[NLP] BERT (Bidirectional Encoder Representation from Transformers
[Natural Language Processing]
BERT 이전의 흐름
워드 임베딩 방법론으로는 다음이 있다.
- 임베딩 층을 랜덤 초기화 한 후 처음부터 학습
- 사전 학습된 임베딩 벡터를 가져와 사용
이러한 임베딩을 사용한 것이 Word2Vec, FastText, GloVE 인데, 두 방법 모두 하나의 단어가 하나의 벡터값에 고정적으로 매핑되므로 문제.
예컨대 '사과'라는 동음이의어에 대해 다른 문맥에서 쓰인 다른 의미를 인코딩하지 못하고 같은 숫자 입력을 부여할 것이다.
이후에는 언어 모델링에 있어서 pre-training 방법론이 대두되었다.
- Pretrained 언어모델 = 학습 시 별도 레이블 필요 X
- LSTM 을 가지고 학습하고나서(unsup.) 텍스트 분류에 추가학습.(sup) = Semi-Supervised
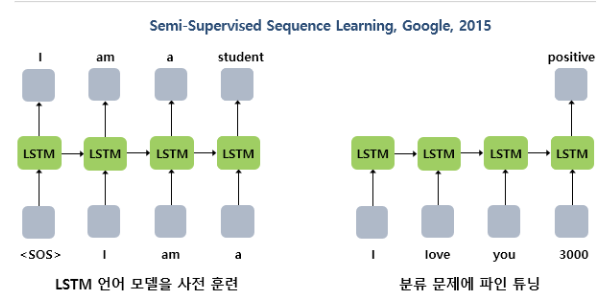
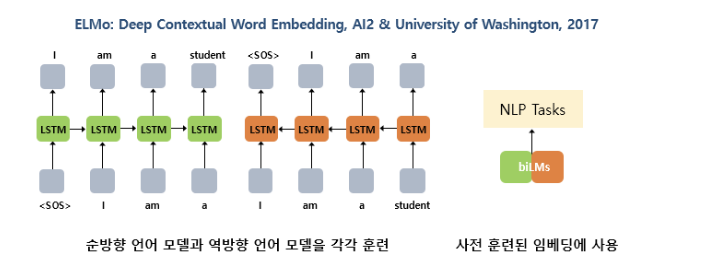
ELMo 역시나 사전 학습된 언어모델로부터 임베딩 값을 얻는다는 아이디어이다. (훈련은 순방향, 역방향으로) 문맥에 따라 달라지는 벡터값으로, 기존의 문제 해결.
추가로 RNN, LSTM 을 뛰어넘는 Attention 만을 사용한 트랜스포머의 등장으로, 트랜스포머로 사전 훈련된 언어 모델을 학습하는 시도가 등장했다.
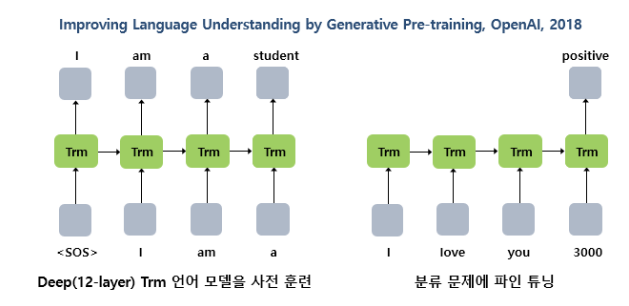
Trm 이라고 하는 트랜스포머를 결합하여 이전 단어로부터 다음 단어 예측. 총 12개의 층을 쌓은 GPT-1. 이와 같이 NLP에있어서 언어 모델을 사전훈련 시키고, 이후 특정 task 에 추가 학습시키는 방법이 주가 되었다. (사전 학습에 있어서는 꾸준히 변화)
기존 사전훈련 방법과 달리 언어의 문맥은 양방향이므로 이전 단어만 보고 결정하는 것이 아닌 양방향 구조를 도입한 Masked Language Model 이 등장했다. BERT 의 시작이다.
BERT(Bidirectional Encoder Representations from Transformers)
BERT 는 트랜스포머를 기반으로 구현되었으며, 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다. BERT 를 가지고 다른 작업에 fine-tuning 하면 굉장히 높은 성능을 기록할 수 있음이 입증되었다.
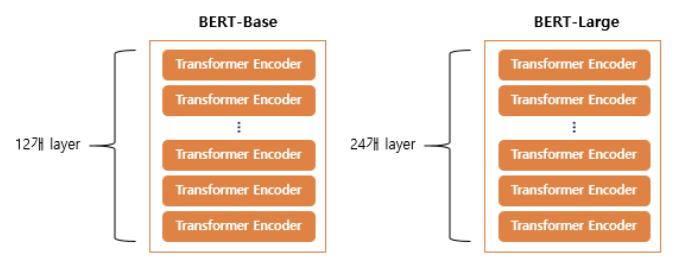
BERT 는 이전에 학습한 트랜스포머의 인코더, 즉 언어 모델링 단계를 쌓아올린 구조이다.
