✅ 요구사항 정리
// 문제 정의
- 문제에 대한 명확한 정의
- CCTV 유동인구 추이가 편의점 상품판매에 영향을 미칠 수 있는 가설
// 데이터 수집
- Open API 활용하여 데이터 수집
- 판다스 데이터 프레임으로 변환
- 오류 여부 확인
// 데이터 전처리
- 목표 달성에 필요한 수준
- 근거와 설명
// 데이터 시각화
- 디바이스별 유동인구 변화
- 월별 유동인구 변화
- 요일별 유동인구 변화
- 시간별 유동인구 변화
- 시각화 자료 2개 이상
// 가설 검증 및 해석
- 가설에 대한 해석 2회 이상
// 분석 의견
- 최종 분석의견
✅ 01 문제정의
// 문제 정의
- 문제에 대한 명확한 정의
- CCTV 유동인구 추이가 편의점 상품판매에 영향을 미칠 수 있는 가설
🍀문제정의
본 프로젝트는 서울시 북촌한옥마을 CCTV 자료를 바탕으로 유동인구 분석을 토대로 한다. 디바이스별 / 월별 / 요일별 / 시간별 유동인구 변화 추이를 분석하고, 해당 유동인구 변화 추이가 편의점 판매상품 구성, 수량에 어떠한 영향을 미칠 것인지 확인할 것이다. 최종적으로 편의점 판매량을 늘리기 위한 상품 전략을 제시하며 보고서를 마무리 할 것이다.
🍀유동인구 추이에 따른 편의점 상품판매에 영향 가설
월별 변화 추이
- 가장 유동인구가 많은 월은 10월 일 것이다.
요일별 변화 추이
- 유동인구가 많은 요일은 금요일일 것이다.
시간별 변화 추이
- 유동인구가 많은 시간은 오후 12시-4시일 것이다.
디바이스별 & 외 요소 1
- 가장 유동인구가 많았던 지역에 편의점 확장을 고려할 수 있다. (집중 투자, 더 다양한 종류 상품)
- 사람들이 많이 들어왔지만 빠지지 않았던 사람들이 많을수록 오래 머문다는 뜻으로 특정 상품을 기획할 수 있다.
- 사람들이 적게 들어왔지만 빠진 사람들이 많을수록 오래 머물지 않는다는 뜻으로 특정 상품을 기획할 수 있다.
✅ 02 데이터 수집
// 데이터 수집
- Open API 활용하여 데이터 수집
- 판다스 데이터 프레임으로 변환
- 오류 여부 확인
✅ 서울 열린 데이터광장 접속하고 일반 인증키 신청하기
서울 열린 데이터광장에 접속 후, 일반 인증키를 신청하려면 회원가입이 필요하다.
필자는 인증키를 등록해둔 상태이므로, 인증키 관리화면에서 이를 확인하겠다.
일반인증키(1) 로 잘 발급된 것을 확인할 수 있다. 이를 후에 API 요청 시 주소에 넣어주면 된다.
✅ Open API 활용하여 서버에 데이터 요청
원하는 데이터를 검색하여 'Open API' 버튼을 찾아준다.
이번 프로젝트의 경우 "서울시 북촌 CCTV 유동인구 수집 정보" 를 검색했다.
