본 포스팅은 아래의 한국어 음성 인식 관련 Langcon 2021 발표 영상 을 학습 목적으로 정리한 글입니다.
Speech Recognition
음성 인식 : STT
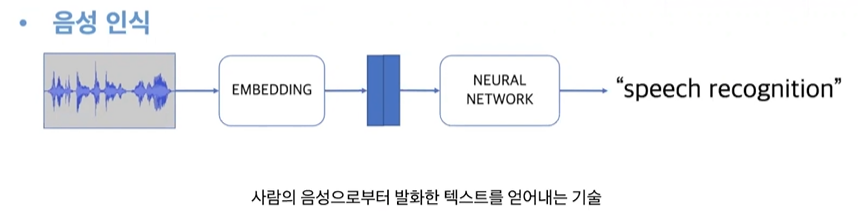
기능대화 음성인식: 사용자가 어느 질문/발화를 할 지 예측하여 이 범위에서 시나리오, 모델을 만듦.
따라서 일반 음성인식에서의 기술적 난이도는 시나리오를 예측할 수 없고, 노이즈에 대한 무한한 경우의 수.
End-to-End Speech Recognition
딥러닝 붐 이전의 음성 인식 방법은 다음과 같다.
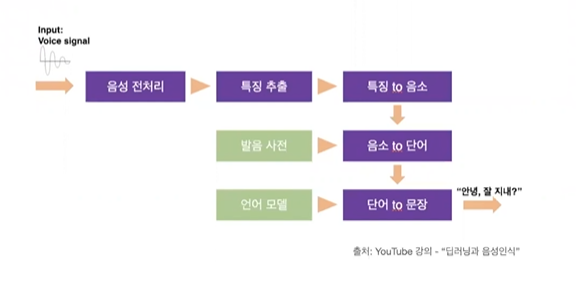
딥러닝 이후의 음성인식 방법. = End-to-End
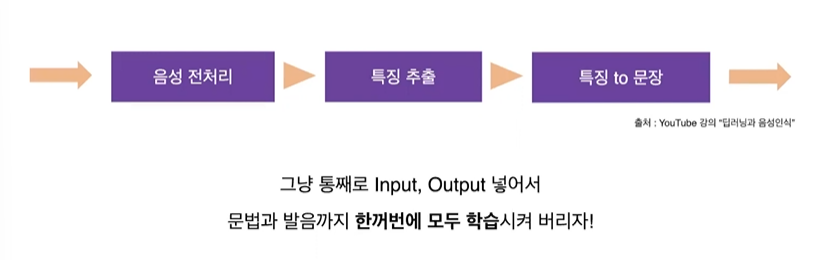
파이프라인은 다음과 같다.
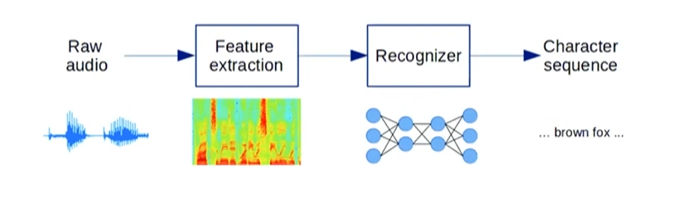
- 음성 신호: 16,000Hz 의 샘플링 레이트
- Feature Extraction: Raw 신호에서 Feature 뽑아줌. (Short time Fourier transform) => 20ms 프레임 / 10ms 겹치도록.
- Acoustic Modeling: 추출한 피처 => 전사 (신호와 텍스트 사이의 alingnment 를 알기 어렵다는 문제.) 이를 해결하기 위해 CTC 알고리즘과 Attention 메커니즘.
1. Connectionist Temporal Classification (CTC)
- ctc 는 loss이다!
- 피처의 시퀀스 길이 T > 타겟 시퀀스 길이 L
- T를 L에 전사시킬 때 가능한 모든 경로에 대해 계산
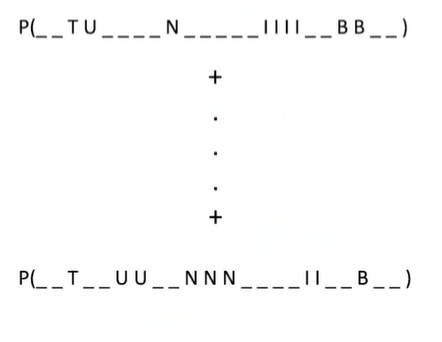
- T, U, N, I, B 가 타겟이면 피처의 시퀀스 길이 1000개에 이들을 어디부터 어디까지 매칭시킬 지 결정하는 것이다. 따라서 굉장히 많은 경우의 수.
- 위의 사진에서 _ 는 blank 이며, 클래스 간의 구분자 역할. (다른 글자 사이에 blank)
- 모든 경로에 대해 loss 를 계산하고, 줄이면서 학습.
- 미분 가능, 시간복잡도는 DP로 해결. O(n^3)
실제 Decoding 과정을 보자.
