데이터 Preprocessing 수행
object feature 들을 Label Encoding 해주기 : factorize() 이용
객체형을 가진 피처들을 0과 1의 라벨을 달아주는 과정이다. 이때는 현재 학습용 데이터와 테스트용 데이터로 분리된 프레임을 결합해주는 코드가 필요하다.
결합 데이터프레임 = pd.concat([프레임1, 프레임2])
데이터 프레임을 결합한다.
app_train.shape, app_test.shape
apps = pd.concat([app_train, app_test])
apps.shape
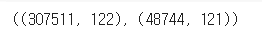{kind=link}
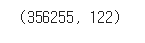
apps의 타깃만 카운트 해주면 다음과 같다. 0.0 과 1.0 은 학습 데이터에서 나온 것이고, NaN은 테스트 데이터에서 온 것이다.

합쳐주었으므로 이제 본격적으로 라벨링을 진행해주자. dtypes 를 이용해 객체인 것만 뽑아주어 불리언 인덱싱 후 리스트로 반환하여 변수에 넣어주자. 반복문을 돌며 라벨링을 수행해준다.
#불리언 인덱싱 후 리스트로 반환
object_columns = apps.dtypes[apps.dtypes == 'object'].index.tolist()
#반복문 돌면서 factorize 수행. 기존 column 이름과 같이 넣어줌.
for column in object_columns:
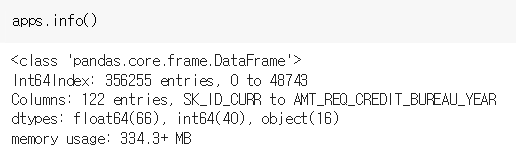
apps[column] = pd.factorize(apps[column])[0]이제 apps.info()로 확인해주면 더 이상 object 는 없고 숫자 dtypes 만 있는 것을 확인할 수 있다.
분리를 위해서 Null 값 일괄 반환
isnull().sum() 을 이용하면 피처별로 널 값의 개수를 셀 수 있다.
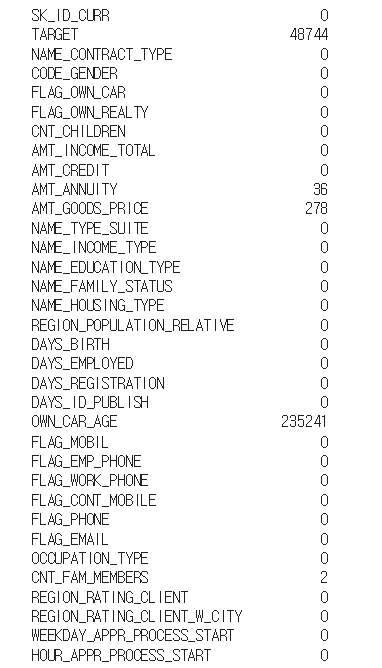
널 값이 이렇게 많은 것은 모두 테스트 데이터 때문이다. 따라서 빈 곳에 모두 -999를 넣어준다. (분리를 위해서다!)
# -999로 모든 컬럼들의 Null값 변환
apps = apps.fillna(-999)
apps.isnull().sum().head(100)
다시 분리
-999인 값을 찾아 불리언 인덱싱 하여 다시 분리해준다.
app_train = apps[apps['TARGET'] != -999]
app_test = apps[apps['TARGET'] == -999]
#테스트 데이터의 Target은 아예 삭제해야 함.(-999로 채워넣을 것이 아니라)
app_test = app_test.drop('TARGET', axis = 1, inplace = False)
app_test.shape
학습 수행, 학습 데이터에서 피처와 타깃 분리 , 학습용과 검증용 데이터 분리
학습용과 검증용 데이터는 잘 분리되어 있지만 학습용 안에서 x와 y사 분리되지 않았다.
x는 ftr_app에, y는 target_app에 넣어주자. 그리고 나서 x와 y를 다시 70, 30으로 학습과 검증을 위해 쪼개주자. 총 4개의 데이터가 만들어진다.
ftr_app = app_train.drop(['SK_ID_CURR', 'TARGET'], axis =1) #x값, 120개
target_app = app_train['TARGET'] #y값, 2개
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size = 0.3, random_state = 2020)
train_x.shape, valid_x.shape
train_x 와 valid_x는 각각 입력변수의 테스트용과 검증용이다.
이제 LGBM으로 학습을 수행해보자.
from lightgbm import LGBMClassifier
clf = LGBMClassifier(
n_jobs=-1, #다 쓰겠다
n_estimators=1000, #반복횟수
learning_rate=0.02,
num_leaves=32,
subsample=0.8,
max_depth=12,
silent=-1,
verbose=-1
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)],
eval_metric= 'auc', verbose= 100, early_stopping_rounds= 50) #50번 반복. 성능 좋아지지 않으면 멈춘다.
