
Abstract
setence embedding 에 대해 다룬 논문.
- 문장 임베딩과 다르게 성능을 올리려면 labelled data 필요. (그 도메인에 라벨 데이터가 많은지)
이 논문에선 DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations 제시.
- labelled training data 필요없는 문장 임베딩 위한 self-supervised objective 제안
- 트랜스포머 베이스의 pretraining 에 사용할 경우 인코더에 관해 unsup 의 성능을 sup 가까이까지 올림.
1. Introduction
transfer learning(전이학습)의 등장은 NLP 수행에 있어서 라벨 데이터가 충분하지 않았기 때문이다. 그러나 워드 임베딩을 학습하는 전이학습 역시 한계를 보였고, 최근 연구들은 pretrained sentence embeddings 베이스로 높은 성능을 내기도 한다.
- 고정 길이 벡터 = sentence embeddings 은 large corpora 에서 얻어지고 전이학습을 통해 보완
- 본래 문장 임베딩은 라벨 데이터가 성능을 위해 필수적인 요소였음.
- 그러나 이후 unlabelled corpora 를 활용한 pretraining 의 등장.
- 아이디어 자체는 masked language modelling(MLM), 토큰 레벨의 self-supervised 에서 가져옴. => 문장 레벨의 self-supervision.
- BERT 의 NSP가 roBERTa 나 ALBERT 에서 효율적이지 않음이 밝혀졌고, 따라서 단순하지만 효과적인 self-supervised, setence-level objective 제안.(Metric Learning 에서 가져옴.)
Metric Learning 이란 비슷한 데이터의 표현은 가깝게 표현 공간을 학습하는 방법을 의미. (CV 쪽이나 deep metric learning 에서 널리 사용.)
- "pretext" task 가 유용한 표현을 만들어내도록 잘 만들어져야 한다.
- 유용한 표현이란 down stream 에 잘 적용됨을 의미
- anchor 와 positive data points 사이 거리를 negative data points 사이 거리보다 가깝게 학습.
- 높은 성능을 낸 방법으로는 같은 이미지를 augmenting 하여 anchor-positive 를 만들고, anchor-negative 는 다른 이미지를 augmenting 하여 만든다. (Bachman et al., 2019; Tian et al., 2020; He et al., 2020; Chen et al., 2020).
따라서 정리하면, 문장 인코더를 pretrain 하는데에 self-supervised, contrastive objective 사용. 같은 문서에서 랜덤하게 샘플링된 세그먼트는 거리를 가깝게 학습.
- MLM 과 함께 사용할 self-supervised sentence-level objective 제안 (라벨 데이터 없이 문장 임베딩 학습)
- 높은 퀄리티 임베딩을 위해 중요한 요소 제시
- 퀄리티는 모델과 데이터 사이즈에 의해 정의. (= 라벨 없는 데이터가 많거나 큰 인코더라면 성능 향상 가능)
- open-source solution!
2. Related Work
Supervised or semi-supervised
문장 인코더에서 높은 성능을 기록한 것은 NLI, Stanford NLI, MultiNLI 에서 pretrained 된 모델들.
NLI란?: 페어 문장(hypothesis - premised) 를 세가지 관계로 분류 (entailment, contradiction, neutral)
- 이 외에도 semi-supervised (데이터는 unsupervised 하게 augmenting, SNLI corpus 에서 supervised training)
- 트랜스포머나 BERT 역시 NLI dataset 사용.
Unsupervised
Skip-Thoughts 나 FastSent 가 문장 임베딩을 학습하는 유명한 unsup 기술이다. (이웃 문장을 예측하는 방식으로 인코딩) => 문장의 표현만 학습하고 의미를 잡아내는데 실패.
