01 k겹 교차 검증
k-fold cross validation
학습 데이터는 학습, 평가 데이터는 평가를 위해서 사용한다.
모델의 성능 평가를 위해서는 k겹 교차 검증을 사용한다.
데이터 셋을 k개로 나눈다. (k = 5, m = 1000, 1000개를 5개로 나누니 각각은 200개 데이터가 된다.
그리고 n 번째 데이터(=200개)를 test set 으로 사용하며 각각의 데이터에 관하여 성능을 측정한다. (성능 5개 추출)
모든 성능을 모아 평균 내어 평균 성능을 낸다. 다른 test 데이터에 대한 성능을 각각 내기 때문에 더 믿을만한 성능이 된다.
이렇게 전체 데이터를 k개로 나누어 k번 검증, k개의 성능을 내는 것을 k겹 교차 검증이라 한다.
02 노트
03 구현
모델 평가의 k겹 교차 검증을 다음과 같이 구현한다.
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
import numpy as np
import pandas as pd
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)필요한 라이브러리는 다음과 같다. cross_val_score 이 교차 검증을 위한 것이고, warnings 는 불필요한 오류 메시지를 없애기 위한 것이다.
iris_data = datasets.load_iris()
X = pd.DataFrame(iris_data.data, columns = iris_data.feature_names)
y = pd.DataFrame(iris_data.target, columns = ['Class'])
logistic_model = LogisticRegression(max_iter = 2000)
np.average(cross_val_score(logistic_model, X, y.values.ravel(), cv = 5))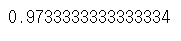
iris data 를 가져와서 실행했다. X는 iris 의 입력변수, y 는 꽃의 구분을 뜻하는 목표변수이다.
logisticmodel 을 만들어준다음,
교차 검증을 뜻하는 cross_val_score 에
(검증할 모델, 입력변수, 목표변수, 나눌 개수) 를 입력해준다. 각각 평균을 내면 이 모델의 전체 성능을 보여준다.
이때 ravel()은 pandas series 를 numpy array 로 만들어주는 함수이다.
04 k겹 교차 검증 코드로 구현
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
import numpy as np
import pandas as pd
GENDER_FILE_PATH = './datasets/gender.csv'
# 데이터 셋을 가지고 온다
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()
# 여기에 코드를 작성하세요
model = LogisticRegression(solver = 'saga', max_iter = 2000)
k_fold_score = np.average(cross_val_score(model, X , y , cv = 5))
# 테스트 코드
k_fold_score**solver = 'saga' 는 logisticRegression 모델을 학습시키는데 saga 방법을 사용해줘 라는 의미를 갖는다.
05 그리드 서치
하이퍼 파라미터
학습을 하기 전에 사람이 미리 정해 줘야 하는 변수 파라미터들.
model = Lasso(alpha = 0.01, max_iter = 1000)
alpha, max_iter 은 모델을 만드는 사람이 정하는 것이고, 이것들을 하이퍼 파라미터라 한다.
😴 좋은 하이퍼파라미터란?
Grid Search
하이퍼 파라미터의 후보 값들을 다 모델에 넣어보고, 성능을 다 계산해서 파라미터를 고른다.
max_iter에 1000, 2000, 3000 넣어보고, alpha 에 0.1, 1, 10 넣어보고 정한다.
후보값들은? : 구글링을 통해 디폴트값을 확인하고, 디폴트와 비슷한 후보값을 정한다.
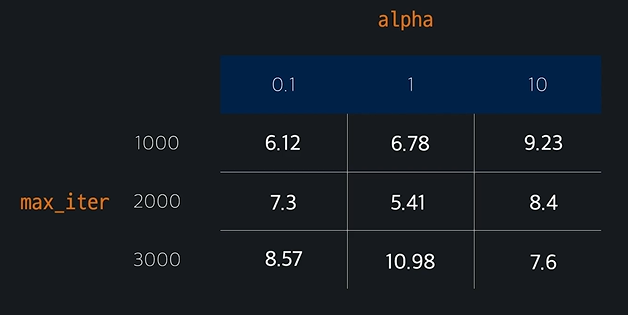
각 성능은 k겹 교차 검증을 통해 계산하고, 하이퍼 파라미터를 최종적으로 정한다. >> 이게 Grid Search 이다! (최적의 조합을 찾는 것)
06 노트
07 Scikit-learn 으로 Grid search 구현
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from math import sqrt
import numpy as np
import pandas as pd
admission_df = pd.read_csv('downloads/admission_data.csv').drop('Serial No.', axis = 1)
admission_df.head()
hyper_parameter = {
'alpha' : [0.01, 0.1, 1, 10],
'max_iter': [100, 500, 1500, 2000]
}
lasso_model = Lasso()
hyper_parameter_tuner = GridSearchCV(lasso_model, hyper_parameter, cv = 5)
yper_parameter_tuner.fit(X,y)
hyper_parameter_tuner.best_params_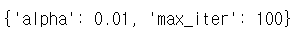
코드는 다음과 같다.
딕셔너리로 파라미터 후보값들을 입력한다 > 모델을 만들어준다 > GridSearchCV 에 훈련을 위한 것들을 넣어준다 > 훈련 > 최적의 파라미터 출력
GridSearchCV
(모델 이름, 파라미터 딕셔너리, 교차검증 수)
를 넣어주면 해당 변수로 이제 각각의 성능을 계산(.fit)하고, 최적의 조합을 출력할 수 있다.(.tuner.best_params_)
08 그리드 서치 직접 해보기
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
# 경고 메시지 출력 억제 코드
import warnings
warnings.simplefilter(action='ignore')
GENDER_FILE_PATH = './datasets/gender.csv'
# 데이터 셋을 가지고 온다
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()
# 여기에 코드를 작성하세요
model = LogisticRegression()
parameter_h = {
'penalty' : ['l1', 'l2'],
'max_iter': [500, 1000, 1500,2000]
}
GS = GridSearchCV(model, parameter_h,cv = 5)
GS.fit(X, y)
best_params = GS.best_params_
# 테스트 코드
best_params