
Bias 에 대한 기본 개념 논문을 정리한 글이다. 원본 논문 보기
Abstract
NLP 모델이 다양한 적용 분야에서 성공적이었지만 기존 text corpora 의 gender bias 를 propagate, evem amplify 하는 문제가 존재한다. 이 논문은 현재의 recognizing and mitigating gender bias in NLP 에 관한 연구들을 살핀다.
- representation bias 의 4가지 형태에서 gender bias 를 논하고
- gender bias 를 인식하는 방법을 분석한다.
- advantages and drawbacks of existing gender dibiasing methods
1.Introduction
Bias 를 포함하는 NLP system 은 produce gender biased predictions, sometimes even amplify 한다. (NLP 알고리즘에서 전파되어 downstream applications 까지.)
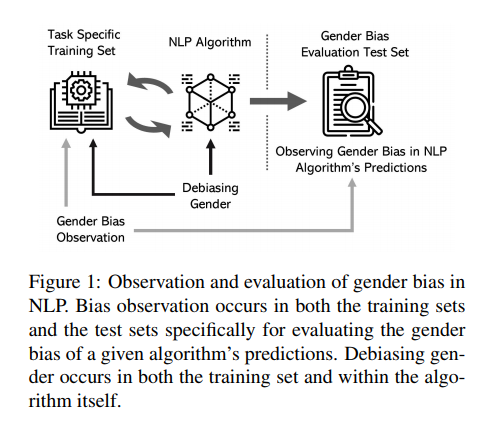
bias 를 카테고리로 나누는 한 방법은 allocation 과 representation bias 로 나누는 것이다.
allocation: 경제적 이슈, system 특정 그룹을 다른 그룹에 비해 unfairly allocates. (ex. perfrom better on data with majority gender)
representation: system detract from the social identity and representation of certain groups. (ex. gender and certain concepts are captured in word embedding)

- Denigration: use of derogatory terms
- Stereotyping: reinforces existing societal stereotypes
- Recognition: a given algorithm's inaccuracy in recognition task
- Under-representaion: the disproportionately low representation specific group
this papers summarize
1) recent studies of algorithmic bias in NLP under a unified framework
2) current dibasing methods with the purpose of identifying optimizations, knowledge gaps, directions
2. Observing Gender Bias
Gender Bias 의 평가 방법과 각각 방법의 types of representation bias 를 알아보자.
2.1 Adopting Psychological Tests
심리학에서는 Implicit Association Test (IAT) 가 subconcious gender bias 를 측정하는데 사용된다. 예를 들어 genders with arts and science 의 subconcious association 을 측정하기 위해
- 참가자들은 카테고리화 한다 (males or he science) 또는 (females or the arts)
- 그리고 나서 다시 카테고리화한다 (males or the arts) or (females or the science)
- 만약 전자에서 빠르고 정확하게 반응했다면, 인간은 무의식적으로 male은 과학과, female 은 art 와 연관지음을 보여준다
후에 Word Embedding Association Test (WEAT) 를 통해 GloVE나 Word2Vec embedding 에도 human biases 가 개입됨을 확인했다. Sentence Encoder Association Test (SEAT)에서는 문장 인코더에서 발견되는 bias 를 발견할 수 있었다.
2.2 Analyzing Gender Sub-space in Embeddings
Bolukbasi et al. (2016) 은 gender bias 를 gender subspace 에 gender-nuetral word embedding 을 사영시킨 것과 연결지었고, 그것이 단어의 word's bias rating 이라고 보았다.
- gender subspace 를 만들기 위해 gender-specific, gender-neutral 를 분류하는 linear SVM을 만든다
- 그리고나서 gender pairs 10개를 정한다음 gender direction 으로 본다.(she-he, her-his etc)
- PCA를 통해 다른 것보다 높은 variance 를 보는 주성분을 찾는다
후속 연구에선 cluster bias 라고 하는 단어 w 가 w의 임베딩을 가지고 KNN 적용하면 percentage of male or female 로 측정될 수 있다는 개념을 토입했다.
2.3 Measuring Performance Differences Across Genders
NLP tasks 에선 예측이 gender of the entity mentions or context 에 의해 크게 달라지지 말아야 하는데, 이를 확인하기 위해 성별만 다른 두 문장을 준비한다.
- “He went to the park” vs “She went to the park”.(gender-swapping)
- 성능 상의 차이를 측정하는 metric: False Positive Equality Difference (FPED) and False Negative Equality Difference (FNED); (원 문장과 gender-wapped 문장에서의 예측의 FP와 FN의 차이를 볼 수 있다.)
- image captioning worse recognizing a woman than a man (recognizing bias)
- prediction accuray 가 자치가 난다면, model 의 stereotyping 을 보여주는 것이고
- 모델의 편향이 debiased 되지 않고 전파된다면 under-representation of minority 라 할 수 있다.
3. Debiasing Methods Using Data Manipulation
본격적으로 진행된 Debasing methods 는 크게 두 가지로
1) text corpora and their representation
2) prediction algorithms
아래의 다양한 방법에서 크게 Method Type을 Retraining (debiasing 후 다시 훈련), Inference (다시 훈련하지 않고 예측 또는 representation modify)로 나눌 수 있다.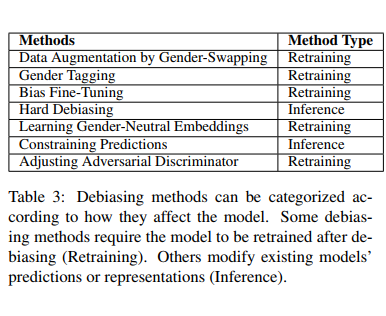
3.1 Debiasing Training Corpora
첫 번째 방법은 corpora 나 representation 에서 debiasing 하는 것이었고, 그 중에서도 corpora를 통한 방법을 알아보자.
