개요와 데이터 모델 설명
캐글의 캐글 Home Credit Default Risk 에 들어가면 다음과 같은 페이지의 overview 와 Data 에서 개요와 주어진 데이터에 대한 정보를 알 수 있다. 확인해보자.
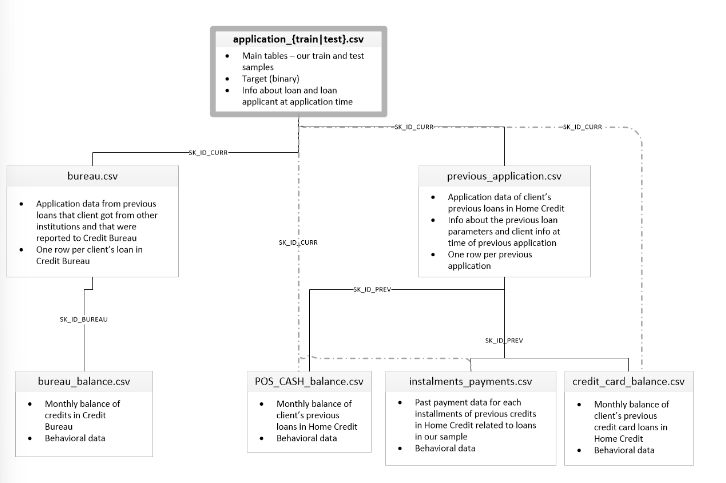
자세한 설명이 Dataset Description 에 적혀있었다.

appliction_{train|test}.csv
가장 최상단의 메인에 위치한 것은 application_{trian|test}.csv 이다. 영어를 해석해보면, 이는 메인 테이블이며 학습과 테스트를 위한 두개의 파일로 나뉘어 있다고 한다.
bureau.csv
모든 고객의 과거 타사 대출 이력이 이 파일에 포함되어 있다고 한다.
bureau_balance.csv
balance 는 잔액이란 뜻이다. 타사 대출이 있으므로 월별로 납부를 하는데, 이와 연결되어 있는 고객의 잔액 상황을 뜻한다.
previous_application.csv
모든 자사 대출 과거 대출 이력에 대한 정보이다.
POS_CASH_balance.csv, credit_card_balance.csv, installments_payments.csv
현금, 카드 과거 대출에 대한 잔액을 나타낸다. installments 는 과거 채무를 얼마나 이행했는지 보여주는 자료다. 하나의 행은 하나의 이행과 동일하다고 한다.
Application 데이터셋 속성 뜯어보기
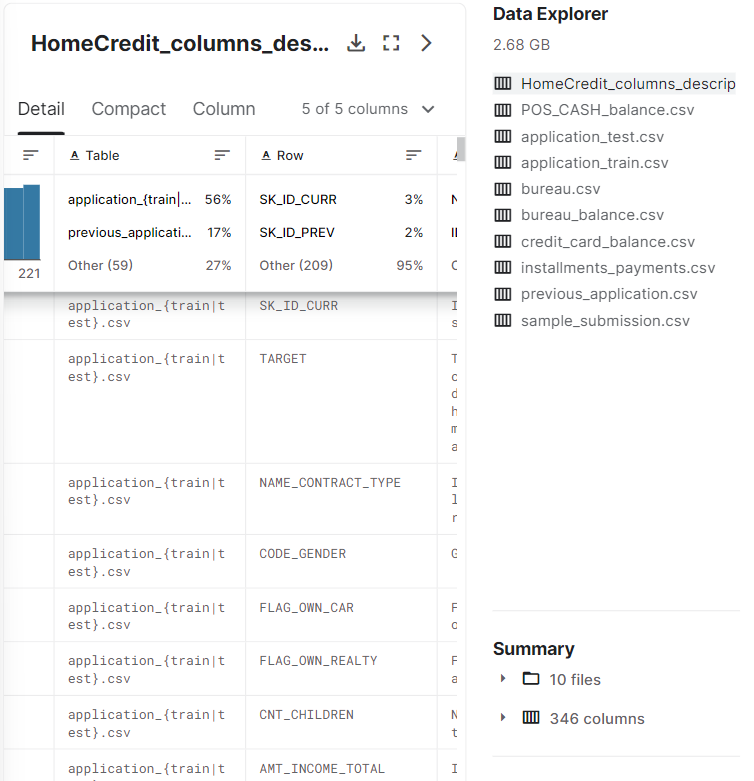
더 자세히 쓰여진 Description 을 확인할 수 있어 찾아보았다.
SK_ID_CURR : 고객 아이디에 대한 정보로 분석의 기본이 될 것이다. 고객 신상에 대한 정보는 이외에도 성별, 나이, 가족, 가족 구성원 등 매우 다양했다.
