1. Transformer Encoder-Decoder
기본적인 인코딩, 디코딩의 커다란 개념 자체는 같으나 디코딩의 과정에선 패딩을 이용한다. 첫 단계에서 I 를 예측, 두번째에서 I < pad > < pad > ... 를 보고 I am 을 예측. 세번쨰에서 I am < pad > < pad > ... 를 보고 I am a 를 예측한다.
만약 4번째 단어 정답이 student 이고, 예측이 boy 라고 한다면 teacher forcing으로 student 라는 정답을 입력으로 넣어주게 된다.
2. Stacked Architecture of Transformer
이러한 스택의 쌓은 레이어를 조절하면서 Transformer 모델의 크기를 조절할 수 있다. (tiny, base, large 등등..) 다만 주의해야 할 건 도메인마다 정해진 최고 성능을 낼 수 있는 스택 개수는 없다는 것이다. (해봐야 앎!!)
마지막 인코더에서 나온 결과를 디코더에서 사용하는 구조이다.
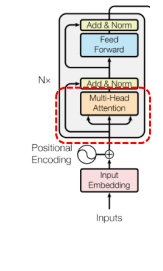
🤔1. Dot product 로 Attention score 를 구하는 이유?
Cosine similarity 는 결국 두 벡터 사이의 각을 구하는 것이다. 벡터 사이의 각이 작을수록 두 벡터가 유사하다고 판단하는 것.
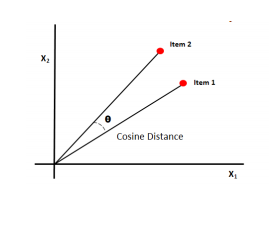
어쩄든 dot product 는 단순 곱인데 따라서 1. cosine similarity 와 비례할 수 있고 (분자) 2. scale 을 감안하지 않고 단순 계산으로 크기까지 고려할 수 있다. (분모분자) cosine similarity 보다 조금 더 좋을 수 있다는 것.
🤔 Head의 수를 임베딩 차원의 divisible number 로 하는 이유?
병렬 계산이 용이하도록 하는 것이 맞다. 또한 연산 이후 concate 을 할 때 dimension 값이 같도록 하기 위함도 있다. 768차원을 Q, k, V 각각 12차원으로 지정하여 계산하면 딱 떨어지지만, 10차원으로 지정하여 계산할 경우 마지막 Q, K, V는 8차원으로 계산되고 그러면 concate 할 때 차원이 같지 않은 상태가 만들어진다..!
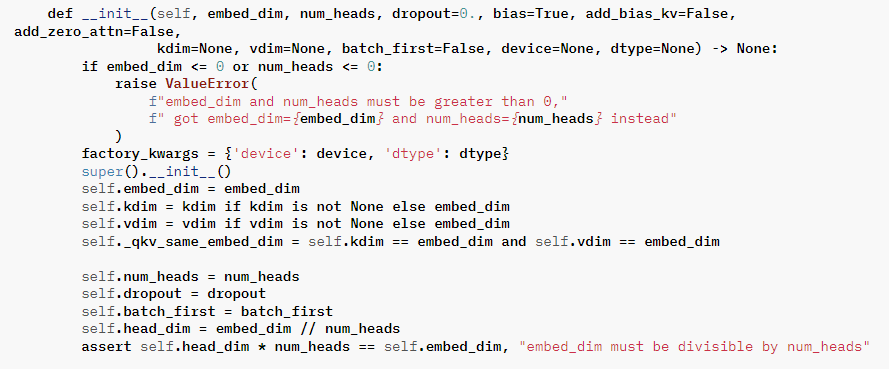
해당 코드에서 가져왔다. (https://pytorch.org/docs/stable/_modules/torch/nn/modules/activation.html#MultiheadAttention)
Transformer (2)
- Implementation of Transformer
- Transformer's Application
1) Implementation of Transformer
✅ 1) Implementation of Multi-Head Self-Attention
해당 부분의 구현을 보자.
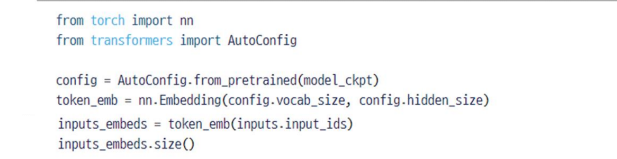
input: inputs_embeds (batch_size, seq_len, hidden_dim)
인풋을 만드는 방법을 알아보자. raw 한 문장이 들어온다면 1.토큰화시켜 해당 문장의 단어들의 인덱스들을 얻는다 2.인덱스를 가지고 임베딩으로 각각 변환한다
Scaled Dot-Product Attention 부분이다. 3가지 단계로 구한다.
- Attention score 구하고
- Attention distribution 구하기
- Attention weights, value 곱하여 output 만들기