QuickThoughts 의 경우 simple discriminative objective 제시 (문장과 그 문맥이 주어질 때 분류기가 해당 문장이 해당 문맥에서 나온 것인지 아닌지를 바탕으로 문장을 학습)
논문의 접근은 Sentence Transformers 와 유사. (문장 임베딩을 만들기 위한 pretraining 으로 트랜스포머 베이스의 모델 사용)
- 그러나 objective 자체를 self-supervised 로.
- objective 는 QuickThoughs 와 유사.
- anchor 당 단 하나 또는 여러 개의 positive segments 로 확장.
- segment 끼리 인접, 포함 가능
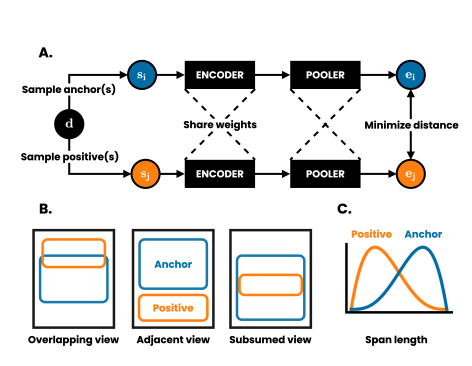
A: 배치 안에서 하나의 문서에서 앵커 span 과 positive span 을 샘플링. 두 span 모두 같은 인코더로 투입, pooler 는 상응하는 임베딩을 만들어냄. (이 둘의 임베딩 사이의 거리를 최소화하도록, 배치의 다른 임베딩의 거리는 멀리)
B: positive span 자체는 overlap, adjacent, subsume 가능.
3. Model
3.1 Self-supervised contrastive loss
목표는 contrastive loss 로 같은 문서에서 샘플된 textual segments(span) 은 표현을 가깝게 학습하는 것이다. 구체적인 과정은 아래와 같다. (위의 그림을 참고하자)
-
data loading step: 배치사이즈 N에서 각 문서에서 랜덤하게 anchor-positive pair 을 추출한다. 문서당 추출된 anchor span 개수는 A (1 ...AN), 앵커당 추출된 positive span 개수는 P (1..P), 따라서 positive span 은 Si부터 S(i+pan) 으로 정의된다.
-
encoder: f() 는 인풋 sapn 의 각 토큰을 임베딩으로 매핑한다. (여기에선 transformer base encoder 사용)
-
pooler: g() 은 인코딩된 span f(Si), f(Si+pan) 을 고정길이 임베딩인 과 이에 상응하는 mean positive 임베딩인 아래와 매핑한다. (i번째 앵커 임베딩과 이에 해당하는 P개 positive span 의 평균) 따라서 g()를 통과하면 각 앵커의 토큰 임베딩들, positive pair 의 토큰 임베딩들이 pool 즉 문장 임베딩으로 평균내어질 것이다.
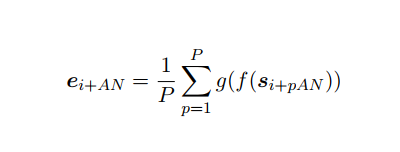
-
contrastive prediction 을 위한 loss는 임베딩 span 하나가 positive pair 와 를 포함. 앵커 주어질 때 안에서 e(i+an) = 을 positive 로 학습하는 것이다.
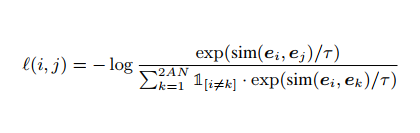
-
미니배치에는 N개의 문서 포함. (따라서 총 AN개의 anchor) N개의 각 문서에서 anchor(ei)-positive pair(e(i+an)) 추출. 따라서 총 2AN개의 data points. 하나의 문장이 있다면 2(AN-1) 개의 문장들은 모두 negative examples 로 간주.
