디코더의 첫 번째 서브층
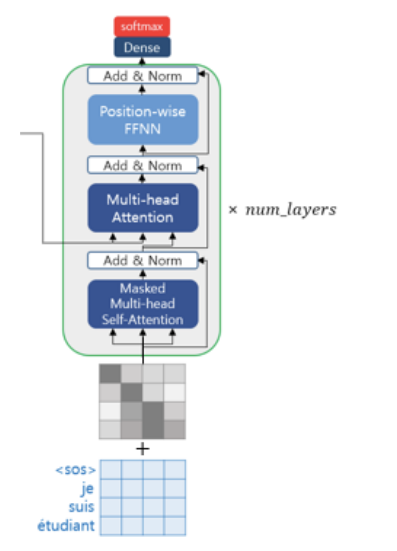
디코더 또한 positional encoding 를 거친 후 문장 행렬이 입력된다. 학습 과정에서는 번역할 문장에 해당하는 < sos > je suis étudiant 를 한 번에 입력으로 받고, 각 시점의 단어를 예측하도록 훈련된다.
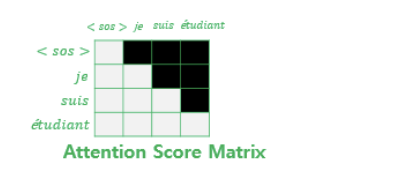
디코더의 입력 또한 한 번에 입력되므로 학습 과정에서는 정답을 보는 것을 방지하기 위해 미래의 단어를 참고하지 못하도록 look-ahead mask 를 도입한다. 현재 시점에서 예측할 때 현재 시점 이후의 단어에 mask 를 씌우는 것!
look-ahead 마스크는 디코더의 첫 번째 서브층에서 이루어지며, 어텐션 스코어 행렬에서 마스킹을 적용한다. 디코더의 층 이름은 'masked multi-head self-attention' 인데, 순서는 다음과 같다
- 입력 문장에 대해 일괄적으로 Q,K,V 계산
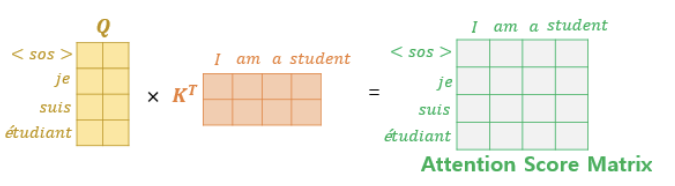
- Q, K 를 곱하여 Attention Score Matrix 얻음
- 구한 Attention Score Matrix 에 다음 단어를 참고하지 못하도록 마스킹
- 나머지 과정 같음.
디코더의 두 번째 서브층
디코더의 두 번째 서브층은 multi-head attention 을 수행하지만 self-attention 이 아니다. 따라서 쿼리: 디코더 행렬 / key = value = 인코더 행렬이다. 여기서 키, 값에 해당하는 인코더 행렬이 바로 두 번째 서브층과 이어진 인코더로부터의 입력이다.
정리하면, key = value 는 인코더의 마지막 층에서 가져오고, Query 는 디코더의 첫 번째 서브층의 결과 행렬로부터 얻는다. 따라서 번역에 있어서는 Q는 번역할 Target 문장의 언어, K,V는 source 문장ㅇ의 언어일 것이다.
디코더 구현 & 쌓기
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두번째 서브층)
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
구현된 디코더를 쌓자
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
모델 완성
# 하이퍼파라미터 입력
small_transformer = transformer(
vocab_size = 9000,
num_layers = 4,
dff = 512,
d_model = 128,
num_heads = 4,
dropout = 0.3,
name="small_transformer")
tf.keras.utils.plot_model(
small_transformer, to_file='small_transformer.png', show_shapes=True)
# 손실함수 정의
def loss_function(y_true, y_pred):
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')(y_true, y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
loss = tf.multiply(loss, mask)
return tf.reduce_mean(loss)

Mathematics, Algorithm, and IDEA for AI research🦖