케라스를 사용해 ResNet-34 CNN 구현하기
케라스를 사용해 직접 ResNet-34를 구현해보자. 구현할 모델의 구조는 다음과 같다.
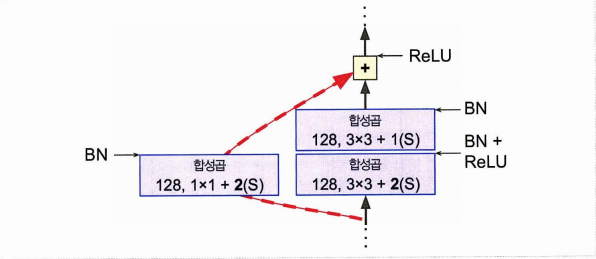
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
DefaultConv2D(filters, strides=strides),
keras.layers.BatchNormalization(),
self.activation,
DefaultConv2D(filters),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
DefaultConv2D(filters, kernel_size=1, strides=strides),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)- main layers 는 오른쪽 모듈, skip layers 는 왼쪽 모듈
- call() 메서드에서 입력이 들어오면 main 과 skip 에 통과시키고, 출력을 더하고, 활성화 함수 적용
- 이렇게 만든 ResidualUnit 층을 반복 활용하여 Sequential 모델 하나를 만들 수 있음.
model = keras.models.Sequential()
model.add(DefaultConv2D(64, kernel_size=7, strides=2,
input_shape=[224, 224, 3]))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="SAME"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))- 처음 3개의 RU는 64개의 필터, 다음 4개의 RU는 128개의 필터를 가지도록 구성
- 필터 개수가 동일할 경우는 스트라이드 1로 설정 (동일하지 않은 경우 2로 설정)
- 그다음 ResidualUnit 을 더하는 구조
현재 만들어 본 몇 줄 안되는 코드가 ILSVRC 2015년 대회 우승 모델이다!
케라스 제공 사전 훈련 모델 사용하기
그러나 사실 GoogLeNet, ResNet 과 같은 표준 모델을 직접 구현할 필요가 없다.
사전 훈련된 모델을 keras.applications 패키지에서 불러오는 방식!
model = keras.applications.resnet50.ResNet50(weights="imagenet")- 위 코드는 패키지에서 ResNet-50 모델을 만듦과 동시에
- 이미지넷 데이터셋에서 사전 훈련된 가중치를 다운로드 하는 방식이다.
images_resized = tf.image.resize(images, [224, 224])
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
Y_proba = model.predict(inputs)이미지를 가져온 후, 이미지의 사이즈를 재조정하고 인풋을 만드는 코드이다. 인풋을 만든 후에는 간단한 예측을 수행한다!
- ResNet-50 모델은 224 x 224 사이즈를 필요로
- 앞에서 0과 1사이로 바뀐 값에 255를 다시 곱해준다.
- 만든 예측은 하나의 행 (이미지)에 각각 하나의 클래스에 대한 확률값을 반환한다. 최상위 k개만 보고싶다면 decode_predictions(Y_proba, top = 3) 이용
다른 문제 - 분류와 위치 추정
단순한 분류 이외에도 사진에 있는 꽃이 어디에 있는지 > 회귀 문제이다.
- 바운딩 박스를 예측한다고 하며
- 물체 중심의 수평, 수직 좌표와 높이, 너비를 예측(4개의 숫자 에측)
- 아래 코드에서는 base 모델 선언 > 전역 폴링 > 아웃풋 1. 클래스 예측 2. 4개의 숫자 예측 > 모델 컴파일 순서이다.
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.models.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # 어떤 것을 중요하게 생각하느냐에 따라
optimizer=optimizer, metrics=["accuracy"])- 꽃 데이터셋은 실제 바운딩 박스를 가지고 있지 않아 직접 추가
- VGG Image Annotator, LabelImg, OpenLabeler, ImgLab 또는 "Crowdsourcing in Computer Vision" 논문 참조
- 실제 바운딩 박스에 널리 사용되는 지표로 MSE 가 아닌 IoU(Intersection over union) 이 있다.
다른 문제2 - 객체 탐지
객체 탐지 문제를 Object detection 이라 하고, 하나의 이미지에 여러 물체가 등장한다면 분류도 하고, 위치도 추정해보는 것이다.
- 비교적 최근의 과거까지 훈련된 분류기가 이미지를 훑는 방식이 사용되었다.