NAME_CONTRACT_TYPE : 고객이 뭘로 대출 받았는지에 대한 정보이다. 대출 정보에 대한 정보는 이외에도 대출을 얼마나 했는지, 월별 납부 금액은 어느정도인지 등 다양했다.
FLAG_OWN_CAR : 차를 가지고 있는지 여부이다. 고객 자산에 대한 정보는 이외에도 소득유형, 직업, 직업에서의 연차, 사는 곳, 지하엔 뭐가 있는지 등 과하다 싶은 것까지 다 있었다.
FLAG_DOCUMENT : 해당 서류를 제출했는지 여부이다. 이처럼 대출 시 고객 행동 정보는 대출하러 온 고객의 행동이 어떠했는지, 전화번호는 썼는지, 정보를 누락시킨 것은 없는지, 문의 사항은 있었는지, 전화 문의가 있었다면 대출 전 언제 있었는지 등 있었다.
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
default_dir = "/content/gdrive/My Drive"
app_train = pd.read_csv(os.path.join(default_dir, 'application_train.csv'))
app_test = pd.read_csv(os.path.join(default_dir, 'application_test.csv'))분포도 시각화
먼저 라이브러리 로딩 코드이다.
import numpy as np
import pandas as pd
import gc
import time
import matplotlib.pyplot as plt
import seaborn as sns
#import warning
%matplotlib inline
#warning.ignorewarning(...)
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 200)
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
#default_dir = "/content/gdrive/My Drive"
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
app_train.head()
app_train.shape, app_test.shape
소득 수치 시각화
app_train['AMT_INCOME_TOTAL'].hist()
plt.hist(app_train['AMT_INCOME_TOTAL'])
sns.distplot(app_train['AMT_INCOME_TOTAL'])
sns.boxplot(app_train['AMT_INCOME_TOTAL'])
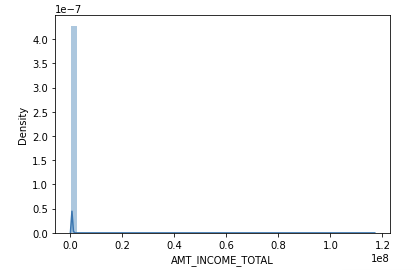
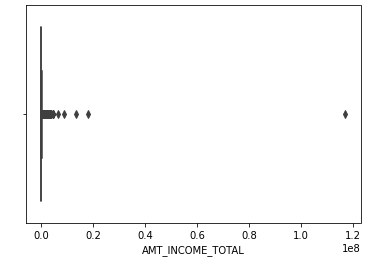
각각 판다스 내장 히스토그램, 맷플롯립, 씨본을 이용한 distplot 과 boxplot 이다. 아무래도 소득이 아래쪽에 집중되어 있고 도수가 많다보니 위쪽 소득이 존재했음에도 히스토그램으론 잡히지 않았다. 이 부분에선 씨본의 박스플롯이 점으로 확인할 수 있어 좋을 거 같다.
1000000 이하 수치 시각화
위쪽은 도수가 적어 쳐낸 다음 1000000 이하 자료만 시각화해봤다. 이는 불린인덱싱을 활용하면 어렵지 않게 할 수 있다. (데이터프레임[불린 조건][원하는 열])
cond_1 = app_train['AMT_INCOME_TOTAL'] < 1000000
app_train[cond_1]['AMT_INCOME_TOTAL'].hist()
sns.distplot(app_train[cond_1]['AMT_INCOME_TOTAL'])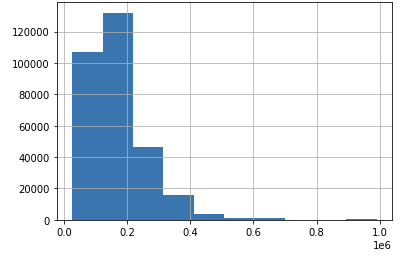
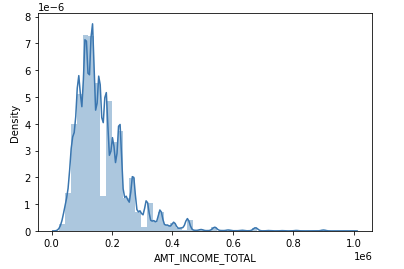
역시나 Seaborn 에서 좀 더 정교한 KDE 그래프를 확인할 수 있었다!