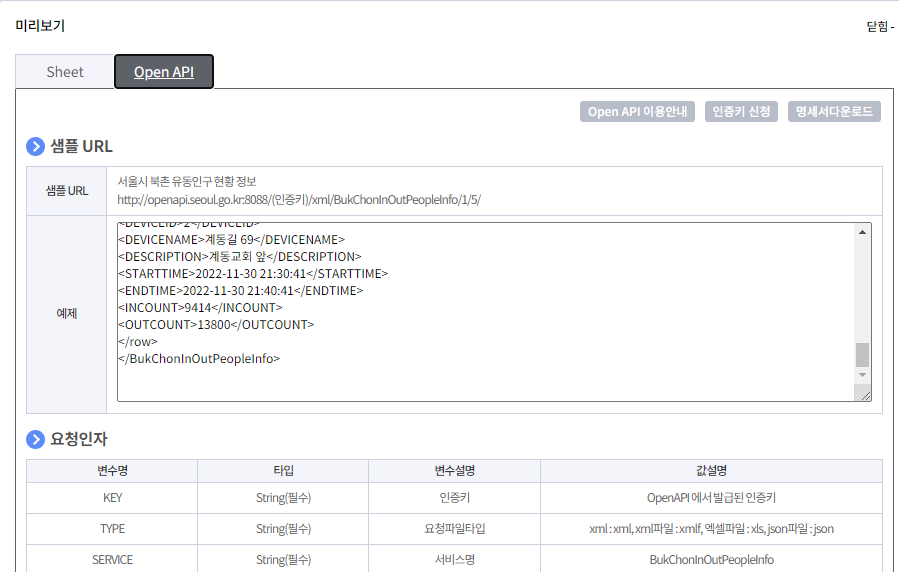
서울시 북촌 유동인구 현황 정보
http://openapi.seoul.go.kr:8088/(인증키)/xml/BukChonInOutPeopleInfo/1/5/
이를 확인할 수 있는데, 나의 경우
인증키에는 아까 발급된 나의 일반인증키 , xml 의 경우 json 으로 , 1/5/의 경우 페이지를 뜻하므로 1000씩 가져왔다.
✅ Pandas 데이터프레임으로 정리
나같은 경우는 1000개씩 요청을 주고 받는 과정에서 이를 어떻게 병합해야 할까 고민했다. 최종적으로 반복문으로 각각 데이터 프레임을 만들고, 만들어진 데이터프레임을 병합하는 방법을 사용했다. 그러기위해서 처음에는 빈 데이터프레임을 만들고 반복문 안에서 concat 을 사용하여 합쳐주었다.
✅ 최종 코드
데이터프레임으로 정리하는 코드는 다음과 같다.
pip install requests
import requests
import json
import pandas as pd
new_df = pd.DataFrame()
for i in range(1,29999,1000):
url = requests.get('http://openapi.seoul.go.kr:8088/654a41474d6b7975313230526e73534d/json/BukChonInOutPeopleInfo/{}/{}/'.format(i, i+999))
data = (url.text)
dict_data = json.loads(data)
df = pd.DataFrame(dict_data['BukChonInOutPeopleInfo']['row'])
new_df = pd.concat([new_df, df])new_df 를 출력해보면 다음과 같이 잘 정리된 것을 확인할 수 있다.
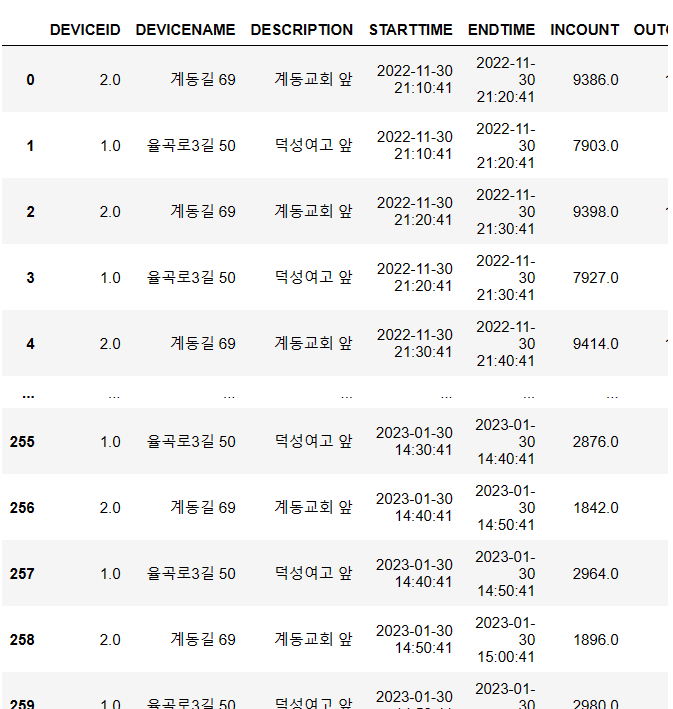
🍀오류 여부 확인
.isnull() 로 결측치를 확인해주었다.

모든 coloumn 에 결측치가 없는 것을 확인하였다!