- dim_k 는 distribution 해줄 때 정규화해주는 부분으로써 쿼리 사이즈이다. (= 768 값을 가진다)
- key.transpose(1,2) 는 1과 2의 위치를 바꾸게 되는 연산으로 [batch, seq_len, dimension] 을 [batch, dimension, seq_len] 으로 변환하게 된다
- weight 의 경우 확률 값이었다. softmax 를 씌워주자 (softmax 값을 구하기 위해선 다 더하면 1이 되는 값을 가져와야 하므로 dim 이 필요한데 생략할 경우 마지막 차원 (dim = -1) 을 가져온다.)
- attnetion output 값을 최종적으로 구하기 위해 bmm 연산 해주자
- 결고의 차원은 [batch, seq_len, dimension] 이다.
그러나 multi-head 로 적용시켜야 하기 때문에 추가할 사항이 하나 더 있다. attention 을 적용하는 Q, K, V의 차원은 단어 자체의 차원이 아닌 head 를 감안한 head 의 차원으로 바꿔 계산한다.(각 head 마다 다른 Q, K, V 를 가지기 위해서) 다음과 같이 연산한다.

- Q, K, V 의 기본 dimension (단어의 차원)을 head_dim 차원으로 변환하는 선형 변환을 한다. 이때 head_dim = embedding_dim / num_heads 로 계산한다. (각 헤드의 차원 = 단어 차원 / 헤드의 수)
- Q, K, V 가 변환되었다면 여기에 따라 scaled dot product attention 하다. (위의 연산) 결과의 차원은 [batch, seq_len, head_dim] 이다.
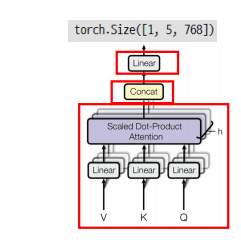
이제 이들을 반복 수행하고, concat 과 linear 연산을 수행하는 Multi Head attention 을 보자.
- 각 head 에 대해 scaled dot-product 을 적용한다. (나는 여기서 임베딩의 특정 부분을 정확히 슬라이싱? 하는 줄 알았는데, 그냥 헤드 수에 따라 Q,K,V를 head_dim 으로 바꾼다음 attention 적용한다. 이게 어떤 의미냐면... 정확히 디멘션의 어떤 부분을 어떤 헤드가 담당하는 게 아니라 이것마저도 학습에 맡기는 random 한 작업이란 이야기다. (random 하게 맡겨도 head 마다 다른 정보를 읽겠다.)
- head 의 수만큼 concat 한다. (dim = -1 로 지정하여 복구하면 다시 이것들을 이어 [batch, seq_len, head_dim X num_head = emb_dim] 으로 만들 수 있게된다.)
- linear 연산 한 번 적용.
✅ 2) Implementation of Feed Forward
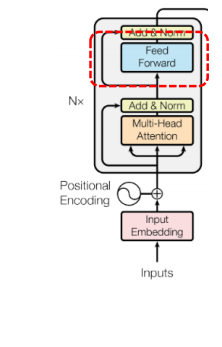
위의 구현에 해당하는 부분이다.
두 번의 선형 변환을 더 추가하고, GELU activation function 을 적용하게된다. 더 복잡한 관계를 잡아내는 것이 목표이다.
- 첫번째 선형 변환 (768 -> 3072) -> GELU
- 두번째 선형 변환 (3072 -> 768), Dropout

✅ Implementation of Add & Norm
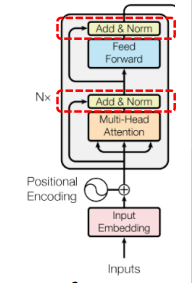
기존의 경우 add, Norm 이 Multi-head attention 과 MLP 사이에 적용하는 것으로 제안이 되었으나(Post-LN) 후에 Implementation 에선 LayerNorm -> Multi-head -> Add -> LayerNorm -> MLP -> Add 하는 식으로 LayerNorm 정규화를 먼저 시켜 안정화를 해주는 쪽으로 방향(Pre-LN)이 바뀌었다.