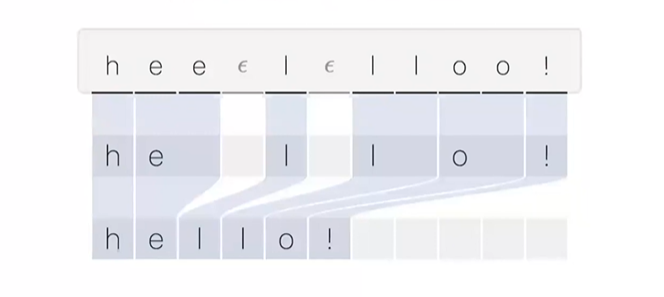
CTG 알고리즘을 사용한 에로는 DeepSpeech2가 있고, Decoder 가 따로 필요없다는 장점.
2. Attention
- 'Listen, Attend and Spell'
- RNN 기반 Seq2Seq 을 음성인식에 적용
- Cross-Entropy loss Function (분류 문제!)
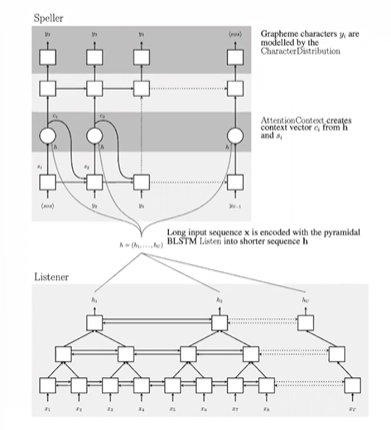
- 아래의 Listner 는 인코더이며, 음성 신호의 피처가 들어오면 high-level 피처로 변환해준다.
- 위의 Speller 는 Attention 기반 디코더이며, Listner 피처를 받아 글자를 디코딩하는 역할이다.
Attention 이 하는 역할은 시크널과 텍스트의 alignment 를 잡아주는 것이다.
3. Joint CTC-Attention
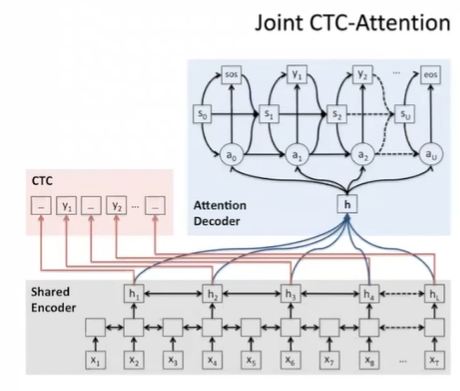
CTC 방식과 LAS 방식을 합친 방식이다. "Joint CTC-Attention" 논문에서 소개되었다. 아래 그림을 보면 알겠지만 인코더에 CTC, CE loss 을 모두 사용하여 오류를 줄였으며
- 인코더가 더욱 Robust
- 인코더-디코더 아키텍쳐에 적용할 수 있기 때문에 널리 사용되고 있다.
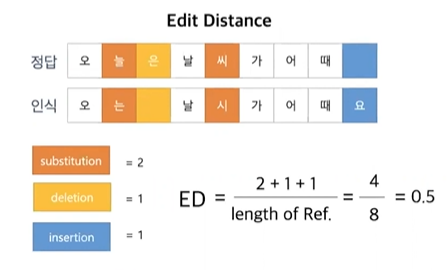
Metric
Character Error Rate (CER) 이라는 것을 사용한다.
전체적인 과정은 음성 신호가 들어오면 => Feature 로 변환하여 모델로 전송 => 모델은 피처를 high level 로 묶고 Decoding => Transcript 하는 순서로 이루어진다.
Korea Speech Recognition
데이터
- KsponSpeech 을 AIhub 를 통해 사용.
- KsponSpeech 에 대한 전처리 코드
Feature Extraction
- Feature Extraction 은 librosa 로 진행하였다.
모델
-
한국어 음성 인식 개발을 직접 진행하였다!
-
이때 학습하신 자료를 공유해주셨다. 자료
-
피처: Spectogram, Mel-Spectogram, MFCC, Filter-Bank
-
모델: Las, Transformer, DeepSpeech2, Jasper, Conformer
-
전처리/학습: Characte / Subword / Grapheme 에 대해 지원.
- OpenSpeech 추가 개발
- 실제 OpenSpeech 사용
- Librispeech 데이터, model 은 Conformer-lstm, 피처는 filter-bank 로 지정.
$ python3 ./openspeech_cli/hydra_train.py \
dataset=librispeech \
dataset.dataset_download=True \
dataset.dataset_path=$DATASET_PATH \
dataset.manifest_file_path=$MANIFEST_FILE_PATH \
tokenizer=libri_subword \
model=conformer_lstm \
audio=fbank \
lr_scheduler=warmup_reduce_lr_on_plateau \
trainer=gpu \
criterion=cross_entropy2가지만 설정해주면 모델이 포함하고 있는 하위 configuration 은 자동으로 로드. (따로 지정해주면 그 configuration 으로 로드)
다른 Dataset 에 OpenSpeech 를 이용하여 학습하려면 어떻게?
- 데이터 전처리 코드 작성. (Manifest file, Vocab file)
- LightningDataModule 정의

- LightningDataModule 정의