✅ 03 데이터 전처리
// 데이터 전처리
- 목표 달성에 필요한 수준
- 근거와 설명
분석에 필요한 데이터에 대해 전처리를 위해 가설을 가져오고, 가설에 필요한 전처리들을 정리해볼 것이다. 전처리는 굵은 글씨로 표현 했다.
분석에 가장 많이 등장하는 '유동인구'는 outcount + incount 를 새로운 열에 할당하여 구성할 것이다
🔻 월별 변화 추이
- 가장 유동인구가 많은 월은 10월 일 것이다.
// 유동인구 // 월별 유동인구 // 시각자료(barplot)
🔻 요일별 변화 추이
- 유동인구가 많은 요일은 금요일일 것이다.
// 유동인구 // 요일별 유동인구 // 시각자료
🔻 시간별 변화 추이
- 유동인구가 많은 시간은 오후 12시-4시일 것이다.
// 유동인구 // 시간별 유동인구 // 시각자료
🔻 디바이스별 & 외 요소 1
-
가장 유동인구가 많았던 지역에 편의점 확장을 고려할 수 있다. (집중 투자, 더 다양한 종류 상품) // 유동인구 // 유동인구 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료
-
사람들이 많이 들어왔지만 빠지지 않았던 사람들이 많을수록 오래 머문다는 뜻으로 특정 상품을 기획할 수 있다.
// 유동인구 // 유입 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료 -
사람들이 적게 들어왔지만 빠진 사람들이 많을수록 오래 머물지 않는다는 뜻으로 특정 상품을 기획할 수 있다. // 유동인구 // 인구 유출 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료
-
10월엔 오래 머물 것이고 1월엔 오래 머물지 않을 것이다.
// 월별 유입 TOP, 월별 유출 TOP
✅ 04 데이터 시각화와 가설 검증, 해석
// 데이터 시각화
- 디바이스별 유동인구 변화
- 월별 유동인구 변화
- 요일별 유동인구 변화
- 시간별 유동인구 변화
- 시각화 자료 2개 이상
// 가설 검증 및 해석
- 가설에 대한 해석 2회 이상
🔻 월별 변화 추이
🍀가설1 : 가장 유동인구가 많은 월은 10월 일 것이다.
// 유동인구 // 월별 유동인구 // 시각자료(barplot)
ENDTIME 에 있는 촬영 시각을 기반으로 월을 추출했다. (dt.month 메서드) 새로운 월 자료는 MONTH 열에 할당하여 정리해주었다.
new_df['ENDTIME'] = pd.to_datetime(new_df['ENDTIME'])
new_df['MONTH'] = new_df['ENDTIME'].dt.month
new_df.head()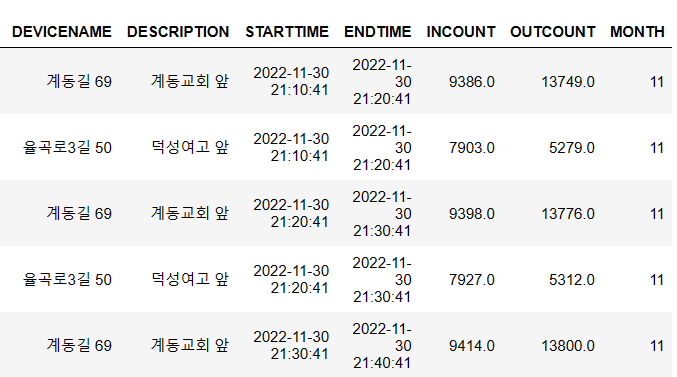
많이 활용되는 유동인구 는 해당 CCTV에 인구 유입과 인구 유출을 더한 값으로 정의하였으며, 이 값을 PASS 열에 새롭게 할당하였다.
new_df["PASS"] = new_df['INCOUNT'] + new_df['OUTCOUNT']
new_df.groupby("MONTH")["PASS"].mean()
평균은 다음과 같다.
Seaborn 라이브러리를 통해 barplot 함수를 사용하여 시각화해보겠다.