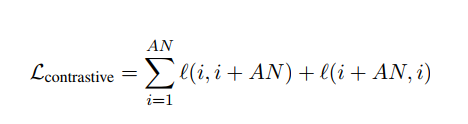
(normalized temerature-scale cross entropy loss 사용)
3.2 Span sampling
그렇다면 span 길이는 어떻게 할 것인가? (p개의 span 을 평균내어 positive pair 로 보았다. 하나의 스판 길이를 말하는 것.) 논문에선 최소 32, 최대 512로 설정하였다. 문서 d는 문서 하나당 n개의 시퀀스 토큰으로 구성되었다.
아래는 설정을 위한 식이다. 문서 하나에서 앵커 스판 를 샘플하기 위하여, 먼저 beta 분포로부터 앵커의 길이를 가져오고, 시작 위치를 가져온다.
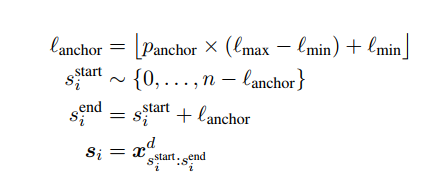
다음은 이에 상응하는 positive span 을 설정하기 위한 식이다. (위와 논리가 같다.)
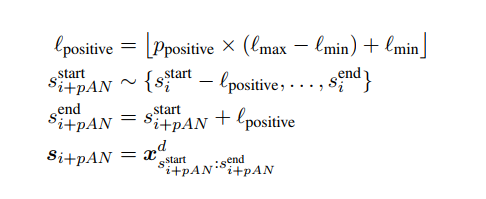
결론적으로 이러한 과정은 세가지 유형의 positive 를 만들 것이다. (anchor 을 overlap하거나, adjacent 인접하거나, subsumed 아예 포함되거나) 그리고 두가지 유형의 negative 를 만들것이다. (미니배치에서 다른 문서에 존재하거나 같은 문서 내 negative 거나)
3.3 Continued MLM pretraining
최종적으로 Loss 를 사용할 땐 MLM objective 를 포함했다.
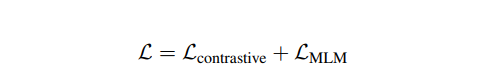
또한 처음부터 이 Loss 를 쓰지는 않고 MLM 으로 pretraining 한 다음 위의 식을 썼다는 것을 알아두자! (논문에선 RoBERTa- DeCLUTR base가 된다, DistilRoBERTa- DistilRoBERTa가 된다. 를 사용했다.)
4. Experimental setup
Dataset
OpenWebText 에서 최소 2048 토큰 길이가 되는 것들을 가져다 사용했다.
reference 를 위해서는 SNLI 가 사용되었고, InferSent 와 Sentence Transformer 모델은 SNLI, MultiNLI 로 훈련하였다.
Implementation
파이토치 라이브러리의 NT-Xent loss function 를 사용했다. 트랜스포머 라이브러리에서는 pretrained transformer 를 가져다 사용했다.
Evaluation
고정 길이 문장 표현을 평가하기 위한 SentEval benchmark 의 모든 방법을 사용하였다.
Baselines
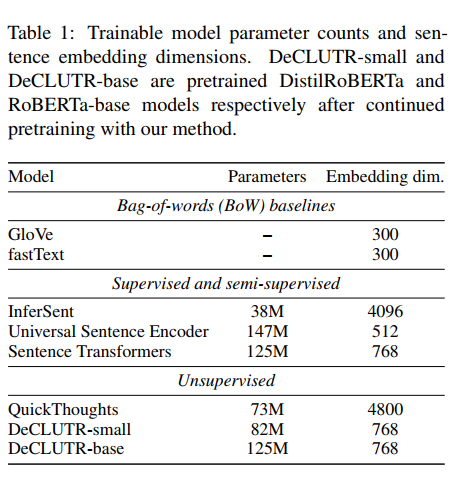
문장 임베딩 방법 중 기존에 성능이 좋았던 것들과 비교했다.
