본 포스트는 딥러닝을 이용한 자연어 처리 입문 링크를 바탕으로 실습한 자료입니다.
TF-IDF 가 무엇인가?
TF-IDF 는 단어 빈도- 역 문서 빈도로, 단어에 대한 중요도를 계산할 수 있는 하나의 가중치이다. TF-IDF 를 이용해 보다 많은 문서의 정보들을 비교한다.
영어를 살펴보자.
Term Frequency - Inverse Documnet Frequency
단어 빈도 - 역 문서 빈도 라는 뜻이다. DTM 내의 단어들마다 중요한 정도를 가중치로 주는 방법이다. DTM을 우선 만든 후, TF-IDF 가중치를 부여하는 것!
이제 식으로 표현해보자.
문서를 d
단어를 t
문서의 총 개수를 n 이라 하자.
✅ tf(d,t) 특정 문서 d에서 특정 단어 t 의 등장 횟수
DTM의 각 단어들이 가진 값. (DTM: 각 문서에서 각 단어의 등장 빈도)
✅ df(t) 특정 단어 t가 등장한 문서의 수
t가 등장한 문서의 수에만 관심. 예컨대, '바나나'가 문서2, 3 에 등장한다면 '바나나'의 df 는 2이다. 문서 2, 3 에 바나나가 몇 번 등장했는지는 상관없이 오직 한번만 카운트 한다.
✅ idf(d,t) : df(t)에 반비례하는 수.
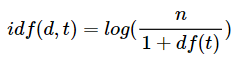
반비례인데 완벽히 역수는 아니고 분모에 df+1을 하고 로그를 씌운다.
log를 사용하는 까닭은 사용하지 않았을 때 문서 n이 너무 커진다면 df 는 상대적으로 당연히 작으므로 값이 너무 커진다.
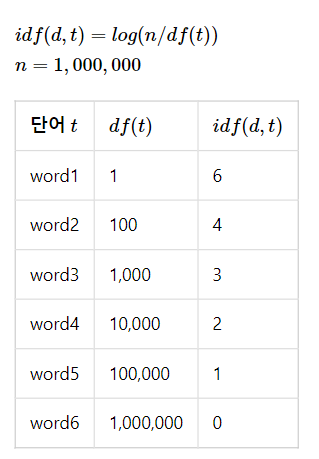
다음은 n = 1,000,000 이고 로그를 사용했을 때의 idf 값에 주목해보자.
다음은 n = 1,000,000이고 로그를 사용하지 않았을 때의 idf 값을 보자. 너무 크다.
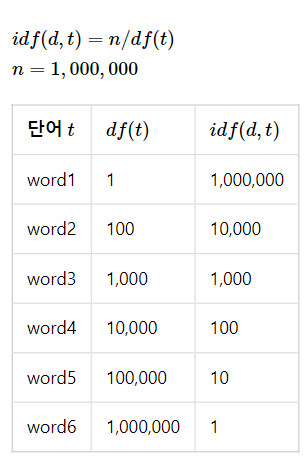
추가로 분모에 +1 을 해주는 이유는 분모가 0이 되는 상황 (특정 단어가 전체 문서에서 0번 등장)을 막아주기 위함이다.
✅ 값의 해석
TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 크다.
TF-IDF 는 모든 문서에서 자주 등장한다면 중요도가 낮고 / 해당 문서에서만 자주 등장하면 중요도가 높다고 판단한다.
✅ 실제 계산해보기
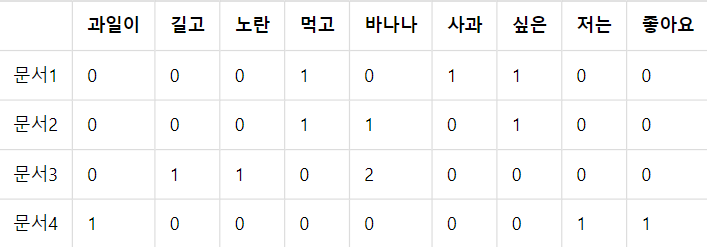
위 표를 보고 실제 구해보자.
TF는 DTM 을 사용하여, 문서에서 각 단어의 TF를 구하기만 하면 된다.
IDF 계산시 로그의 밑은 사용자가 임의로 지정, 프로그래밍에서 패키지들은 보통 자연로그를 사용한다.

최종적으로 TF-IDF 곱한 값 계산이다.
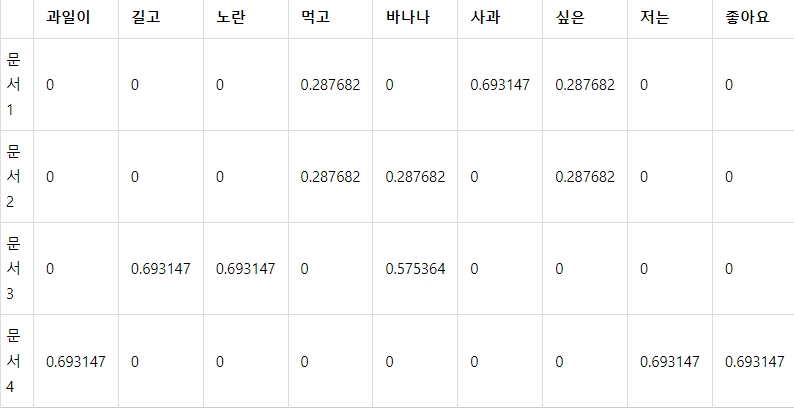
예컨대 문서2,3 에서 등장한 바나나는 문서 3에서 더 중요하다.
✅ 사이킷런 구현
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
# 코퍼스로부터 각 단어의 빈도수를 기록
print(vector.fit_transform(corpus).toarray())
# 각 단어와 맵핑된 인덱스 출력
print(vector.vocabulary_)
DTM 이 완성되었다!
반환된 리스트를 보면, 첫번째 열은 딕셔너리 0번을 부여받은 do 이다. do는 3번 문장에서만 등장하였으므로 0 0 1 의 열을 갖는다.
TfidVectorizer 은 TF-IDF 를 자동 계산해준다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
다음과 같이 TF-IDF 중요도 값을 확인할 수 있다. transform 메서드와 toarray 로 이를 반환한다!
