지난 글 에 이은 트랜스포머 2번째 글.
Multi-head Attention
트랜스포머에 포함된 모든 attention 에는 멀티헤드라는 이름이 붙어있었는데, 도대체 멀티헤드가 무엇일까?
한 단어가 가치는 총 임베딩 디멘션인 d(model) 의 차원을 num_heads 로 나눈 차원을 가지는 Q, K, V 벡터를 가지고 어텐션을 진행한다고 하였다.
논문 기준으로는 한 단어는 512차원을 가지는데, 이를 num_heads = 8 로 나눈 64차원의 Q, K, V 벡터가 결과가 될 것이다.
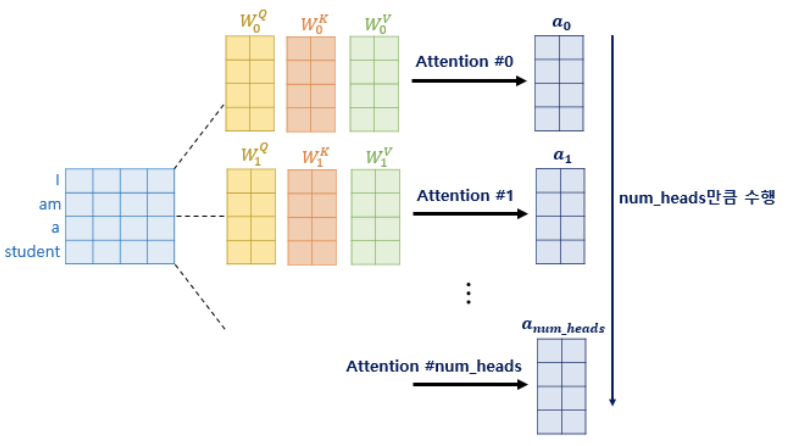
왜 num_head 의 개념을 도입한 것인가?
- 한 번의 어텐션보다 여러 번의 어텐션을 병렬로 사용하기 위해서
- 따라서 d(model)/num_heads 의 차원을 가지는 Q,k,V에 대해 num_heads 개의 병렬 어텐션 수행
- 다른 시각으로 정보 수집 가능
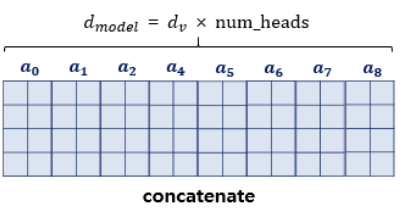
병렬 어텐션을 모두 수행하였다면 어텐션 헤드를 Concat 하고, 어텐션 헤드 행렬의 크기는 정상적인 행렬 크기로 복원한다. (num_heads 만큼 이어붙였으니 크기가 다시 seq_len, d(model) 로 돌아온다.
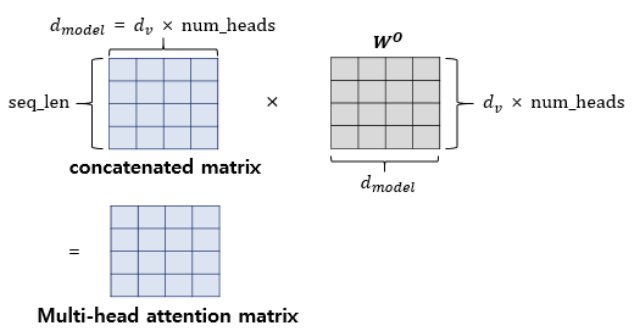
이렇게 어텐션 헤드를 모두 연결한 행렬에 다음 입력으로 들어가기 전 가중치 행렬W를 한 번 더 곱한다. 이 값이 multi-head attention 의 최종 결과물이며, 입력과 동일한 (seq_len d(model)) 의 크기를 가진다. (두번째 서브층인 FFNN 를 지나도 크기가 유지)
Padding Mask
어텐션 함수 내부 계산을 진행할 때, 입력 문장에 < pad > 토큰이 있을 경우 어텐션에서 제외하기 위한 연산을 수행한다.
< pad > 의 경우 의미를 담고있지 않은 토큰이므로 트랜스포머에선 아예 유사도를 구하지 않도록 masking 해주기로 했다. 아래 그림에서 행은 쿼리이고, 열은 키인데, 키에 < pad > 가 있는 경우 (입력이 빈 경우) 해당 열 전체를 마스킹한다. 마스킹은 구체적으로, 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어준다. 그럼 계산된 score에 softmax 를 적용하면 결국 0으로 확률이 나올 것이다.
def scaled_dot_product_attention(query, key, value, mask):
... 중략 ...
logits += (mask * -1e9) # 어텐션 스코어 행렬인 logits에 mask*-1e9 값을 더해주고 있다.
... 중략 ...
이제 두 번째 서브층인 position-wises FFNN 을 보자.
Position-wise FFNN
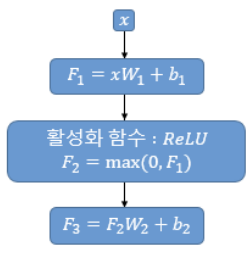
position-wise FFNN 은 인코더와 디코더 공통으로 가지고 있는 층이다. 완전 연결층을 뜻한다. 아래와 같이 많이 봤던 식으로 표현.
