
지식 그래프 생성에 관한 다음 논문 을 읽고 정리한 글.
Abastract
present a fully data-driven pipeline for generating a knowledge graph (KG) of cultural knowledge and stereotpyes (문화 지식과 stereotype 지식 그래프를 만들어내기 위한 파이프라인에 관한 논문)
- 5 religious groups, 5 nationalities.
- 다수의 non-singleton entries are coherent, complete stereotypes
- performing intermediated masked language model training on the verbalized KG (지식 그래프 기반으로 학습한 모델)
- leads to higher level of cultural awareness + increase classification performance on knowledge-crucial samples on task(detection hate speech)
1. Introduction
기계학습 연구에서 중요한 연구: model-inferent bias 에 대항하는 Fairness, accountability, transparency
Stereotype 을 포함하지 않을 경우 >> lead to inferring traits of individuals from their status or social group. >> systemic discrimination 의 문제가 있음. 따라서 bias reduction 을 위한 워드 임베딩, 분류 작업 필요.
- 과거엔 predefined lexicons 로 작업함.
- 이 논문에선 data-driven pipeline for the creation of scalable KG 를 소개.
- 이 지식 그래프는 분류기 성능 향상을 위한 문화 지식과의 결합에 도움, 구체적으로
- 트위터나 레딧을 통한 fully data-driven knowledge graph construction
- 지식 그래프 결과에 대한 Manual evaluation
- 지식 그래프 기반으로 학습한 분류 모델의 경우 hate speech task 와 같은 작업(지식이 중요한)에 대해 classification performance improve
2. Related Work
Cultural knowledge playing an impoortant role in contextual situation. So we target cultural knowledge as a form of commonsense.
Cultural knowledge is largely correlated to stereotypes, this work focuses nationality and religious stereotypes.
-
In this work, create a unified resource of cultural knowledge and stereotypes. = KG (serve as sources of representing knowledge in a structured format.)
-
특히나 coomomsense reasoning 을 위한 KG 만드는 연구는 진행되어 왔으나 이 연구는 그 중에서도 constructed in automated manner 을 연구.
-
- Fusion based approaches (combining language model representations with representations extracted from knowledge base)
-
- Language model base (pre-trained lm 먼저, 이후 knowlege integration via intermediate pre-training)
3. Knowledge Graph Construction
Cultural KG on 5 religious (Atheism2, Christianity, Hinduism, Islam, Judaism) and 5 national (American, Chinese, French, German, Indian) entities
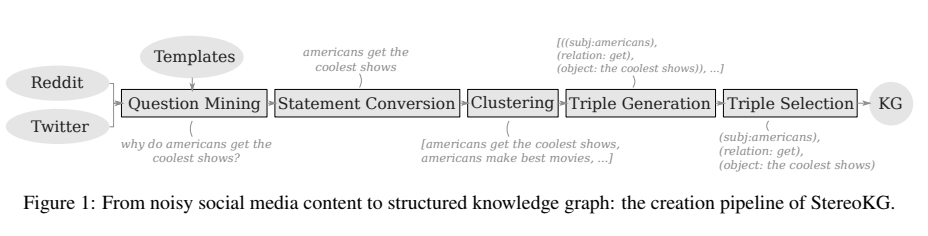
-
Question mining: Reddit 과 Twitter 에서 knowledge, stereotype 추출: 아래의 question, statement template 가 등장하면 (고정관념 가정하에) cues for underlying stereotypical notions 로 이용.

-
Converted into statements: OpenIE 가 interrogative sentence 를 처리하지 못하므로.
-
Clustering: SentenceTrasformers 를 활용, fast clustering > 유사한 내용 문장끼리 clustering. (singletons 는 그 문화의 특정한 생각을 보여주지 못하고, non-singleton clusters 는 지식을 보여주기에 better representation)
-
Converted into triples: OpenIE 를 사용해 subject-relation-object 로 변환.
-
Triple Selection: triples within a cluster >> sentence subject-predicate-object terms. 문법성에 따라 순위, 높은 순위가 그 entire cluster 의 대표로 선택. (KG에서 completeness 가 중요한 요소이기 때문에 이를 고려)
4. Knowledge Graph Evaluation
만들어진 KG 에 관해 qualitative and quantitative evaluation 을 해보자.
4.1 KG Statistics
1.sentiments 와 2.overall distribution of predicates를 평가하고자 함.
1.Sentiment Analysis
ternary(positive, neutral, negative) sentiment analysis over the KG triples (sentences) 진행.
- pre-trained sentiment classification model 사용
- 특정 entity term 때문에 특정 subject 에 대해 부정적으로만 판단하는 문제 발생
- bias 문제를 해결하기 위해 mask the subject entities: "islam seems to be conservative" => "religion seems to be conservative" 수행 후 분류 진행.
2.Pointwise Mutual Information (PMI)
PMI 라고 하는 는 measures the association of two events.