✅ 3) Implementation of Position Encoding
특정 위치에 대한 패턴을 학습 가능한 값을 더해주는 일이다.
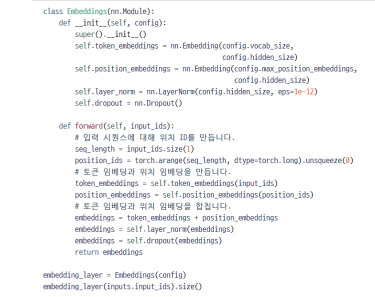
임베딩 자체를 서치하는 과정이 token_embedding, 포지션 임베딩을 구하는 과정이 position_embedding 으로 표현이 되었다. 따라서 구해지는 값은 임베딩 벡터와 포지션 벡터 2가지이며, 이를 단순하게 + 로 연결하면 된다! 그런데 어떻게 아무리 랜덤 -> 학습한다 하더라도 포지션 임베딩이 포지션을 나타내도록 학습할까? 단어 -> 인덱스 변환시에 이를 표현해주면 된다! 해당 문장이 들어오면 첫 단어는 인덱스1, 두번째 단어는 인덱스 2 .. 로 매핑하고 학습시키면 될 것이다.
✅ 4) Implementaton of Encoder

임베딩 레이어와 인코더 레이어를 연결하고, TransfomerEncoder() 를 최종적으로 실행하면 된다.
입력과 출력의 크기가 동일하게 출력되면 완성!
✅ 5) Implementation of Masked Attention
디코더에서 self-attention 을 쓰기위해서는 masked 까지 결합된 상태로 사용한다 하였다. (teacher forcing 할 때 예측을 뒷 단어를 보지않고 만든다.)
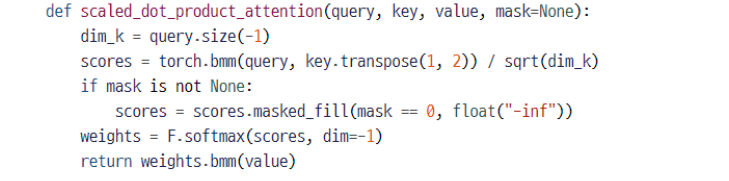
- 마스크가 none 이 아니라면 masked_fill 을 적용시킨다.
- 마스크에 해당하는 값인 0이 있으면 -inf 로 변환한다
- 마스크를 적용시키는 부분은 scores 를 구하고 weight 로 넘어가기 전 과정
Transformer Application
트랜스포머의 활용 부분을 보자. Transformer 기반의 언어모델을 보면서 마무리하자. 인코더만 가지고 만든 것도, 디코더만 가지고 만든 것도, 둘 다 사용한 것도 있다.
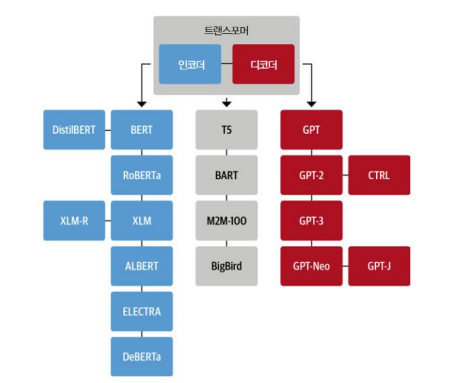
Transformer + Transfer Learning
전이학습이란 Pretrianing -> Fine tuning 과정을 의미한다.
여기서 사전 학습 언어모델의 대표격으로 Encoder 에는 BERT, Decoder 에는 GPT가 있다.
- BERT 의 경우 인코더에서 입력과 출력의 길이를 같게한 다음 한 단어를 mask 하는 방식으로 학습
- GPT의 경우 디코더에서 다음 단어를 예측하는 방식으로 학습