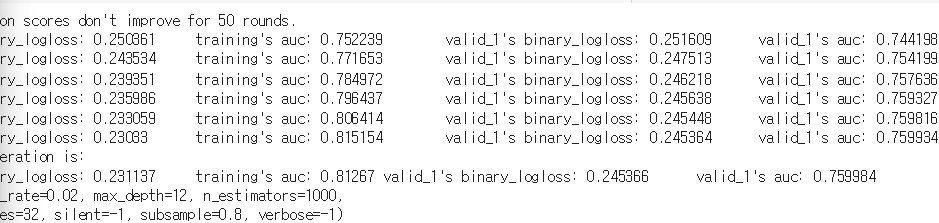
valid_auc 성능이 500번과 600번 사이에 크게 좋아지지 않아 학습을 완료했다!
feature importance 시각화
피처 중요도는 plot_importance 를 이용한다.
from lightgbm import plot_importance
plot_importance(clf, figsize=(16, 32))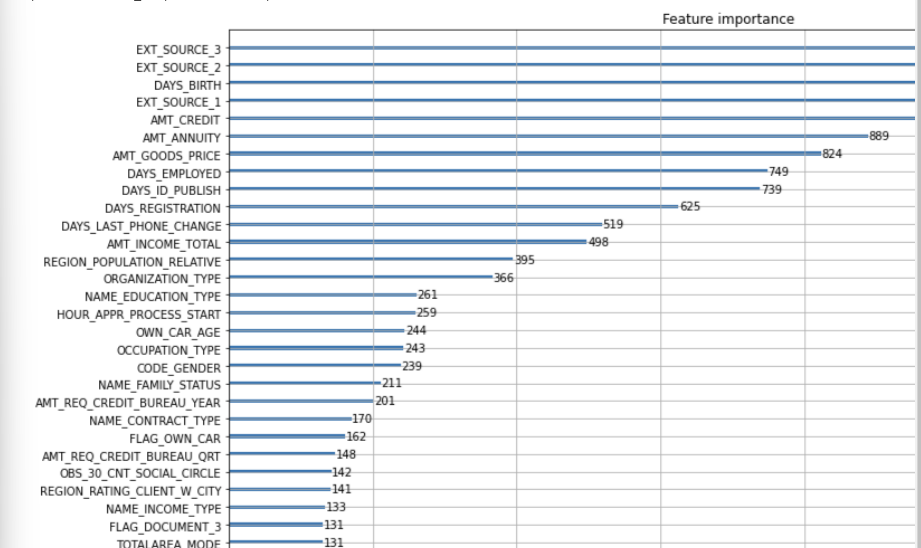
학습 모델 이용하여 에측, 캐글에 제출해보기
예측은 predit_proba를 사용한다.
#현재 테스트 데이터에 SK_ID_CURR이 들어가 있어 이를 제외한다.
clf.predict_proba(app_test.drop(['SK_ID_CURR'], axis = 1))
#모델 예측을 수행한다.
preds = clf.predict_proba(app_test.drop(['SK_ID_CURR'], axis = 1))[:, 1]
#예측 값을 테스트의 TARGET 에 최종적으로 넣어주고 출력해보자.
app_test['TARGET'] = preds
app_test["TARGET"].head()

#CSV 파일로 만들자
app_test[['SK_ID_CURR', "TARGET"]].to_csv('app_baseline_01.csv', index = False)
!ls
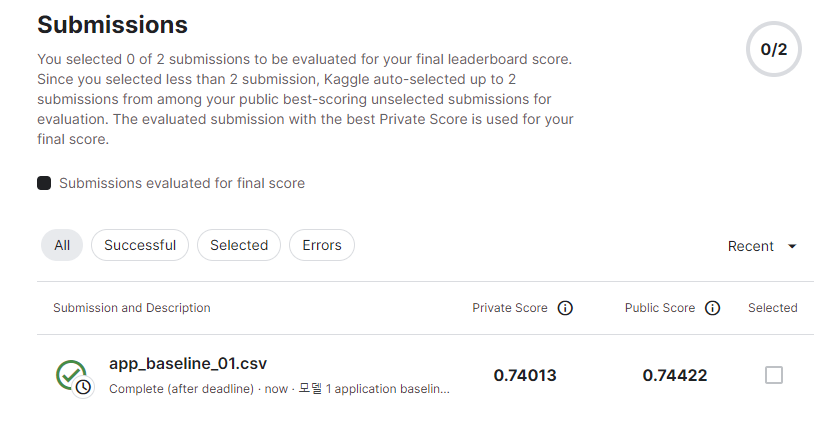
드라이브에 올라간 것을 다운받고 케글에 제출하면 점수를 확인할 수 있다.