- InferSent
- Google's USE
- Sentence Transformers
- GloVe 와 fastText 의 워드벡터
- Transformer-로 표기하여 pretrained 만 된 트랜스포머와 비교. 이후에 mean pooling
5. Results
어떤 요소가 임베딩의 퀄리티에 기여했는지 집중하여 살펴보자.
5.1 Comparison to baselines
Downstream task performance
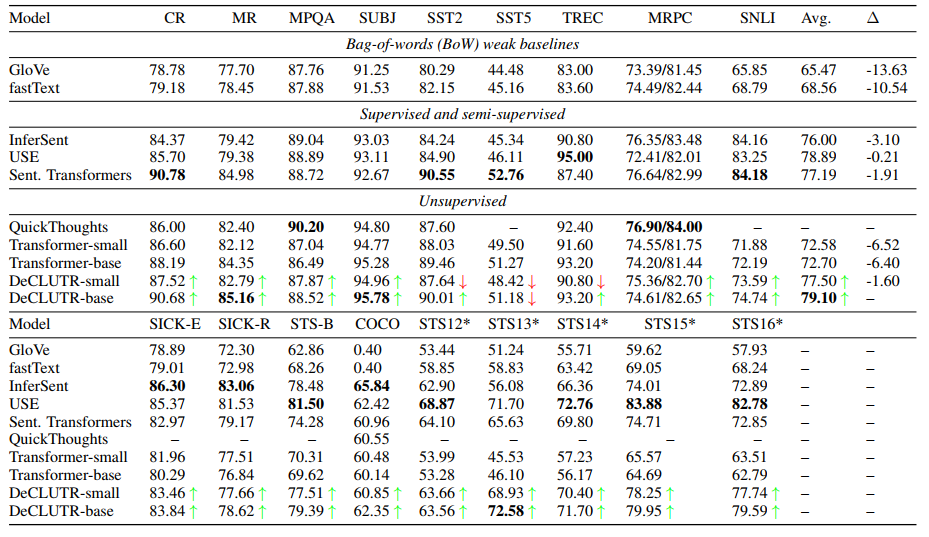
pretrained model 인 DistilRoBERTa(Transformer-small) 와 RoBERTa(Transformer-base)와 비교했을 때, DeCLUTR-small 과 base 모두 평균 downstream task에서 성능이 향상되었다. (놀랍게도 small 의 경우 34%나 적은 파라미터를 사용하고도 Sentence Transformers 보다 높은 성능을 보였다.)
Probing task performances
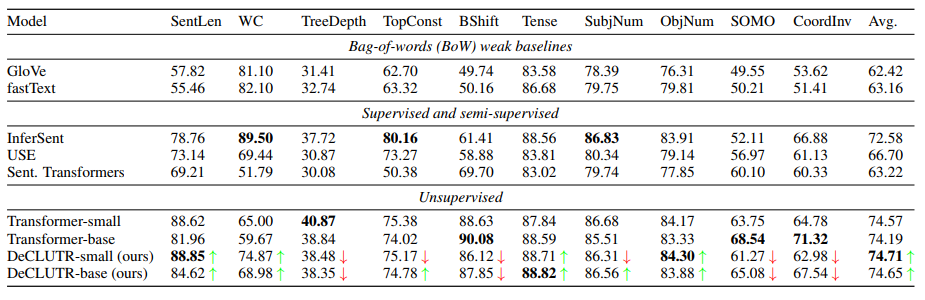
트랜스포머의 경우 파인튜닝과 비교했을 때 10%나 낮은 probing tasks 점수를 기록했으나, DeCLUTR 방법 두 가지 모두 평균 점수에서 pretrained model 의 점수와 비교했을 때 그정도로 하락을 보이진 않는다. 이 결과는 파인튜닝 트랜스포머 모델이 pretrained 정도만 끝냈을 때와 비교했을 때 얻은 언어적 정보를 버린다는 것을 보여주기도 한다. 아마 DeCLUTR에서 상대적으로 높은 성능을 기록한 것은 MLM objective를 포함했기 때문.