-
e와 w 의 연관도를 측정하고 싶은 것이고
-
e, w가 함께 나타날 확률을
-
e가 나타날 확률에 w가 나타날 확률을 곱한 것으로 나눈다
-
w는 함께 등장하는 predicate and object token 이다.
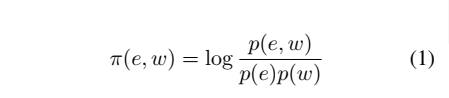
-
따라서 Infrequent token 의 경우 1. single entity 라면(분모가 작으므로) 상대적으로 high score, 2. said entity 라면 상대적으로 lower score 일 것이다.
-
하나의 entity 에는 자주 등장하는 token 이면서 다른 entities 에는 자주 등장하지 않는 것에 집중하기 위해, PMI-based association metric 도입:
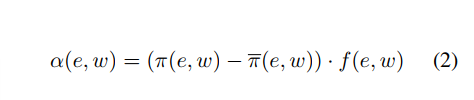
-
직관적으로 위의 식은 mitigates the effects of infrequent tokens in the PMI calculation and gives a relative score across all the entities.
-
결과적으로 는 triples contents 에서 entities 와 함께 등장하는 predicates, object 의 트렌드를 알기 위함.
-
따라서 single entity 는 분자, 다른 entity 를 모두 포함한 것을 분모로 보내어 계산한 식에(e를 다르게)
-
는 e와 등장하는 모든 토큰 중 w의 빈도를 곱한 것이다.(e고정)
-
정리하면, 앞 부분의 식으로 "다른 entities 에는 자주 등장하진 않는지를 체크할 수 있"고, 뒤의 식으로 "하나의 entity 에 자주 등장하는 token 인지를 확인"할 수 있다.
Results
감정 분류 결과를 보자.
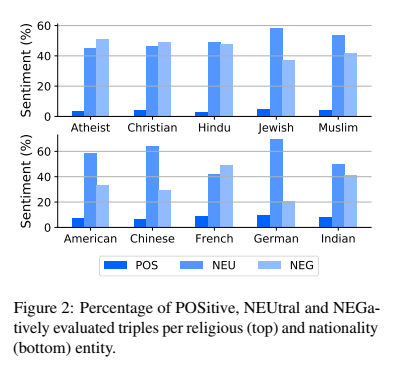
- 모든 entity 에서 positive 는 모두 적고, neutral, negative는 모두 많았음.
- religious 에선 Jews 가 가장 많이 긍정, 가장 적게 부정을 포함했으며, Hindus 는 가장 적은 긍정, Athesists 는 가장 많은 부정을 기록했다. ('attck', 'angry'와 같은 단어의 알파 점수도 높았다.)
- Nationalities 에 따르면 Germans 가 가장 많이 긍정, 덜 부정을 포함했으며, 중국은 가장 적은 긍정, 프랑스는 가장 많은 부정을 포함했다.
- 대부분의 온라인 stereotypical question 부정으로 판단된 것을 보면, stereotypes 자체가 prejudical opinions of diffrent cultural groups 이라는 우리의 가정을 재확인 할 수 있었다.
4.2 Human Evaluation
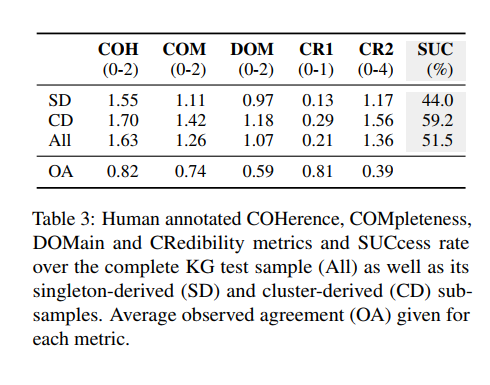
human evaluation 은 StereoKG 의 quality 를 평가하기 위해 수행. metric 은
-
coherence(COH; semantic logicality), completeness(COM; grammatical valency), domain(DOM; whether the triple belongs domain of interest) 3가지.
-
credibility CR1(binary, wheter the annotator has heard this stereotype before), CR2(whether they believe the information true)
-
overall quality: success rate(SUC; 위 3개 average > 1)
-
OA 는 observe Agreement. (평가자들 사이 일치 정도)
-
COH 는 전반적으로 높았고, COM의 경우 살짝 낮았음. (meaningful but missing information), DOM 은 1에 더 가까워 stereotype 인지에 대한 여부가 not clear했음.