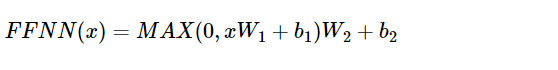
- 들어온 입력에 대해 계산
- 활성화 함수 ReLU 적용, $F_2 = max(0, F_1)
은닉층의 크기는 2048이다. 매개변수 W와 b 는 하나의 인코더 층 내에서는 동일하게 사용되고, 층마다는 다른 값을 가진다.
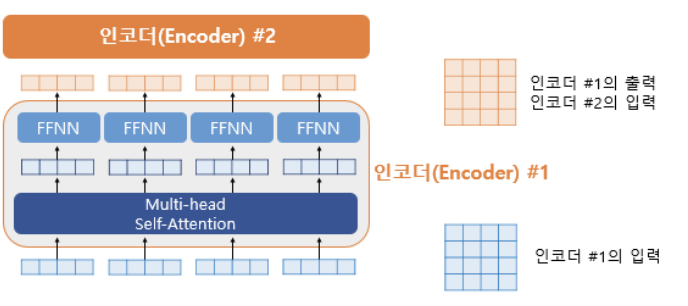
실제로는 오른쪽과 같이 계산되며, 인코더에 값이 들어오면 Multi-head Self-attention 을 지나고, FFNN 을 지나 출력되는 형태다. 두 층 모두 출력이 (seq_len, d_model) 로 유지된다.
Residual connection & Layer Normalization
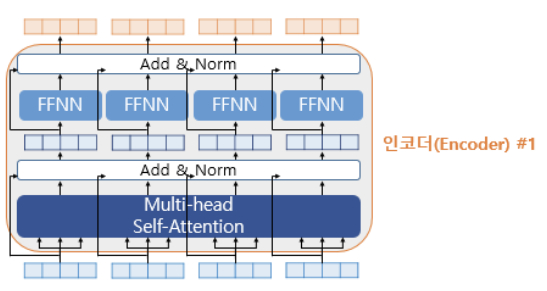
그럼 Add & Norm 이라 되어있는 이 부분은 무엇일까? 여전히 모든 인코더 구조를 본 것이 아니다. 나머지 2가지에 대해서도 알아보자.
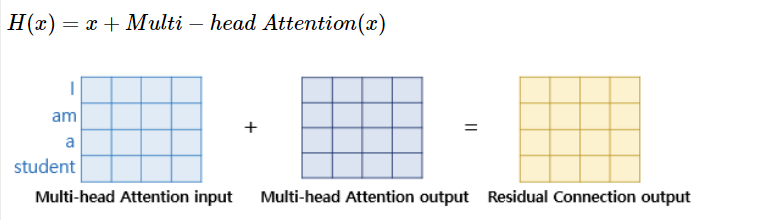
먼저 잔차 연결이란 입력 x와 함수 f(x) 가 주어질 때 구하려고 하는 값 H(x) = x + f(x) 로 계산하는 것이다. 함수 f(x) 가 트랜스포머에서는 이전에 살펴보았던 서브층 2개로 생각할 수 있다. 입력이 들어오면, 함수를 적용하지 않은 입력값 자체와, 함수를 적용한 값을 더한다.
Layer Normalization 이란 층 정규화를 뜻하며 잔차 연결까지 거친 결과에 정규화를 진행하는 것이다.
- 텐서의 마지막 차원(d_model) 단위로 평균, 분산을 구한다
- 값을 정규화하여 학습을 돕는다
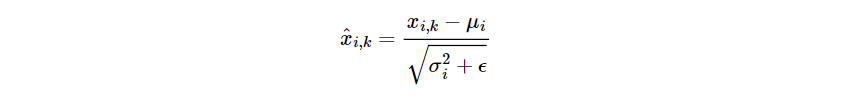
평균과 분산을 이용한 정규화이다.
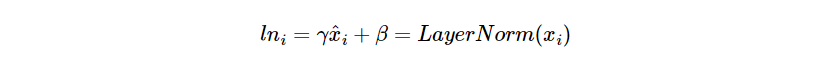
감마와 베타 벡터를 통한 정규화
인코더 구현
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 멀티-헤드 어텐션 (첫번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': padding_mask # 패딩 마스크 사용
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
만들어낸 인코더를 쌓자.
def encoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
From Encoder to Decoder
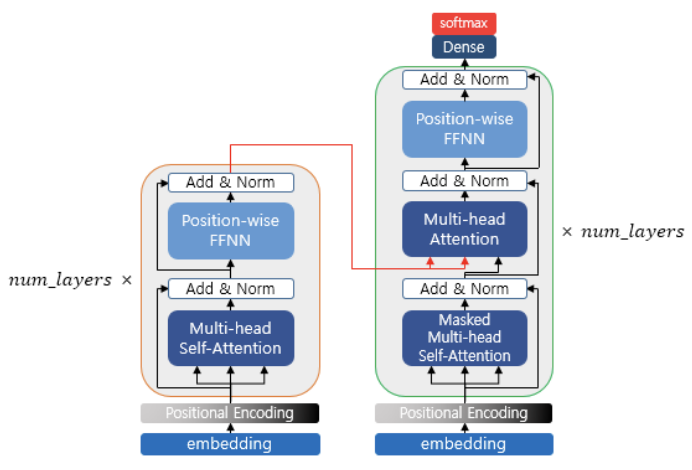
구현된 인코더는 num_layers 만큼 연산 후 마지막 층의 인코더 출력을 디코더에 전달한다. 디코더 또한 num_layers 만큼의 연산을 하는데, 이때마다 인코더의 출력을 각 디코더 층 연산에 사용한다.