가로축은 월, 세로축은 유동인구이다.
import seaborn as sns
sns.barplot(data=new_df, x='MONTH', y='PASS')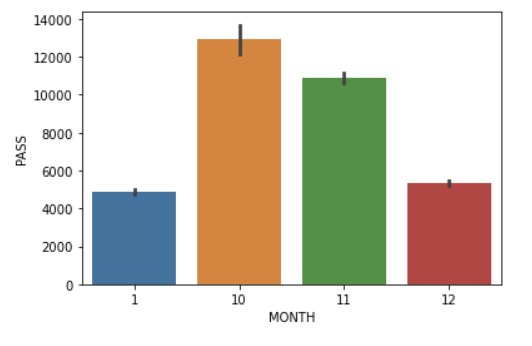
🙌가설1 검증: 가장 유동인구가 많은 월은 평균과 barplot 모든 수치에서 10월에서 가장 높았다. 가설 채택.
🔻 요일별 변화 추이
🍀가설2: 유동인구가 많은 요일은 금요일일 것이다.
// 유동인구 // 요일별 유동인구 // 시각자료
요일별 유동인구를 표로 확인하기 위해 새로운 데이터프레임을 만들 것이다.
기존 데이터프레임에 요일별로 0-6을 월-일요일로 할당한 Day 열을 만들어주었다.
그리고 new_df1 새로운 데이터프레임에 Day 열과 Pass 열을 가져왔다.
new_df['Day'] = [num_to_day[k] for k in new_df['ENDTIME'].dt.dayofweek] ## 요일 칼럼
new_df1 = new_df.groupby('Day')['PASS'].aggregate(['max','min','mean'])
new_df1 = new_df1.reset_index()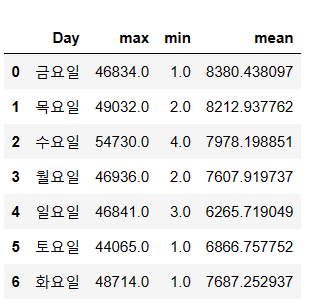
역시나 Seaborn 의 barplot 을 통해 시각화했다. (폰트 문제로 글자가 깨졌다, 값은 순서대로 월-일)
sns.barplot(data = new_df1, x= 'Day', y = 'mean')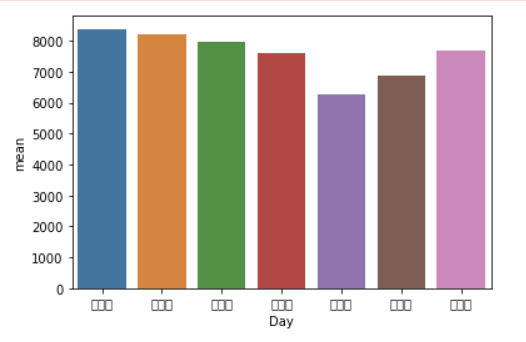
🙌가설2 검증: 유동인구는 월요일에서 가장 많았고 금요일에서 가장 낮았다. 가설 기각이나 새로운 인사이트를 얻었다.
🔻 시간별 변화 추이
🍀가설3: 유동인구가 많은 시간은 12시-4시일 것이다.
// 유동인구 // 시간별 유동인구 // 시각자료
dt.hour 를 통해 시간정보를 추출한 것을 filter 를 통해 각각 확인하였다.
filter = new_df["ENDTIME"].dt.hour < 4
filter2 = (new_df["ENDTIME"].dt.hour <= 8) & (new_df["ENDTIME"].dt.hour > 4)
filter3 = (new_df["ENDTIME"].dt.hour <= 12) & (new_df["ENDTIME"].dt.hour > 8)
filter4 = (new_df["ENDTIME"].dt.hour <= 16) & (new_df["ENDTIME"].dt.hour > 12)
filter5 = (new_df["ENDTIME"].dt.hour <= 20) & (new_df["ENDTIME"].dt.hour > 16)
filter6 = (new_df["ENDTIME"].dt.hour <= 24) & (new_df["ENDTIME"].dt.hour > 20)범위는 4시간 단위로 설정하였다.
print(new_df.loc[filter, "PASS"].mean())
print(new_df.loc[filter2, "PASS"].mean())
print(new_df.loc[filter3, "PASS"].mean())
print(new_df.loc[filter4, "PASS"].mean())
print(new_df.loc[filter5, "PASS"].mean())
print(new_df.loc[filter6, "PASS"].mean())각각의 평균값을 출력해주었다.

가장 높은 값을 기록한 건 평균 유동인구 17632 의 20-24 시간대였다.
