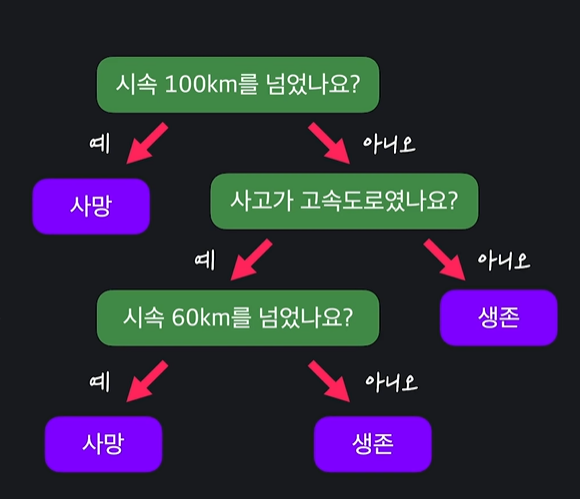
01 결정 트리란?
결정트리란 예 / 아니요로 답할 수 있는 질문들이 있으며, 이 질문들에 답해나가며 원하는 값을 분류하는 머신러닝의 알고리즘이다.
왜 트리인가?
- 하나의 뿌리로부터 시작
- 아래로 내려가며 예 / 아니요로 답할 때 두 갈래로 나뉨
- 각각의 질문 또는 결과를 노드라하는데, 가장 위를 root 노드, 가장 말단을 leaf 노드라 하며, 결정 트리에서 leaf 노드는 분류 값이다.
02 노트
03 if-else 문 구현
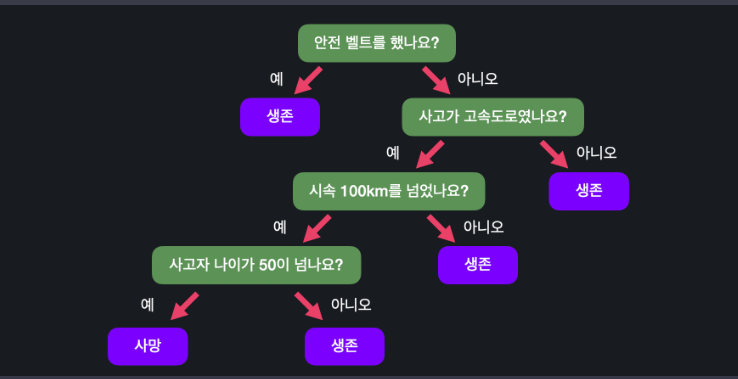
나는 다음과 같이 코드를 쳤다.
def survival_classifier(seat_belt, highway, speed, age):
# 여기에 코드를 작성하세요
if seat_belt: return 0
elif highway and speed >= 100 and age > 50: return 1
else: return 0 04 지니 불순도 (Gini impurity)
우리는 위의 예에서 그렇다면 질문은 어떻게 생성하는 것인지 궁금해할 수 있다. 머신러닝에서, 주어진 데이터가 있을 때 이들을 분류하는 질문을 잘 생성하는 것 또한 중요하기 때문이다. (질문을 잘 하는 것)
이에 관련한 주요한 지표가 지니 불순도이다. Gini impurity 라고 불리는 이 값은 무엇을 뜻할까?
지니 불순도 : 주어진 데이터 셋에서 서로 다른 분류들이 얼마나 섞여있는지 알려주는 값.
- 지니 불순도가 높으면 서로 다른 분류들이 많이 섞여있고
- 낮으면 순수한 데이터 1개의 값으로 이루어진 것에 가깝다
식은 다음과 같다.
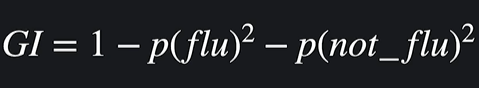
예컨대 주어진 데이터에서 독감이 100, 걸리지 않은 사람이 0 명이라면 GI 는 0이다. (순수한 상태). 독감이 50, 걸리지 않은 사람이 50 이라면 GI는 0.5로 높은 값(불순한 상태) 가 된다.
05 노트
06 지니 불순도 계산해보기
07 분류 노드 평가하기
루트노드는 무엇으로 하는 것이 좋을까?
아까 보았던 독감 트리에서, 독감과 독감이 아닌 것은 분류 노드라 하고, 그를 판별하는 질문들은 질문 노드라 해보자.
루트노드를 분류 노드라 했을 때, 지니 계수가 낮을수록 좋은 노드이다. 예컨대 독감 50, 독감 아닌이 40명인 데이터에서 첫 루트노드를 독감 분류 노드라 하면 결정 계수는 이다. 결정계수가 꽤 높은 상태이다.
따라서 좋은 분류노드란 불순도가 낮은 노드이다.
08 노트
09 질문 노드 평가하기
좋은 질문은 데이터를 잘 나누는 질문이다.
질문을 하면 데이터가 두개로 나뉘는데, 질문에 따라 분류된 데이터셋이 불순도가 낮다면 좋은 질문인 것이다.
