Era of Large Language Models
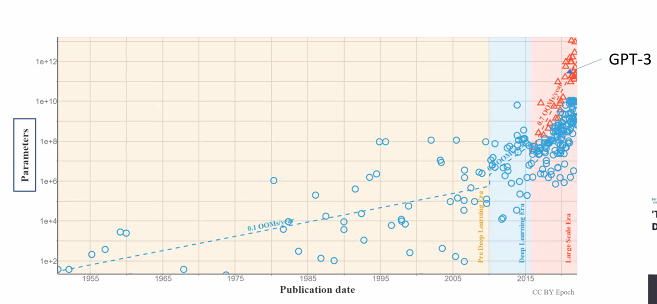
또한 chatGPT의 경우 사람들에게 도달하는데 몇 주밖에 걸리지 않았다.
What LLMs can do
- Search
- Conversation
- Contents creation
- more...
Noam Chompsky: The False promise of ChatGPT 를 봐보자.
ACES: Accuracy Challenge Sets for Evaluating Machine Translation Metrics (의도적으로 틀린 데이터 형성)
GPT-4
- annotated 예시들을 매우 잘 활용한다.
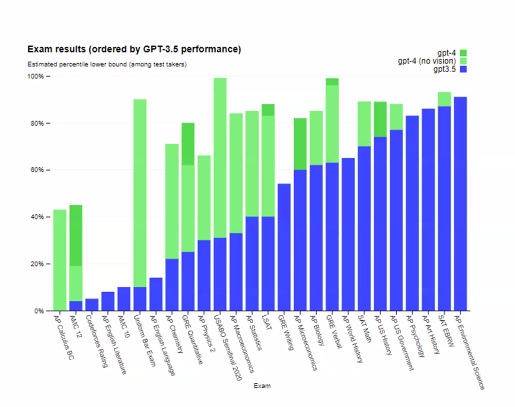
- 푸른색은 3.5, 초록색은 gpt-4 이다.
- 스크린샷을 제공하고, 그것으로부터 요약을 제공하는 게 가능해졌다.
- Vision + text input = text output 의 처리가 가능해졌다.
- Vision 과 no vision ver 가 있다.
- 사진을 주면 언어로 설명 ... 등등 사진만 보고 동작 가능.
- 사진에 있는 농담도 이해가 가능하다.
- 이미지, 텍스트, 문제해결이 모두 가능하고 한 문제 내에서 처리가 가능하다는 점.

