Big Health Data
- 데이터 수집 기술의 발달 > 건강 데이터 역시 디지털화.
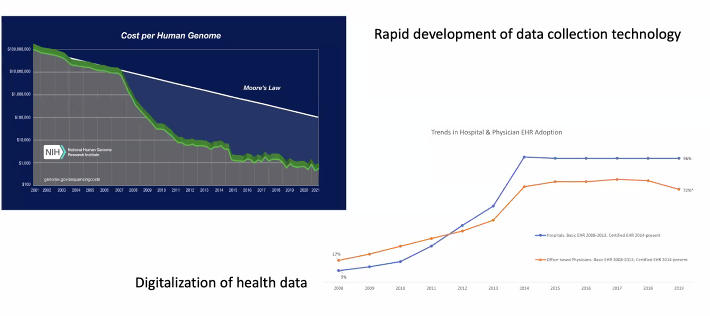
- '빅헬스데이터' 라 불릴만함!
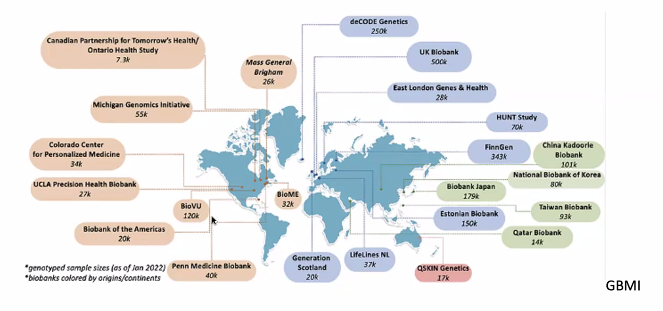
Mega Biobank: Genome + EHR + Biomarkers
- 데이터베이스의 합을 말함.
- 전 세계에 Biobank 가 퍼져있다고 봐도 좋으며, 미국이 가장 큰 시장.
why Genom Data?
- 많은 사람의 특성이 유전자로 파악 가능하기 때문.
- 키, 질병, 심장 등등..
- 각각의 특성이 유전자와 얼마나 깊게 연관되어 있는지. (키는 80%이다.)
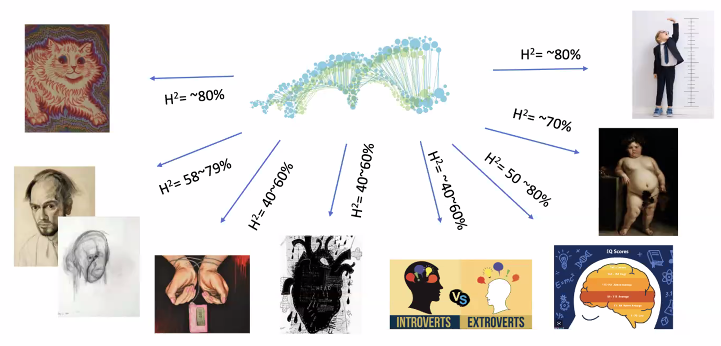
- 심장질환, 당뇨의 경우 40-60
- 치매의 경우 58-79.
- 개인의 하이리스크와 로우리스크 예측.
Genetic Variants
-
두 개의 카피가 쌍을 이룬다.
-
모두 같은 쌍을 같지만 하나만 다른 것을 Mutation 이라고 한다.
-
보통 0과 1로 표기한다.
-
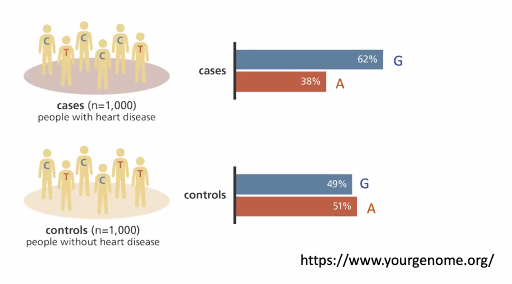
그다음 Association Analysis 를 진행하고 / G가 더 높은 쪽이 질병이 더 많다면
-
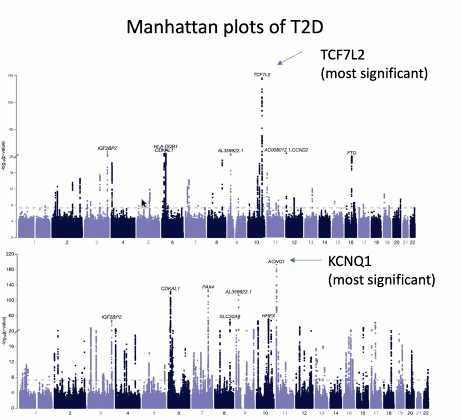
Genome-Wide Association Studies 로 시각화를 진행. 게놈의 위치에 따른 p값이다. (확률을 보는 것.)
-
Scalable and Accurate Association Test
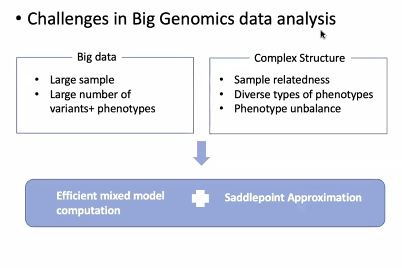
-
효율적인 모델 계산 + Saddlepoint Approximation
-
Application to Biobank Data - KoGES
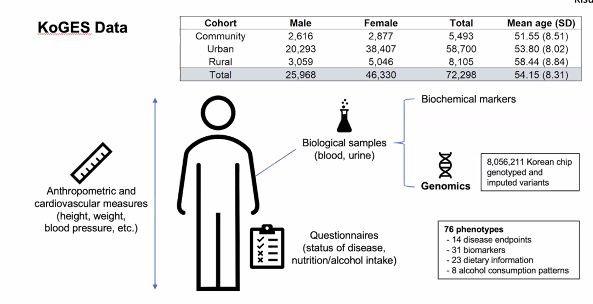
-
Number of Associated Variants and Pleiotropy
-
Result Visualization (특성에 따른 질병과 관련된 확률)
-
Genome-based Risk Prediction
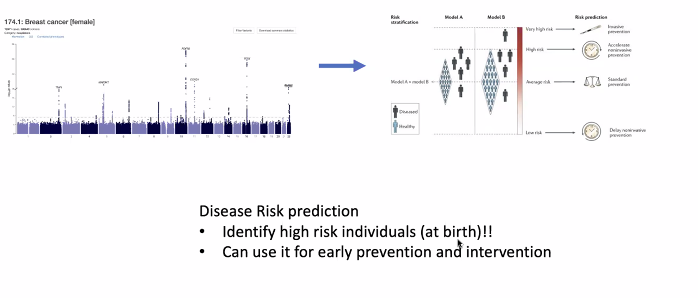
-
태어날 때 계산
-
예방과 치료.
-
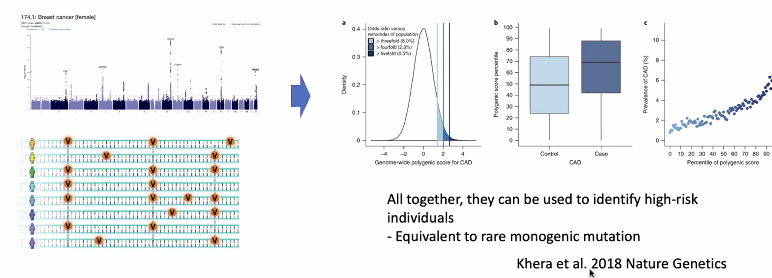
BRCA1 는 DNA 손상과 관련되어 있다고 밝혀졌고, Mutation Prevalence 가 0.2-0.3% 되었다.
-
여성의 경우 변이의 위험이 더 높았다.
-
실제로 유방암 유전자를 물려받은 안젤리나 졸리.
-
예방에 사용.
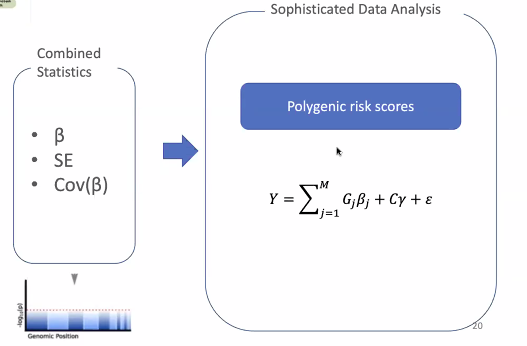
Polygenic?
- 어떻게 피처들을 조합할 것인가?
- 한 데 모아 예측
- 점수?

