Abstract
지난 10년 동안 audio classifiaction에서 CNN이 주요하게 사용됐음
하지만 CNN에 대한 의존이 필요한지, 순전히 어텐션에만 기반한 신경망이 audio classification에서 좋은 성과를 얻기에 충분하지 않은지 불분명함
따라서 이 논문에서 convolution-free한, 순전히 attention-based인 AST를 소개하며 그 궁금증들에 답함
1. Introduction
Audio classification에서 특히 공간적 지역성과 translation equivariance와 같은 CNN에 내재된 inductive bias가 유용하다고 여겨지며 널리 사용되어 왔음
더 넓은 범위의 맥락을 이해하기 위해, CNN과 self-attention이 결합된 하이브리드 모델들이 audio classification의 여러 task들에서 SOTA의 결과를 얻었음
그러나, vision 도메인에서 오로지 어텐션 기반의 모델들의 성공을 보면 여전히 audio classification에 CNN이 필수적인지 의문을 갖는 것은 합리적임
이 의문에 답하기 위해 Audio Spectrogram Transformer(AST)를 소개함
이 모델은 convolution-free하고 순전히 attention-based 모델로 오디오 스펙트로그램에 직접 적용되며, 가장 낮은 층에서도 장기적인 전역 문맥을 포착할 수 있음
추가적으로 ImageNet 에서 사전 학습된 Vision Transformer (ViT)의 지식을 AST로 전이하는 접근법을 제안함
< AST의 장점 >
- AST는 모든 데이터셋들에서 SOTA를 능가하는 훌륭한 성능을 보임
- AST는 다양한 길이의 input을 허용하고 아키텍쳐의 어떠한 변화도 없이 다른 task들에 적용 가능함
- 대조적으로 CNN기반 모델들을 각기 다른 task들에 최적의 성능을 보이기 위해 아키텍처 조정이 필요함
- CNN기반 SOTA 모델과 비교했을 때, AST는 적은 파라미터들로 간단한 아키텍쳐를 갖고 훈련 중 더 빠르게 수렴함
🖇️ Related Work
AST는 이름에서도 알 수 있듯이 Transformer 아키텍처에 기반함
vision task를 위한 Transformer 모델인 ViT는 AST와 유사함
둘은 비슷한 구조를 갖지만 ViT는 오로지 고정된 차원들의 input들에 적용되고 AST는 다양한 길이의 audio input들에 적용가능함
추가로, ImageNet에서 사전 학습된 ViT의 지식을 AST로 전이하는 접근법을 제안함
2. Audio Spectrogram Transformer
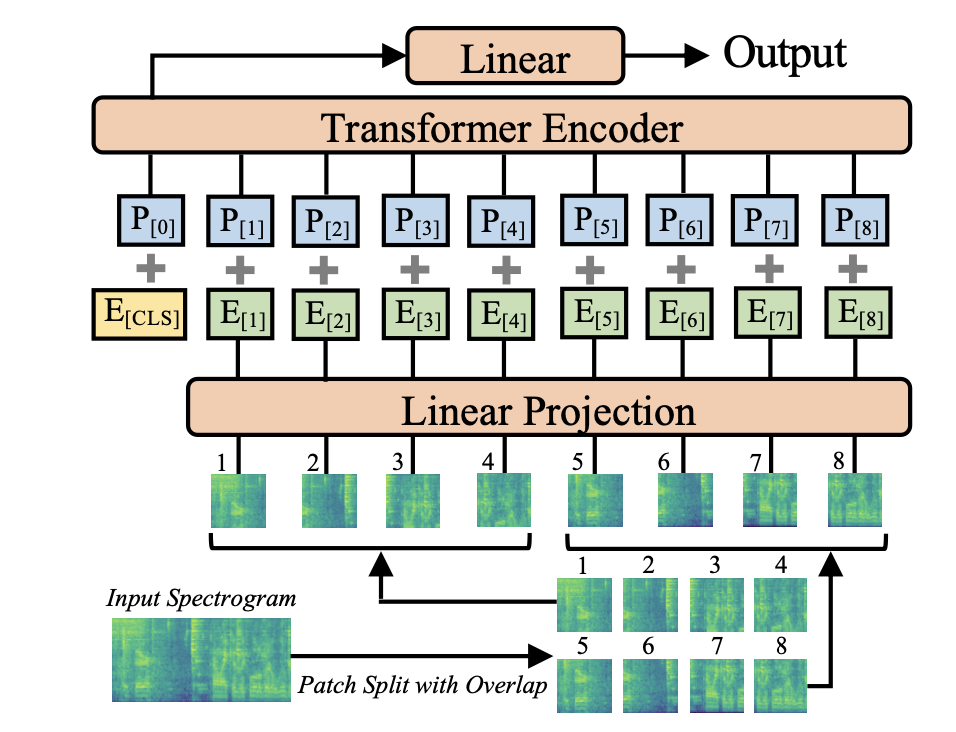
2.1. ModelArchitecture
< Input Spectrogram >
t초의 audio waveform input은 25ms의 hamming 윈도우를 사용하여 매 10ms마다 계산된 128차원의 로그 멜 필터뱅크(fbank) 특징 시퀀스로 변환됨
이는 입력으로 128 × 100t 스펙트로그램을 생성함
< Patch Split with Overlap >
