01 결정 트리와 앙상블
머신러닝에서의 앙상블?
하나의 모델을 쓰는 대신, 수많은 모델을 사용해 종합적인 판단을 하는 것
수많은 모델이 어떤 결과에 투표했는지에 따라 결정할 수도 있다.
수많은 모델을 만들고, 모델의 예측을 합쳐 종합적인 예측을 하는 것을 앙상블이라 한다.
02 랜덤 포레스트 1: Bagging
트리 모델들을 임의로 많이 만들어서 다수결 투표로 결과를 종합하는 알고리즘.
Bootstrapping : 갖고 있는 데이터셋으로 다른 데이터셋을 만들어내는 방법.
(같은 행이 여러 번 들어가서 만들어도 됨, 다음 사진이 예시다.)

- 모든 모델을 똑같은 데이터로 학습시키면 결과의 다양성이 떨어진다
- 임의로 만든 Bootstrap 데이터 셋으로 학습시킨다
- 이 데이터로 학습한 모델들의 결정을 합친다 : Bagging 이라 한다.
03 노트
04 랜덤 포레스트 2 : 임의로 결정트리 만들기
임의로 속성 두 개 선택한다고 해보자. 불순도가 낮은 것을 루트노드의 질문으로 한다. 다른 두 개의 속성의 불순도를 비교하여 낮은 것을 노드로 사용한다. 이것은 이전에도 학습했던 속성을 결정해 트리를 만드는 방법이다.
✅ 결정트리 임의로 만들기
1. bootstrapping 사용, 임의의 데이터셋을 만든다
2. 속성을 임의로 고르면서 만든다. 트리가 완성된다.
3. 1,2 의 과정을 반복한다.
3. 그리고 굉장히 많은 트리들을 임의로 만드는 것이 random forest 다. 트리들의 예측을 다수결로 모아 결과를 결정한다.
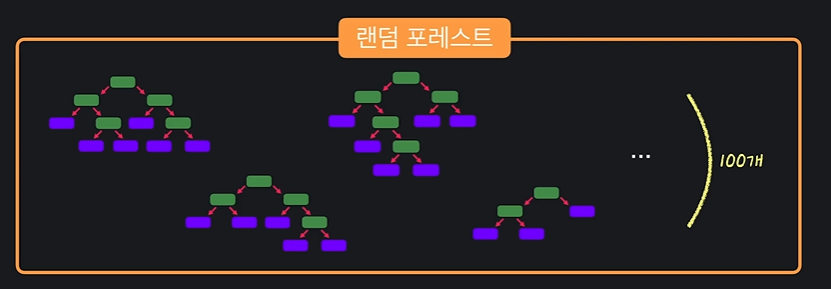
05 노트
06 scikit-learn 으로 랜덤포레스트 구현
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import numpy as numpy
import pandas as pd
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 5)
y_train = y_train.values.ravel()
model = RandomForestClassifier(n_estimators = 2000, max_depth = 4)
model.fit(X_train, y_train)
model.predict(X_test)
model.score(X_test, y_test)
importances = model.feature_importances_
indices_sorted = np.argsort(importances)
plt.figure()
plt.title('Feature importances')
plt.bar(range(len(importances)), importances[indices_sorted])
plt.xticks(range(len(importances)), X.columns[indices_sorted], rotation = 90)
plt.show()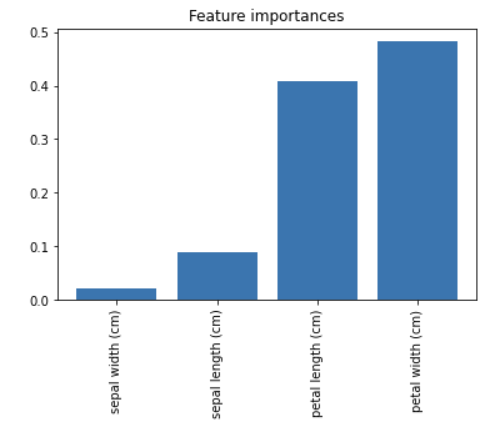
랜덤포레스트로 악성/양성 유방암 분류
rom sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
# 데이터 셋 불러 오기
cancer_data = load_breast_cancer()
# 저번 챕터 유방암 데이터 준비하기 과제에서 쓴 코드를 갖고 오세요
X = pd.DataFrame(cancer_data.data, columns = cancer_data.feature_names)
y = pd.DataFrame(cancer_data.target, columns = ['class'])
# 여기에 코드를 작성하세요
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 5)
y_train = y_train.values.ravel()
model = RandomForestClassifier(n_estimators = 10, max_depth = 4, random_state = 42)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
score = model.score(X_test, y_test)
# 테스트 코드
predictions, score
Mathematics, Algorithm, and IDEA for AI research🦖