What's interesting about MT?
- 1950년대에는 Rule based 였다.
- 기술이 진보하면서 통계학적 모델을 갖추게 되었다.
- 2014 년엔 Seq2Seq. 인코더와 디코더가 존재.
- 2015 년에 Attention mechanism. 중요도에 따라 가중치를 가공함.
- 2017 년에 Transformer. (Attention 을 인코더와 디코더로 사용.)
- 2020 Mixture of Experts
- 2020 GPT-3
- 2022 PaLM
다른 나라의 문화적 측면을 고려한 MT!
MT 와 Language Modeling (GPT)
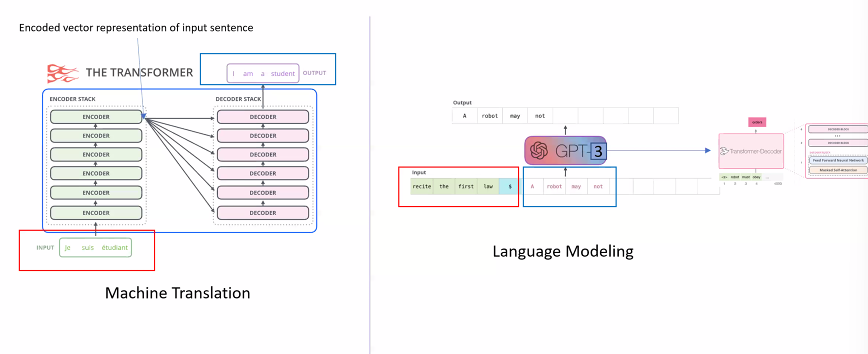
-
인코더의 끝에는 은닉층, 디코더로 전달. 단어를 주어진 문맥을 고려하여 최종 만들어냄 (word-by-word generation)
-
인풋은 텍스트, 문서, 그리고 다음 문자를 그저 예측하는 LM.
둘은 많이 다를까?
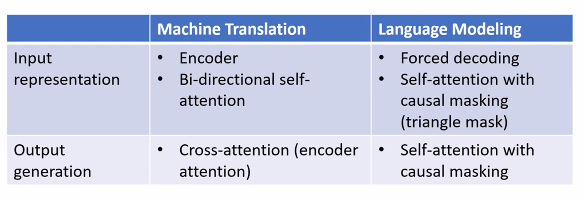
LM 은 MT 의 인코더-디코더의 심플화이다!
How good?
WMT 데이터셋을 사용했다. (주요 유럽 언어를 커버하기 위해 사용)
- 평가 모델로는 Automatic Evaluation 을 사용.
- 오픈소스 Comet 2022, CometKiwi
- 사람의 평가도 활용했다. (코멧이 할 일을 못할 때) = DA + SQM
X > English > German, Chinese, Russian, French-German
-
Text-davinci-003 이 조금 더 나앗다. (이해에 관해서는)
-
예와 함께 더 좋은 성능을 보임 (In context Learning Performance)
-
One-shot 이 때때로 five-shot 보다 성능이 더 좋았다. (퀄리티가 더 중요)
MT-GPT Hybrid Translation
- 일단 MT 실행
- 결과를 점수 매긴다
- 평가하고 비교한다.
- 만약 만족스럽지 않다면 GPT 를 호출, GPT 의 결과와 비교하여 나은 것 선택.
인간 평가에 따르면 성능은 다음과 같다.
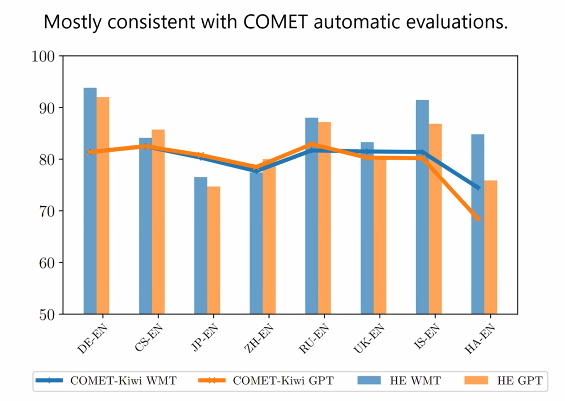
어떻게 다른가?
모델의 편향성이 다르다.
-
패턴 매칭을 시도한다. 소스- 타깃의 페어를 맞추는 것으로. 단어단위와 구 단위로.
-
반면 GPT 모델은 그저 높은 퀄리티의 문서를 학습한다. 패러프레이징!
Non-monoticity
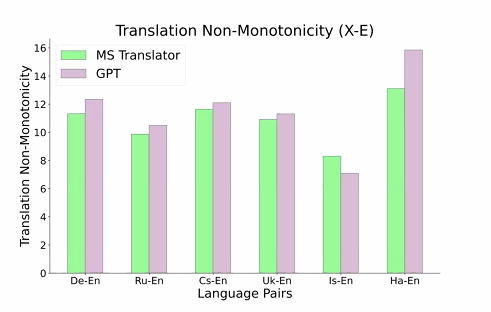
GPT 는 인풋을 문맥화하고, 문장을 만드는 역할을 수행한다. 단어 단위 매핑을 하는 것은 아님.
Fluency
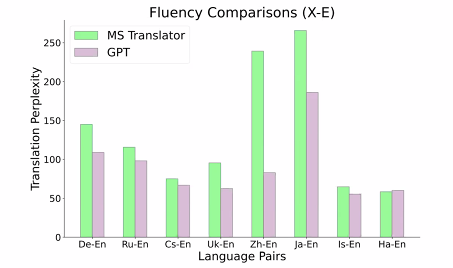
Punctuation Insertion

Punctuation 에 관해서는 더 정확하게 다뤘다!
Drpoped Content

Insert Content

How GPT models could reach here?
MT의 문제 - Translationese
문장의 페어가 학습에 있어서 중요했다. 인간의 annotations 는 매우 달라서 찾기가 힘들었다. 몇 문장은 아예 번역이 어려웠다.

Longer Context
길어진 글도 문제였다. > GPT 는 긴 문서에 대한 학습을 통해 긴 시퀀스의 해석을 제공하는 것이 가능했다.
Knowledge Transfer
데이터가 충분하지 않았다. > GPT 는 어떻게 문장, 문서를 쓰는지 학습했다. 매우 적은 수의 문서로도 가능.
Generalization
매우 추상적인 문맥을 만드는 것이 어려웠다. > GPT 는 매우 일반적인 태스크 위에서 형성된다.
Scaling
- 높은 수준 데이트
- 더 일반적인 모델
- 스케일
Conclusions
- GPT 모델은 기계 번역을 지도되지 않고도 배울 수 있다.
- 이미 예술의 경지에 다다랐다.
- 더 부드러운 결과, 그러나 정확도와 타협할 순 있다.
연구의 방향
- LLMs 을 활용한 연구가 활성화될 것으로 보임
- 문맥 안에서의 학습
- 사실 기반에서 성능을 올려야 함
- 아웃풋 길이, 스타일을 조절해야 함.
What's coming
We should adapt to the radical transformation that is occuring.
We see this is a bigger change than the transformation from feature engineering to depp learnig.
해당 포스트는 서울대학교 데이터사이언스 대학원이 주최한 세미나, 김영진 박사님의 "How Good Are GPT Models at Machine Translation?; Why?" 세미나를 바탕으로 제작된 것입니다.