spectrogram을 시간과 주파수 차원에서 6씩 겹치는 N개의 16x16 패치 시퀀스로 나눔
여기서 N은 패치의 수이며 Transformer의 유효 입력 시퀀스 길이
N = 12⌈(100t − 16)/10⌉
< Linear Projection >
각 16 x 16 패치를 선형 projection layer를 사용해서 768 크기의 1차원 패치 임베딩으로 평탄화
선형 projection layer는 패치 임베딩 layer로 여긴다
< Positional embedding >
모델이 2차원 audio spectrogram의 공간적 구조를 포착하도록 각 패치 임베딩에 학습가능한 positional embedding을 추가함
< [CLS] token >
시퀀스의 시작에 [CLS] 토큰을 추가함
AST는 classification task를 위해 고안됐기 때문에, 오직 기존의 transformer와 동일한 encoder만을 사용함
이런 간단한 setup은 구현하기 쉽고, 복제가 가능하고, AST에 전이 학습을 적용할 계획이며, 표준 아키텍처는 전이 학습을 더 쉽게 만듦
2.2. ImageNet Pretraining
CNN과 비교했을 때 transformer의 단점은 학습을 위한 데이터가 더 필요하다는 것이다
이 문제를 해결하기 위해 이미지와 오디오 스펙트로그램의 유사성을 활용해 AST에 교차 모달리티 전이 학습을 적용함
기존의 전이 학습 연구는 CNN 기반 모델에만 적용되었으나, 우리는 ImageNet에서 사전 학습된 Vision Transformer(ViT)를 AST에 적용할 것임
따라서 이 논문은 사전 학습된 ViT를 AST에 맞게 조정하여 전이 학습을 진행
ViT와 AST는 유사한 아키텍처를 가지고 있지만, 입력 형식이 다르기 때문에 몇 가지 수정이 필요
< 수정 사항 #1 >
- ViT는 3채널 이미지를 입력으로 받고 AST는 단일 채널 스펙트로그램을 입력으로 받음
- 이를 위해 ViT의 패치 임베딩 레이어의 3채널 가중치를 평균화하여 AST에 적용
- 또한 평균과 표준편차가 0,0.5가 되도록 input audio spectrogram을 정규화
< 수정 사항 #2 >
- 오디오 스펙트로그램의 가변적인 길이를 처리하기 위해 positional embedding을 잘라내기 및 이중 선형 보간 방법으로 조정
- 예를 들어, ViT는 384x384 이미지 입력을 16x16 패치로 나누지만, AST는 10초의 오디오 입력을 12x100 패치로 나누어 위치 임베딩을 조정
- 이 작업을 통해 input 크기가 다름에도 2차원 공간적 지식을 사전학습된 ViT에서 AST로 전이할 수 있음
< 수정 사항 #3 >
- 분류 작업이 다르므로 ViT의 마지막 분류 레이어를 재초기화하여 AST에 맞게 조정
- 이러한 적응 프레임워크를 통해 AST는 다양한 사전 학습된 ViT 가중치를 초기화에 사용할 수 있음
본 연구에서는 CNN knowledge distillation으로 훈련된 DeiT의 사전 학습된 가중치를 사용함. 또한, DeiT는 ImageNet 훈련 동안 두 개의 [CLS] 토큰을 가지므로, 이를 평균화하여 오디오 훈련에 사용함.
