지만 NN layer 을 추출해 feature 사이의 연관을 계산하는 방법. (따라서 importance explainability / example-driven 에 사용)
-
Input perturbatio; input x에 대한 output 의 설명을 input x의 perturbation 을 만들어 이들만 학습시킨 explainable model 로 설명하는 방법. (LIME)
-
Attention; 어텐션 자체의 개념 (NN model 이 무엇에 'focusing' 하는지)를 그대로 가져와, attention layer 를 feauture importance 를 분석하는 데 쓰면 됨!
3. Visualization techniques
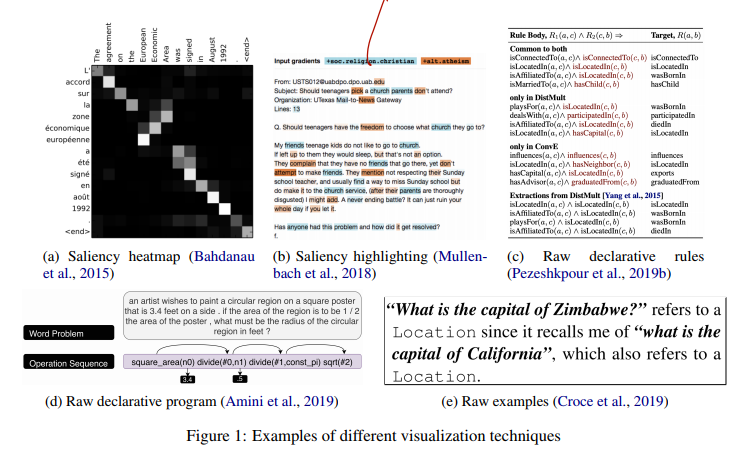
Evaluation
-
fidelity; how much they reflect the actual workings of the underlying model
-
comprehensibility; how easy they are to understand by humans