Supervised vs. Unsupervised downstream tasks
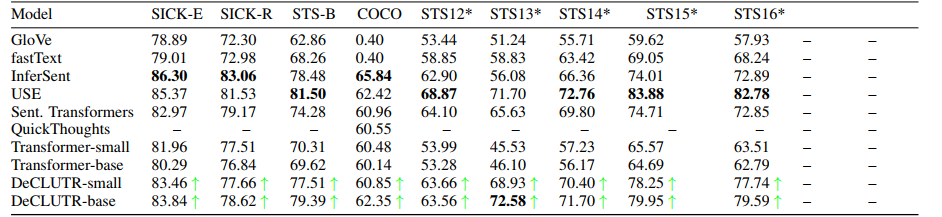
SentEval 에서 downstream 에 대한 평가는 지도학습과 비지도학습 모두에 대해 이루어진다. 흥미롭게도 USE 가 가장 높은 성능을 기록했다.
5.2 Ablation of the sampling procedure
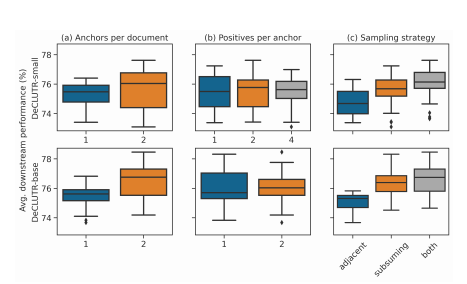
샘플링 과정에서 몇 가지 분석을 진행했다. 문서 당 앵커의 개수를 A, 앵커당 샘플 개수를 P라 하자.
-
A = 2 일 때, A = 1 일 때보다 span 두 배의 개수에 대해 훈련하게 되고 하나의 배치 사이즈에 대해 2배 효율적이게 된다.
-
따라서 A = 1 인 배치는 두 번 에폭을 돌기로 했고 배치 사이즈도 2배 늘려서 smae number of spans, same effective batch size 를 유지하도록 했다.)
-
추가적으로 문서당 앵커의 개수를 여러 개로 하는 것이 좋고
-
앵커당 positive 의 개수는 크게 영향을 주지 않으며
-
adjacent 과 subsumed 를 같이 사용하는 것이 하나만 사용하는 것보다 좋음을 밝혔다.
5.3 Training objective, train set size and model capacity
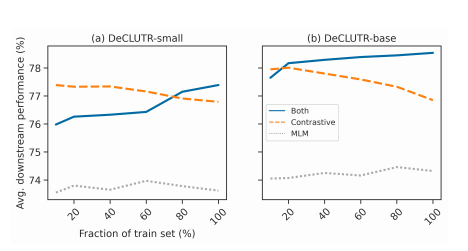
MLM + contrastive 둘 다 사용하여 pretraining 한 것이 하나만 사용한 것보다 좋은 성능을 보였다. MLM 을 함께 사용하는 것은 규제의 역할을 하여 pretrained 후에 모델이 급작스럽게 가중치를 변화시키는 것을 막았을 것이다. (데이터가 커질수록 해당된다.)
이는 모델의 수용도나 데이터 크기의 스케일에 따라서 임베딩의 퀄리티가 결정된다는 것을 뜻한다.
6. Discussion and conclusion
정리하자면, 이 논문은 self-supervised objective 로 universal sentence embeddings 를 학습하는 방법과 결과를 다룬다. 트랜스포머 베이스의 pretraining 된 모델과 함께 사용되었을 때, 라벨을 사용한 지도학습 성능과의 격차를 더 줄여냈다.
또한 추가적으로 임베딩 퀄리티는 모델과 데이터 사이즈에 따라 더욱 향상될 수 있음을 보였다.

공감하며 읽었습니다. 좋은 글 감사드립니다.