3.1.1 Data Augmentation
데이터가 한 성별에 치중된 경우 두 성별을 같은 정보로 맞추기 위해 사용하는 방법이 소개되었다. (original + 부족한만큼 data-swapped sets) => Data Augmentation 에 속한다.
- original data set의 모든 문장에 대해 gender-swapped 문장을 만든다.
- name-anonymization(이름을 'E1'으로 변경)을 original sentence 와 gender-swapped quivalent 에 적용한다
- 따라서 original data with name-anonymizaiton 하나와, augmented data set (이름과 성별 변경) 하나가 만들어지고 모델은 이 두가지를 모두 학습한다.
이러한 augmentation 방법은 적용하기에 쉽지만 creating the annotated list 를 만든다는 점에서 비싸고, 일단 training set 사이즈 자체를 2배 늘리는 것이므로 시간이 늘어난다. 또한 'She gave birth' 로부터 'He gave birth' 이라는 nonsensical 한 문장을 만들어낸다는 단점이 존재.
3.1.2 Gender Tagging
현재의 Machine Translation 은 gender ambiguous 한 상황에서 training set 에 남성화자가 만다는 이유만으로 predict the speaker to be male 하는 문제가 있다.
Gender tagging 이란 모든 data point 의 시작에 화자의 gender 정보를 넣음으로써 이러한 문제를 해결한다. (ex. "MALE I'm happy") 이렇게 앞에 태깅만 해줘도 발화자의 성별이 문장에 영향을 미치는 국가들이 있어 MT의 성능 자체를 높일 수 있다.
이러한 Gender tagging 은 data point 의 모든 meta-information 을 알아야 Gender 표시까지 가능한 것이기에 비싸고, 메모리와 시간이 많이 소비된다.
3.1.3 Bias Fine-Tuning
Bias Fine-Tuning 이란 unbiased data set 로부터 학습된 모델에서 pretraining 한 후 biased data set 에 대해 fine-tuning 하는 것을 말한다. 수행하고자 하는 tasks 에서 적절한 훈련을 하면서도 training set 으로부터 learning bias 를 최소화할 수 있다.
그러나 이러한 Fine-Tuning 의 경우 전이학습에 있어 두 데이터 세트가 비슷한 주제 혹은 tasks 이어야 한다는 전제가 있었다.
3.2 Debiasing Gender in Word Embeddings
이번엔 societal biases 를 담을 가능성이 있는 Word Embeddings 를 조작하여 Debiasing 하는 방법을 알아보자.
(그런데 논문에서도 소개하듯 만들어낸 임베딩 자체를 건드리는 것이 NLP에서 철학적으로 맞는 접근인지에 대한 반대도 있었다.)
3.2.1 Removing Gender Subspace in Word Embeddings
- does not require retraining embeddings.
consine similarity and orthogonal vectors 사용하여 genderless framework 를 만들고 / 임베딩의 gender subspace 에서 유사도 제거.
이전에는 he 와 she 가 1826번째로 가까웠던 단어라면 코사인 유사도로 6번째로 가까운 단어로 만들고 / gender component 제거. (Genderless framework)
3.2.2 Learning Gender-Neutral Word Embeddings
GN-GloVE: isolating gender information in specific dimensions and maintaining gender-neutral information in the other dimension.
- gender dimension 내에서 negative difference 최소화
- gender direction 과 the other neutral dimension 사이 differences 최대화
앞의 두 방법모두 non-Euclidean space, Poincare embeddings 에서는 잘 동작하지 않음. (cosine similarity 적용하지 않음)
4. Deiasing by Adjusting Algorithms
NLP system 에 있어서 prediction 을 조정하는 방법들이다. 두 가지 접근을 알아보자.
4.1 Constraining Predictions
모델은 training set 에 있는 bias 를 학습하여 amplifying 함이 입증되었다. 예를 들어 훈련 세트에서 "secretary" 의 80% coreferents 가 female 이라면 이를 학습한 모델은 테스트셋에서 "secretary" 를 90% 확률로 coreferent female 로 예측. (amplify bias)
Reducing Bias Amplication (RBA) based on a constrained conditional model 제안.
- restricted the ratio of males to females
- Lagrangian relaxation
4.2 Adversarial Learning: Adjusting the Discriminator
variation on the traditional GAN- by having the generator learn with respect to a protected attribute.
5. Conclusion and Futrue Directions
following limitations of current approaches
- 대부분의 debiasing 기술은 focus on a single, modular process of an end-to-end NLP system
- empirically verified in limited applications, no easy to generalize
- may introduce noise into a model
future directions
-
Mitigating Gender Bias in Languages Beyond English: 영어 이외 다른 언어에 대한 Gender Bias 도 고려
-
Non-Binary Gender Bias: Non-Binary 성에 대한 차별도 고려
-
Interdiciplinary Collaboration: NLP 뿐 아니라 CS 의 다른 분야에서도 debiasing 을 위한 기술들이 있으며, NLP에 적용 가능할 수 있다.