3. Experiments
3.1.2. AudioSet Results
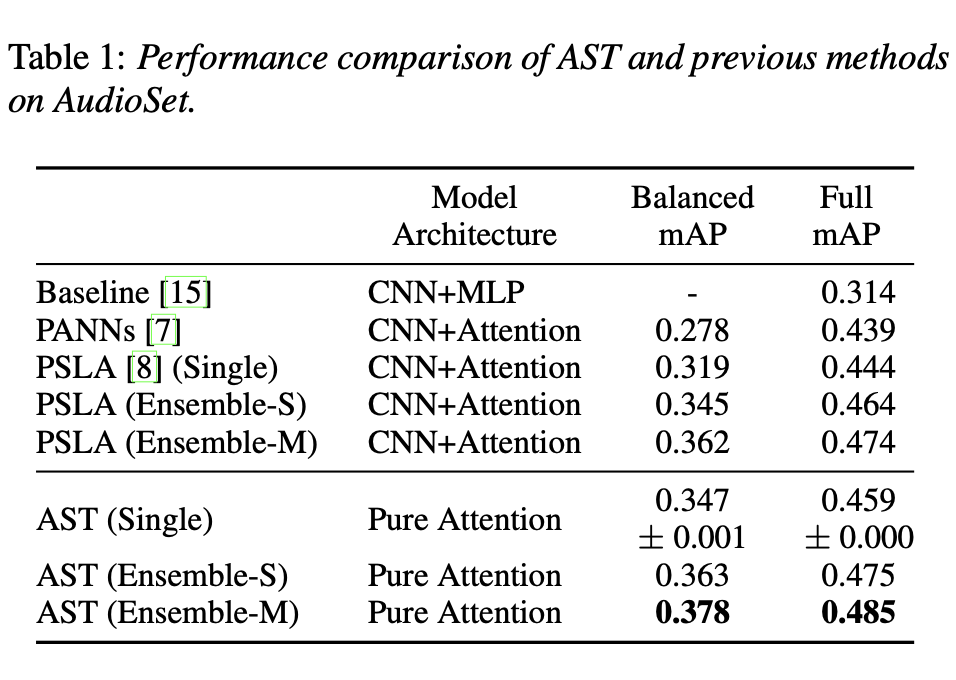
< 전체 데이터셋 실험 결과 >
- AST(Average Spectrogram Transformer)는 전체 AudioSet 데이터셋을 사용한 훈련에서 마지막 에포크에 0.448 ± 0.001의 mAP(mean Average Precision)을 기록
- 가중치 평균화(weight averaging)와 앙상블(ensemble) 전략을 통해 성능을 더욱 향상시켰으며, 가중치 평균화 모델은 0.459 ± 0.000의 mAP를 기록
- 앙상블 모델은 0.475에서 0.485 mAP 범위의 성능을 보이며 해당 데이터셋에서 가장 좋은 성능을 보임
< 밸런스드 데이터셋 실험 결과 >
- AST는 적은 양의 데이터셋에서도 이전 최고의 시스템보다 우수한 성능을 보임
- 밸런스드 데이터셋에서 가중치 평균화 모델은 0.347 ± 0.001, 앙상블 모델은 0.378 mAP를 기록
- 이는 AST가 데이터 양이 적은 상황에서도 CNN-어텐션 하이브리드 모델보다 더 좋은 성능을 발휘할 수 있음을 보여줌