- Base 의 경우 12층, d_model = 768, attention head = 12 ; 110M parameteres
- Large 의 경우 24층, d_model = 1024, attention head = 16 ; 340M parameteres
초기 트랜스포머 모델의 경우 6층에, 512 디멘션, 8개의 헤드였던 것과 비교하면 base 자체도 트랜스포머보다 거대한 모델인 것을 알 수 있다.
Contextual Embedding
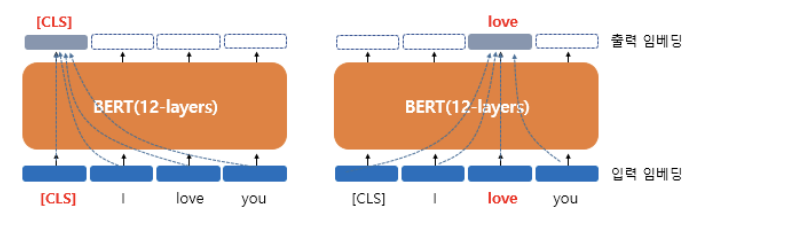
- 각 단어에 대해 768 차원의 벡터 출력
- 출력은 문맥 정보를 가진 벡터 (모든 단어를 참고)
- 하나의 단어가 모든 단어를 참고하는 연산을 12층에서 수행
모든 단어를 참고하는 방법은 Self-Attention 이다.
Subword Tokenizer: WordPiece
Subword Tokenizer 란 말 그대로 문장을 분석하는데 있어서 단어를 단어보다 작은 단위로 쪼개는 것이다. WordPiece 토크나이저를 사용했으며, 글자로부터 서브워드들을 병합해 나가는 방식으로 vocab 을 만든 토크나이저이다.
만든 단어 집합을 기반으로 토큰화를 수행한다. = 대표적인 토크나이저 패키지인 SentencePiece 를 이용해보자!
- 이미 훈련 데이터로부터 만들어진 단어 집합 존재
- 토큰이 단어 집합에 존재하면, 분리하지 않는다
- 존재하지 않으면, 서브워드로 분리하고, 첫번째 서브워드를 제외한 나머지 서브워드 앞에 ## 을 붙인다.
실습해보자!
import pandas as pd
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") # Bert-base의 토크나이저
"Here is the sentence I want embeddings" 라는 문장을 토큰화해보자.
result = tokenizer.tokenize('Here is the sentence I want embeddings for.')
print(result)
embeddings 라는 단어가 존재하지 않으므로 아래와 같이 분리되었다.
단어가 존재하는지 여부는 tokenizer.vocab['확인할 단어'] 로 확인할 수 있다.
반대로 어떤 단어가 존재하는지 단어 집합 자체를 저장해볼 수 있다.
# BERT의 단어 집합을 vocabulary.txt에 저장
with open('vocabulary.txt', 'w') as f:
for token in tokenizer.vocab.keys():
f.write(token + '\n')
df = pd.read_fwf('vocabulary.txt', header=None)
df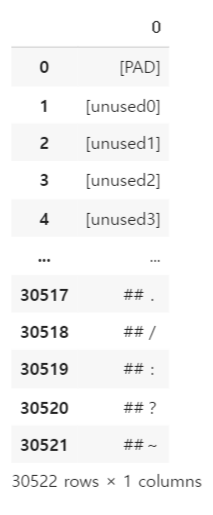
총 30,522 단어가 존재한다!
이 안에 특별 토큰들은 다음과 같이 존재한다.

Position Embedding
BERT 에서는 위치정보를 사인, 코사인 함수로 만드는 것이 안니 학습을 통해서 얻는 Position Embedding 방법을 사용한다.
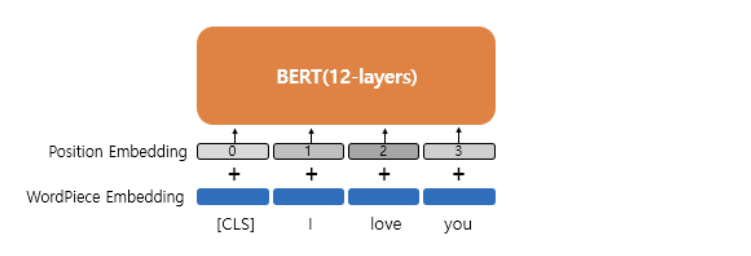
위치정보를 위한 임베딩 레이어를 하나 더 사용해 입력마다 포지션 임베딩 벡터를 더해주면 된다. 실제 BERT 에서는 문장 최대 길이가 512이므로, 총 512 의 포지션 임베딩 벡터가 학습된다.
BERT Pre-training
- ELMo 는 정방향, 역방향 LSTM 을 각각 훈련시켜 양방향 모델을 만들었다
- GPT-1 은 이전 단어들로부터 다음 단어를 예측했다
- BERT 는 한 단어를 계산할 때 모든 단어를 사용한다.
- masked language model
- Next sentence prediction
두 가지 방식을 통해 학습하였다.
1. Masked Language Model (MLM)
2. Next Sentence Prediction (NSP)
Segment Embedding