당최 예상했던 12-4시는 4597로 하위권에 속했다.
🙌가설3 검증: 유동인구는 20-24시에서 가장 많았으며 12-4시는 4시간으로 자른 시간 단위 중 4위에 속하여 기각. 다른 인사이트를 얻었다.
🔻 디바이스별 & 외 요소 1
🍀가설4: 가장 유동인구가 많았던 지역에 편의점 확장을 고려할 수 있다. (집중 투자, 더 다양한 종류 상품)
// 유동인구 // 유동인구 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료
DEVICENAME 열을 기준으로 어떠한 위치에 CCTV 가 위치해있는지 확인해보았다.
new_df['DEVICENAME'].value_counts()
유동인구가 가장 많았던 지역을 확인하기 위해 PASS 기준 내림차순 정렬을 수행하고, 100개의 row 로 잘랐다. 이를 새로운 데이터프레임 df_sorted에 할당했다.
df_sorted = new_df.sort_values(by='PASS' ,ascending=False)
df_sorted = df_sorted.head(100)DEVICENAME 을 기준으로 PASS 를 확인해보았다.
조사를 하기 전엔 몰랐지만, 계동길 69만이 유동인구 TOP 100 안에 들었다. 따라서 본래 조사를 수정하여, TOP100 자료가 아닌 모든 데이터프레임을 기준으로 groupby 연산을 수행했다.
new_df.groupby('DEVICENAME').agg({'PASS':'mean'}).plot()
순서대로 계동길 69, 율곡로3길 50, 북촌로 5가길 38.
역시나 계동길의 유동인구가 가장 높았고 그다음에는 북촌로 5가길이 많은 차이를 기록하며 2순위에 올랐다.
더 직관적으로 확인하기 위해 boxplot 에 달 정보를 추가했다.
sns.boxplot(x = 'DEVICENAME', y = 'PASS', hue = 'MONTH', data = new_df)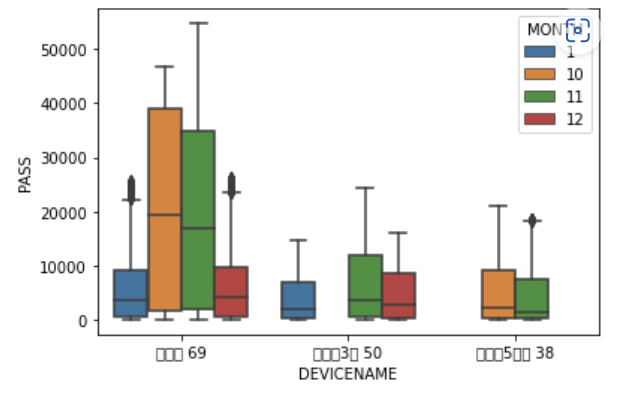
최종적으로 정리하면, 계동길69가 가장 많은 유동인구를 기록했고, 특히나 10, 11월은 압도적인 유동인구를 보였다
🙌가설4 검증: 계동길 69의 유동인구가 다른 두 지역보다 월등히 높았다.
🍀가설4: 사람들이 많이 들어왔지만 빠지지 않았던 사람들이 많을수록 오래 머문다는 뜻으로 특정 상품을 기획할 수 있다.
// 유동인구 // 유입 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료
🍀가설5: 사람들이 적게 들어왔지만 빠진 사람들이 많을수록 오래 머물지 않는다는 뜻으로 특정 상품을 기획할 수 있다. // 유동인구 // 인구 유출 기준 내림차순 정리 // 상위 디바이스 추출, 카운트 // 시각자료
유입하는 사람들의 수를 INPASS 새로운 열에 저장하고, 유출되는 사람들의 수를 OUTPASS 새로운 열에 저장하려고 한다. 유입하는 이들의 수는 INCOUNT - OUTCOUNT 로 정의하고, 유출하는 인구의 수는 OUTCOUNT-INCOUNT 로 정의했다. 따라서 코드는 다음과 같다.
new_df['INPASS'] = new_df['INCOUNT'] - new_df['OUTCOUNT']
new_df['OUTPASS'] = new_df['OUTCOUNT'] - new_df['INCOUNT']
새로운 열이 잘 들어간 것을 확인할 수 있다!