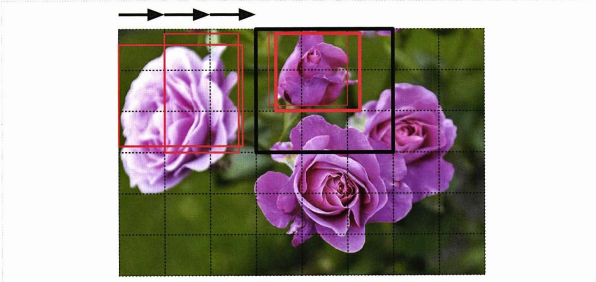
이러한 방식은 CNN을 활용한 방법으로써 쉽지만 불필요한 바운딩 박스를 제거하는 과정(NMS)가 필요하고 CNN을 여러 번 실행시켜야 하므로 느리다.
그래서 등장한 것이 Fully convolutional network 라는 FCN!
1. Fully convolutional network (FCN)
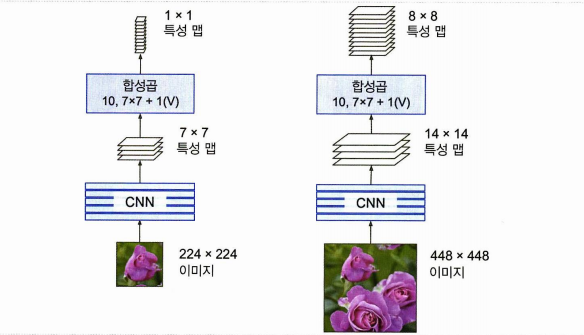
기존 CNN과 차이가 되는 가장 핵심이 되는 아이디어는 CNN위의 밀집층을 합성곱 층으로 바꾸는 것이다!
7X7 맵 크기, 100개의 특성 맵 > 200개 뉴런의 밀집 층
7X7 맵 크기, 100개의 특성 맵 > 7X7 크기 필터 200개와 valid 패딩을 사용하는 합성곱 층 > 1 X 1 특성 맵 200개 출력
- 밀집 층은 입력마다 가중치가 있어 고정된 입력 크기가 필요하지만
- 합성곱 층의 경우 채널 수만 맞춰준다면 입력 크기는 상관 X
- 밀집층의 경우 입력으로 들어온 맵을 가중치를 달리하여 모두 일일히 계산해야 하지만
- 합성곱 층의 경우 맵에 합성곱 층을 한 번만 계산하면 됨. (YOLO)
2. YOLO
- 2015년 레드먼의 You Only Look Once 논문에서 제안된 빠,정 객체 탐지 구조
중요한 차이점은 다음과 같다.
- 각 격자셀마다 1개가 아닌 5개의 바운딩 박스가 출력된다. (ex. 4개의 좌표를 가진 5개의 바운딩 박스, 5개의 존재여부 점수, 20개의 클래스 확률)
- YOLOv3 의 경우 바운딩 박스 중심의 절대 좌표가 아닌 격자 셀에 대한 상대 좌표를 예측
- 훈련 전 앵커박스라 부르는 5개의 대표 바운딩 박스 크기를 찾는다.(k-평균 알고리즘을 높이와 너비에 적용) > 스케일을 얼마나 다시 조정할 것인지 예측.
- 다른 스케일의 이미지를 적절히 활용하여 훈련
다른 문제 3- 시맨틱 분할 (Semantic Segmentation)
이전 작업에서(바운딩 박스를 그리는) 나아가 픽셀 단위에서 속한 객체의 클래스를 나타내는 것을 Semantic Segmentation 이라 한다.

-
보통의 CNN은 점진적으로 위치 정보를 잃어(그래서 RNN이 등장했었다.) 정확도가 떨어진다.
-
단순한 해결책으로 여기서도 역시나 FCN을 사용한다
-
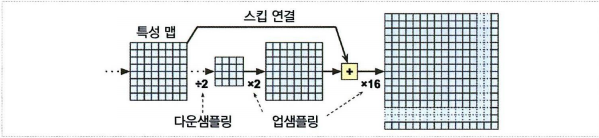
CNN이 이미지에 적용하는 스트라이드의 전체는 32로 최종 해상도가 너무 떨어진다
-
해상도를 늘리기 위해 업샘플링 층을 추가한다
-
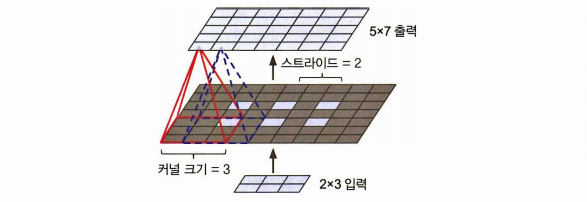
전치 합성곱 층(transposed convolutional layer) 을 사용
-
이미지에 빈 행, 열을 삽입하여 늘린다음 합성곱을 수행하는 것.
-
정리하면, CNN에 2배 업샘플링, 동일한 크기의 아래층 스킵 연결, 8배 업샘플링하는 단계 추가
CV분야에서 연구, 구조를 나열하면 다음과 같다.
- Adversial learning
- explainability
- image generation
- single shot learning
- Capsule networks