다음 사진을 보자. 고열이 있나요란 질문에 예라고 답한 고열 환자는 50명이다. 독감과 일반 감기를 분류하는 게 목표인데, 이 중 40명이 독감, 일반 감기가 10명이라 불순도가 다음과 같다. 마찬가지로 계산한다음 가중평균을 구해준다. (지니불순도 * 명수) 의 평균.

질문을 평가하는 수치를 구하는 방법을 정리하면 다음과 같다.
질문 > 2개 데이터셋으로 분류 > 각각의 데이터셋의 불순도를 구함 > 가중하여 최종 불순도를 구함.
10 노트
11 노드 고르기
분류 노드의 불순도 : 이미 데이터가 잘 나뉘어졌는지 정도.
질문 노드의 불순도 : 질문을 통해 지금 데이터보다 불순도를 낮출 수 있는 정도.
질문 노드의 불순도에서 가장 불순도가 낮은 질문을 선택하면 된다. (통해 분류하면 불순도가 낮아진다!)
12 노트
13 질문 노드 평가해보기
14 모든 노드 만들기
다음 노드들도 같은 방법을 써주면 된다. 분류 노드를 쓸지, 질문 노드를 쓸지 모두 지니 계수를 써주면서 판단해주면 된다. 만약 질문 노드가 지니계수가 낮다면 그 의미는 한 번 더 질문을 하면 더 정확히 분류를 해줄 수 있다는 것.
-트리 깊이를 정해준다면 그 마지막 해당하는 리프 노드에는 분류 노드를 써줘서 결정한다.
15 노트
16 속성이 숫자형일 때 질문노드
속성이 숫자형일 때는 같은 온도 카테고리라 해도 그 값에 따라 할 수 있는 질문이 너무 많다. 이럴 땐 어떻게 해야할까?
먼저 체온 데이터를 정렬 시킨다음, 질문을 각각 만든다. 그리고 그 질문을 쓸 때의 지니 불순도를 각각 계산하여 어떤 온도로 나눠야 가장 잘 분류될지 결정하고, 질문 노드를 생성하면 된다. 역시나 가장 낮은 지니 불순도를 가지는 질문을 꼽으면 된다.
사실 숫자든 불린값이든 같다는 것!
17 속성 중요도
-어떤 속성이 중요하게 사용됐는지 알 수 있다.
고열, 기침, 몸살 중 어떤 것이 독감을 예측하는 데 중요하게 작용했을까? (이미 만들어진 트리에서 속성 중요도를 계산하자.)
속성의 중요도를 계산하기 위해선 한 노드의 중요도를 알아야 한다. 식은 다음과 같다.
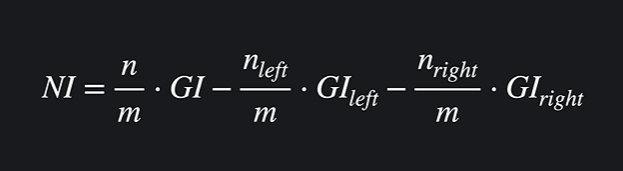
NI는 노드 중요도를 뜻한다.
n은 현재 살피는 노드까지 오는 데이터 수,
m은 전체 노드 수, GI는 지니계수이다.
이를 왼쪽, 오른쪽 노드에서 똑같이 계산하고 둘 다 빼준다.
위 노드에서 아래 노드로 내려오면서, 불순도가 얼마나 줄어들었는지를 계산을 하는 것이다. 이는 각 개인 노드의 중요도이다.
따라서 속성의 중요도를 알기 위해선 모든 노드 중요도의 합을 분모로, 해당 속성의 질문 노드 중요도의 합을 분자로 보낸다. 이를 속성의 평균 지니 감소라 한다.

18 노드
19 skikt-learn 데이터 준비
from sklearn.datasets import load_iris
import pandas as pd
iris_data = load_iris()
X = pd.DataFrame(iris_data.data, columns = iris_data.feature_names)
y = pd.DataFrame(iris_data.target, columns = ['class'])19 사이킷런 구현
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 5)
model = DecisionTreeClassifier(max_depth = 4)
model.fit(X_train, y_train)
model.predict(X_test)
model.score(X_test, y_test)
score가 0.9라는 것은 이 모델이 90퍼센트의 확률로 잘 분류한다는 뜻이다.
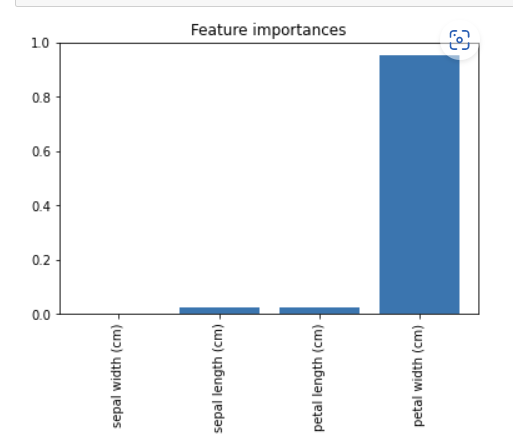
21 사이킷런으로 속성 중요도 확인하기
indices_sorted = np.argsort(importances)
plt.figure()
plt.title('Feature importances')
plt.bar(range(len(importances)), importances[indices_sorted])
plt.xticks(range(len(importances)), X.columns[indices_sorted], rotation = 90)
plt.show()