이를 새로운 데이터 프레임 in_df, out_df 각각 유입 기준 오름차순, 유출 기준 오름차순으로 정리했다.
따라서 in_df 의 상위에는 유입-유출이 큰 데이터들이, out_df 의 상위에는 유출-유입이 큰 데이터들이 위치한다.
in_df 의 디바이스에 대해 박스플롯을 그리면 다음과 같다.
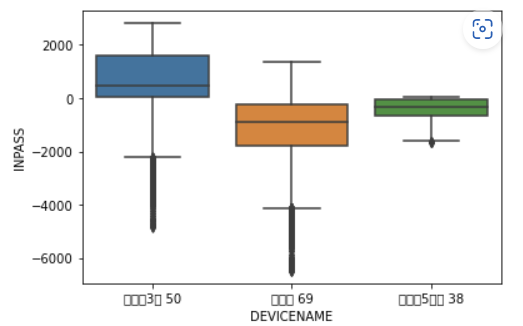
out_df 는 다음과 같다. (in_df 를 뒤집은 것이다.)
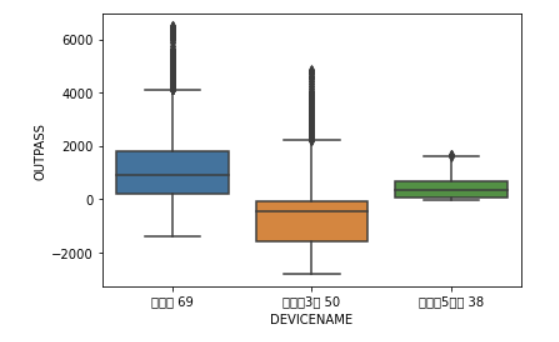
자료를 통해 알 수 있는 것은
- 계동길 69는 유동인구 자체의 숫자가 크지만 그만큼 유출 인구의 수가 많았다는 점 (오래 머물지 않는다는 뜻이기도 하다)
- 율곡로 3길은 유입되는 인구 대비 유출 인구가 가장 적어 단위시간동안 해당 지역에 사람이 가장 많을 것이라는 점 (오래 머문다는 뜻이기도 하다)
- 북촌로 5가 길은 매우 작은 분산을 보였다는 점
정도가 있다.
🙌가설4,5 검증: 사람들이 가장 많이 '모인' 지역은 율곡로 3길, 가장 많이 '지나다닌' 지역은 계동길 69였다.
✅ 05 // 분석 의견
- 최종 분석의견
보고서의 목적은 지난 자료를 바탕으로 편의점 상품판매 수량에 어떠한 영향을 미칠 것인지 확인하는 것이었다. 최종적으로 편의점 판매량을 늘리기 위한 상품 전략을 제시하며 보고서를 마무리 할 것이다.
판매 시기 예측
가설 1은 10,11,12,1 월 중 10월이 가장 유동인구가 많을 것이라 예측한 것이었고, 실제로 그러했다. 유동인구는 10월 다음으로 11월이 많았다.
따라서 일단 편의점의 전체적인 판매량 또한 겨울에 속하는 12,1월보다 가을에 속하는 10, 11월에 더 많았을 것임을 예측해볼 수 있다. 유동인구가 많을수록 해당 편의점을 지나치게 될 확률이 크다는 계산에서다.
가설 2는 유동인구가 금요일에, 3은 12-4시에 많을 것이라 예측했다. 실제로는 금요일에 가장 낮았고 월, 화, 수에 가장 높았다 또한 시간대별로 보았을 때 20-24시가 퍙균 17632의 유동인구를 기록하며 가장 많았다. 그 뒤를 이은 것은 15550명의 16-20시였다.
따라서 해당 3곳 주변 편의점 판매량 또한 월, 화, 수의 20-24시에 가장 많았을 것임을 추측해볼 수 있다.
편의점별 판매 제언
✅ 가장 유동인구가 많았던 계동길 69의 편의점 확장을 생각해볼 수 있다
계동길 69는 다른 2지역보다 유동인구만 따졌을 때 월등한 인구 이동을 보였다. 이는 특히 10,11월에 두드러졌는데, 다른 1,12월은 다른 지역의 인구 이동과 비슷했지만 특히나 가을철의 유동인구가 4배가량 차이났다.
