해당 포스트는 딥러닝을 이용한 자연어 처리 입문 링크 를 바탕으로 재정리한 글입니다
✅ LDA란 무엇일까?
우리는 자연어 처리를 위해 수많은 문서에서 주제를 알아내는 일에 관심이 있는데, 이를 토픽 모델링 이라 한다. LDA 는 잠재 디리클레 할당이라 불리는 기법으로, 토픽 모델링의 대표적인 알고리즘 중 하나이다. LDA를 알아보자!
문서1 : 저는 사과랑 바나나를 먹어요
문서2 : 우리는 귀여운 강아지가 좋아요
문서3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요
위와 같은 문서에서 토픽을 찾는데, 문서마다 토픽의 개수는 다를 수 있다. (우리는 토픽의 개수 k를 하이퍼파라미터, 우리가 지정하는 매개변수라 한다) LDA에서 토픽 2개를 찾은 결과는 다음과 같다.
LDA는 각 문서의 토픽 분포와 각 토픽 단어 분포를 추정한다.
<각 문서의 토픽 분포>
문서1 : 토픽 A 100%
문서2 : 토픽 B 100%
문서3 : 토픽 B 60%, 토픽 A 40%
<각 토픽의 단어 분포>
토픽A : 사과 20%, 바나나 40%, 먹어요 40%, 귀여운 0%, 강아지 0%, 깜찍하고 0%, 좋아요 0%
토픽B : 사과 0%, 바나나 0%, 먹어요 0%, 귀여운 33%, 강아지 33%, 깜찍하고 16%, 좋아요 16%
사용자는 결과로부터 토픽 A는 과일, 토픽 B는 강아지에 대한 ㅌ픽이라고 판단할 수 있다.
✅ LDA 수행하기
- 사용자는 알고리즘에게 토픽의 개수 k개를 알려준다
이를 하이퍼파라미터라 하며, 토픽의 개수를 알려주는 역할은 사용자의 역할이다.
- 모든 단어를 k개 중 하나의 토픽에 할당한다.
LDA는 차례로 모든 문서의 모든 단어에 대해 k개 중 하나의 토픽을 랜덤으로 할당한다. 작업이 끝나면 각 문서는 토픽을 가진다. 토픽은 단어 분포를 가진다. (위의 예시처럼) 랜덤 배정이므로 현재는 모두 틀린 상태이다.
- 모든 문서의 모든 단어에 대해 아래를 반복한다.
3-1) 어떤 문서의 각 단어 w 는 자신이 잘못된 토픽에 할당되어 있지만, 다른 단어들은 전부 올바르게 할당되어 있다고 가정한다. w는 두 가지 기준에 의해 재할당된다.
-p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
-p(word w | topic t) : 각 토픽들 t에서 해당 단어 w 의 분포
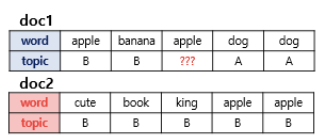
위 사진에서, apple 의 할당을 결정하자.
-첫번째에 따른다면 문서 doc1의 할당이 완료된 다른 단어들을 보자. 2개는 A, 2개는 B에 할당되어 있으므로 할당 확률은 50대50.
-두번째 방법에 따른다면 apple은 모두 B에 할당되어 있으므로 B에 할당될 가능성이 높다.
이를 반복하면 모든 할당이 완료된다.