Target 값에 따른 수치 시각화
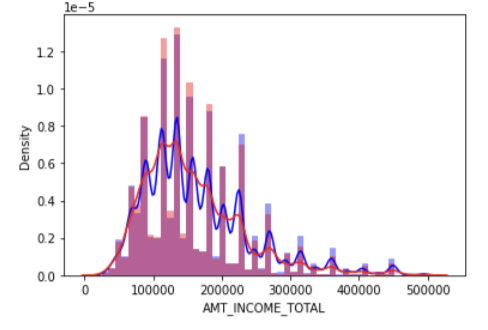
그렇다면 전체 소득분포가 아니라 target 값에 따른 소득은 어떨까?
cond1 = (app_train['TARGET'] ==1)
cond0 = (app_train['TARGET'] ==0)
cond_amt = (app_train['AMT_INCOME_TOTAL'] < 500000)
sns.distplot(app_train[cond0 & cond_amt]["AMT_INCOME_TOTAL"], label = '0', color = 'blue')
sns.distplot(app_train[cond1 & cond_amt]["AMT_INCOME_TOTAL"], label = '1', color = 'red')타깃이 1인 것, 0인것, 소득 500000 제한을 걸어 컨디션 3개를 만들어줬다. 여기서 타깃1 & 소득제한 과 타깃 0 & 소득 제한을 걸어 각각 그래프로 출력해줬다.
이번엔 바이올린플롯으로 보자.
sns.violinplot(x = 'TARGET', y = 'AMT_INCOME_TOTAL', data = app_train[cond_amt])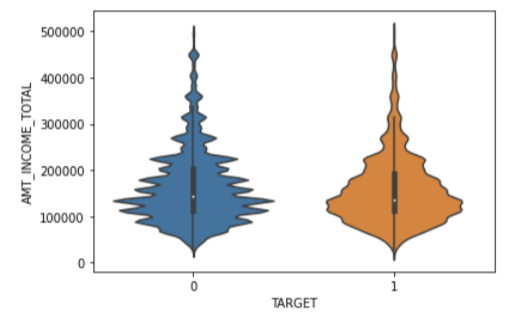
두 개를 같이 볼려면 서브플롯을 이용해줘야한다.
fig, axs = plt.subplots(figsize = (12, 4), nrows = 1, ncols = 2)
1행 2열의 플롯이 나타난다.
fig, axs = plt.subplots(figsize = (12, 4), nrows = 1, ncols = 2, squeeze = False)
cond1 = (app_train['TARGET'] ==1)
cond0 = (app_train['TARGET'] ==0)
sns.violinplot(x = 'TARGET', y = 'AMT_INCOME_TOTAL', data = app_train[cond_amt], ax = axs[0][0])
cond_amt = (app_train['AMT_INCOME_TOTAL'] < 500000)
sns.distplot(app_train[cond0 & cond_amt]["AMT_INCOME_TOTAL"], label = '0', color = 'blue', ax = axs[0][1])
sns.distplot(app_train[cond1 & cond_amt]["AMT_INCOME_TOTAL"], label = '1', color = 'red', ax = axs[0][1])각 그래프에 fig 는 전체를 의미하고, ax 는 [0][1] 을 할당해준다.
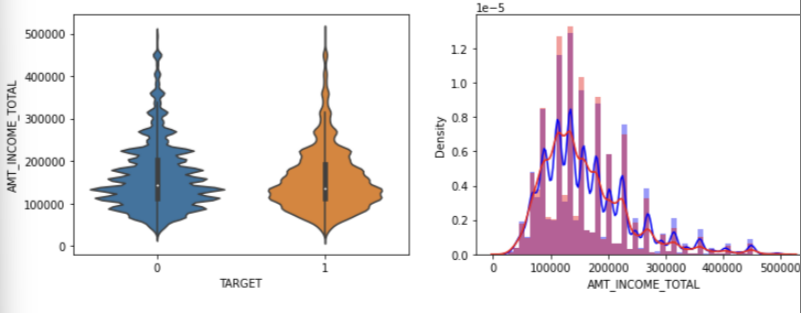
이를 함수와 시키면 다음과 같다.
def show_column_hist_by_target(df, column, is_amt = False):
cond1 = (df['TARGET'] ==1)
cond0 = (df['TARGET'] ==0)
fig, axs = plt.subplots(figsize = (12, 4), nrows = 1, ncols = 2, squeeze = False)
cond_amt = True
if is_amt:
cond_amt = df[column] < 500000
sns.violinplot(x = 'TARGET', y = column, data = df[cond_amt], ax = axs[0][0])
cond_amt = (app_train['AMT_INCOME_TOTAL'] < 500000)
sns.distplot(df[cond0 & cond_amt][column], label = '0', color = 'blue', ax = axs[0][1])
sns.distplot(df[cond1 & cond_amt][column], label = '1', color = 'red', ax = axs[0][1])
show_column_hist_by_target(app_train, 'AMT_INCOME_TOTAL', is_amt = True)