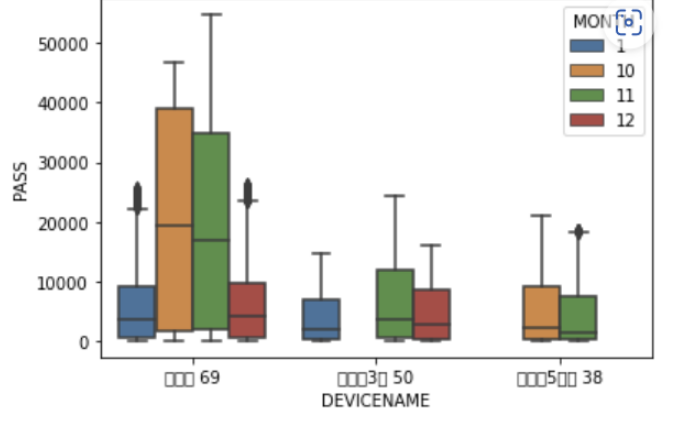
당연히 계동길69의 편의점 수익이 다른 지역보다 높음을 유추할 수 있으며, 이 지역의 편의점은 더 높은 투자를 바탕으로 확장을 고려해볼 수 있다.
✅ 단위시간당 인구가 오래 머무는 율곡로 3길의 상품 판매 전략
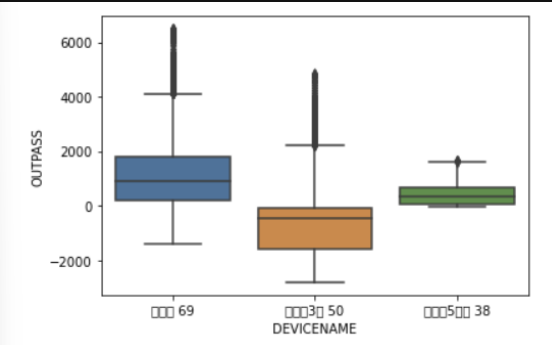
율곡로 3길은 유입되는 인구 대비 유출 인구가 가장 적어 단위시간동안 해당 지역에 사람이 가장 많을 것이라 예측했다. 다른 말로 율곡로 3길은 사람들이 오래 머문다는 뜻이기도 하다. 율곡로 3길을 확인해보았다.

역시나 길은 단순히 통로로서의 목적이 아니라 걷기 좋은 담장길이었다. 담장길에 간 사람들은 단순히 걷기 위함이 아니라 그 속에서 여유를 찾을 목적을 가졌을 것이고, 이것이 데이터에서도 드러났다고 할 수 있다.
따라서 율곡로 3길의 경우 소비시간이 긴 상품을 판매해도 좋다고 결론지었다. 소비시간이 긴 상품이란 편의점에서 소비할 수도 있는 먹거리 음식 등을 뜻한다.
즉석식품이나 겨울철 포장마차에서 먹던 것들을 편의점 안으로 들여온 것인데, 이를 통해 수익을 극대화 할 수 있다.

실제로 편의점 호빵 등은 기온이 떨어지는 12,1월 매출이 급등한다고 한다. 거리에서 소비 시간도 길고 12,1월 유동인구도 나쁘지 않은 율곡로3길은 겨울철 음식을 판매하는 것을 제안한다.
✅ 거리에서 오래 머물지 않는 계동길 69의 경우 소비 시간이 짧은 물품 위주 배치
반대로 계동길 69는 가장 많은 유동인구를 보이면서도 위의 그래프에서도 확인할 수 있듯 들어온 사람 대비 더 많은 사람이 나갔다. 사람들의 이동 속도가 빠른 거리라는 뜻이다.

(계동길 69의 모습. 거리를 걷기보다 창덕궁으로 가는 통로 혹은 상점의 방문 때문에 찾을 것이다.
이런 거리에선 편의점 본연의 역할인 '편리하고, 소비시간이 짧은' 물품 판매에 치중해야 한다. 계동길 69는 유동인구 자체가 높은 편으로, 특정 물품 또는 음식을 특화하여 판매하는 것보다 찾고자 하는 물건이 없는 일을 방지하는데 충실하는 편도 좋아보인다. 사람들이 많아질수록 구매 요구도 다양해지기 때문이다.