- 선형 모델 / 변수 개수, 각각의 타입, 효과 사이즈를 의미한다.
- PT: pruning threding
- Lassosum: 라쏘 제한
- PRS-CS: 베이지언 축소
- 흥미로운 점은 오직 선형 모델만 사용하고 딥러닝까지 가지 않는 다는 것.
- 개인수준의 데이터를 모으는 것은 어렵기 때문이다.
- 딥러닝 접근은 선형이 아닌 것, 피처간 상호작용이 큰 것에 사용할 수 있는데 그러한 증거가 없기 때문이다.
요약
질문들
- Cross-ancestry: 다른 세대에 관해선 어떻게 적용?
- Incorporate variant functional information?
- Effectiveness of PRS : 모델을 평가하는 PRS 의 유용성에 대한 질문.
- 인종에 따라 다를 수도 있다. (확률이 큰 특성이 다르다.)
PRS 를 따라서 인종에 따라 다음과 같이 바꿔서 계산할 수도 있다.

이를 확장시키면 다양한 인종에서 PRS 결과를 계산할 수 있다!
전이학습
데이터셋1으로 만든 모델의 지식을 모델 2에게 전달하고 모델 2는 데이터셋 2로 또다시 훈련.
에포크의 수를 제한하는 정규화 과정이 필요하다.
경사하강법 기반의 튜닝 접근이 요구된다!
전이학습 PRS
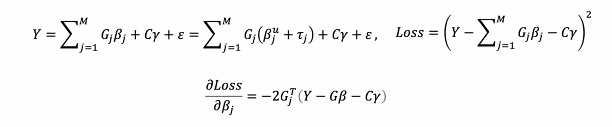
기존 모델을 새롭게 업데이트.

- 이후에 learning rate, early stopping 튜닝.