-
SUC 의 경우 non-singleton 이 singleton 보다 높은 퀄리티. (occurerences of question online are better than unique question)
5. Knowledge Integration
KG가 어떻게 language model 에 지식으로 결합될까?
intermediate masked language modeling on 1. structured (verbalized triple; concise and less noisy) 2. unstructured form (sentence; expressive and verbose) 을 각각 진행 >> fine-tune >> hate speech detection evaluation
5.1 Experimental Setup
Data
목표: effect of intermediate pre-training (1, 2)
two kinds of down-stream datasets for fine-tuning(Twiiter; OLID/ outside the domain data; WSF)
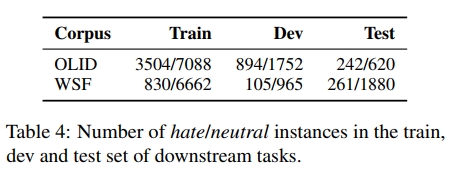
- unstrctured knowledge (UK;comprises the original sentence from the clusters)
- structured knowledge (SK; verbalizing the triples from the KG)
Models
- simpletransformers 라이브러리의 sequence classification pipeline 이용
- baseline : 1. BASE: RoBERT 2. DT(Domain Trained): Twitter RoBERTa
- fine-tuning: 1. UK 2. SK(impact stereotypical knowledge)
- report their averaged Macro-F1 with standard errors.
5.2 Knowledge vs. Domain
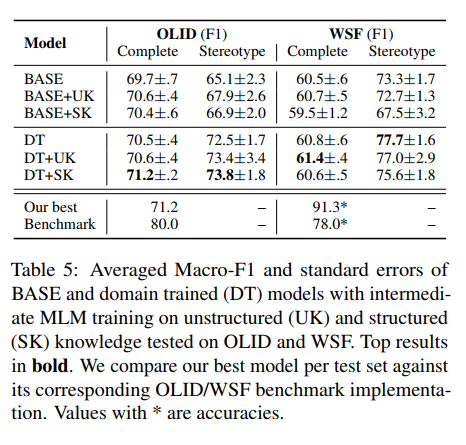
- stereotpyes 주입의 효과를 양적화하기 위해 dedicated stereotype test set 도 포함.
comlete test set
- 지식 결합이 영향을 끼치지 않은 것처럼 보임. 오직 DT에서만 성능의 향상이 발견됨. WSF 에서는 DT 모델이 BASE 보다 뛰어남; 71.2
- DT는 WSF에서는 (SK지식 그래프 결합이) 성능의 향상을 보이지 않음.; 61.4
stereotpyes test set
- OLID 데이터의 경우 DT에서 BASE 와 비교했을 때 확실한 향상을 보여줌. (73.8) => suggest that the training on cultural knowledge(UK, SK) can increase performance on knowledge-crucial sample(stereotype test set)
- WSF 데이터의 경우 이러한 경항이 없었음 => suggest that domain training is prerequiste for effective knowledge integration(결합; UK, SK를 하려면 그에 맞는 domain training이 필요; OLID vs. WSF)
5.3 Cultural Knowledge Prediction
모델 내에서 stereotypes 이 encode 되었는지 정량화하기 위해 example instances with masked token 과 모델의 top3 prediction 비교
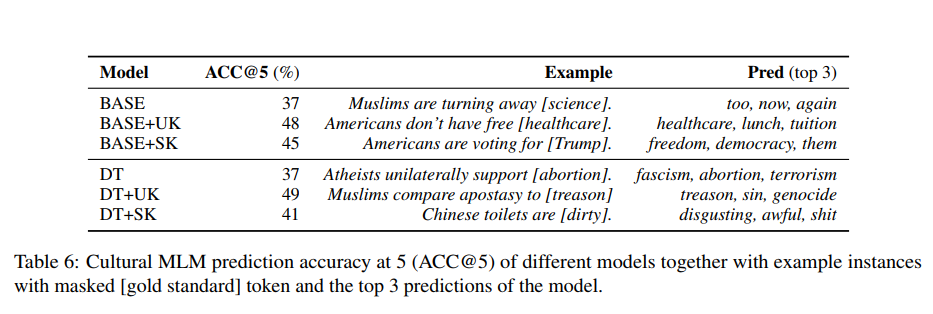
- BASE, DT model have the same low level of cutural awareness. (37%)
- adding unstructured knowledge instances as intermediate MLM training data drastically improves results to 48% (BASE+UK)
and 49% (DT+UK) - The structured knowledge also improves cultural sensitivity to a large margin, i.e., +7% points (BASE+SK) and +4% points (DT+SK)
6. Discussion
지금까지 automated pipline to extract cultural and stereotypical knowledge from the internet in the from of queries 를 만들었다.
지식을 실제로 결합하는 실험에선 performing intermediate MLM training on cultural knowledge 가 실제로 퍼포먼스 향상에 도움이 됨을 확인(knowledge-crucial smaple에 한해, 즉 그 도메인에서 훈련했으면 그 도메인에 적용해야 함.)
7. Conclusion
-
This study presents StereoKG, a scalable data-driven knowledge graph of 4,722 cultural knowledge and stereotype entries spanning 5 religions and 5 nationalities
-
performing intermediate MLM training on verbalized instances of StereoKG greatly improves the models’ capabilities to predict culture-related content (a slight improvement in classification performance)