< 결론 >
- AST는 적은 데이터 양에서도 빠르게 수렴하며, CNN-어텐션 하이브리드 모델보다 빠르게 훈련이 완료됨
- 전체 데이터셋을 사용하는 실험에서 AST는 5 에포크만에 수렴한 반면, CNN-어텐션 하이브리드 모델은 30 에포크가 필요했음
- AST는 다양한 오디오 분류 작업에서 뛰어난 성능을 보이며, 표준 아키텍처로 다양한 데이터셋에 적용할 수 있음
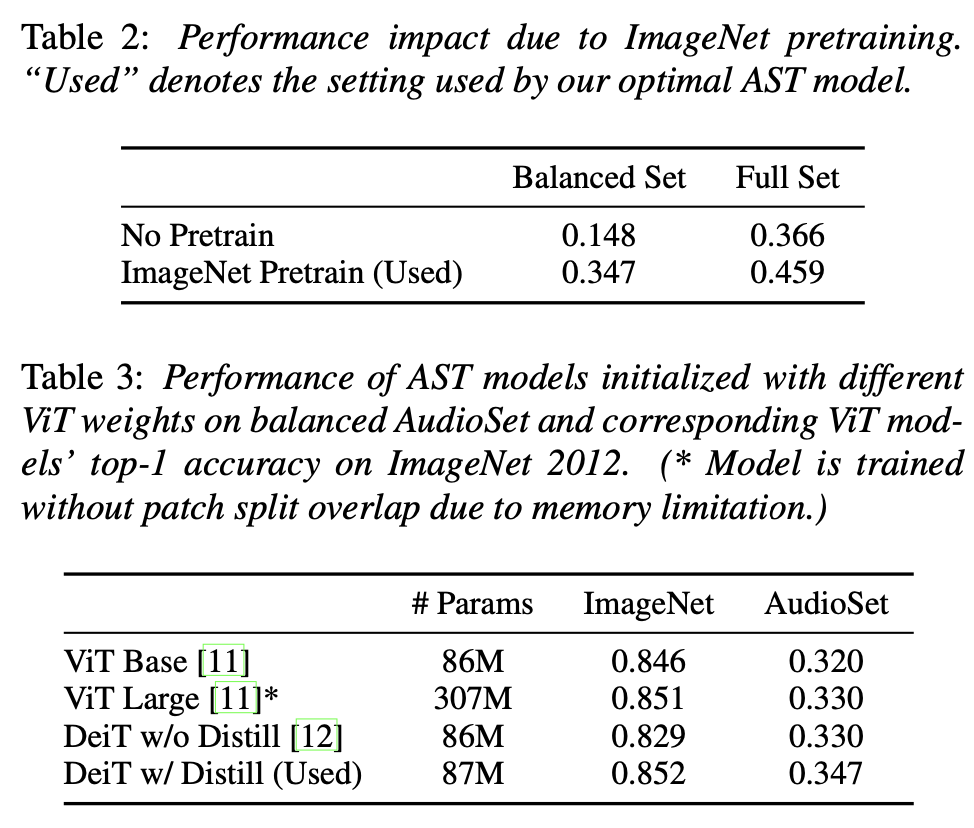
3.1.3. Ablation Study
Impact of ImageNet Pretraining
- ImageNet으로 사전 학습된 AST는 무작위로 초기화된 AST보다 성능이 우수
- 밸런스드 및 전체 AudioSet 실험에서 사전 학습된 모델이 더 좋은 결과를 보임
- 사전 학습의 성능 향상은 훈련 데이터가 적을 때 더 두드러졌음
- ViT-Base, ViT-Large, DeiT 모델의 사전 학습된 가중치를 사용한 AST 모델의 성능을 비교
- ImageNet2012에서 최고의 성능을 보인 DeiT 모델의 가중치를 사용한 AST가 AudioSet에서도 최고의 성능을 기록
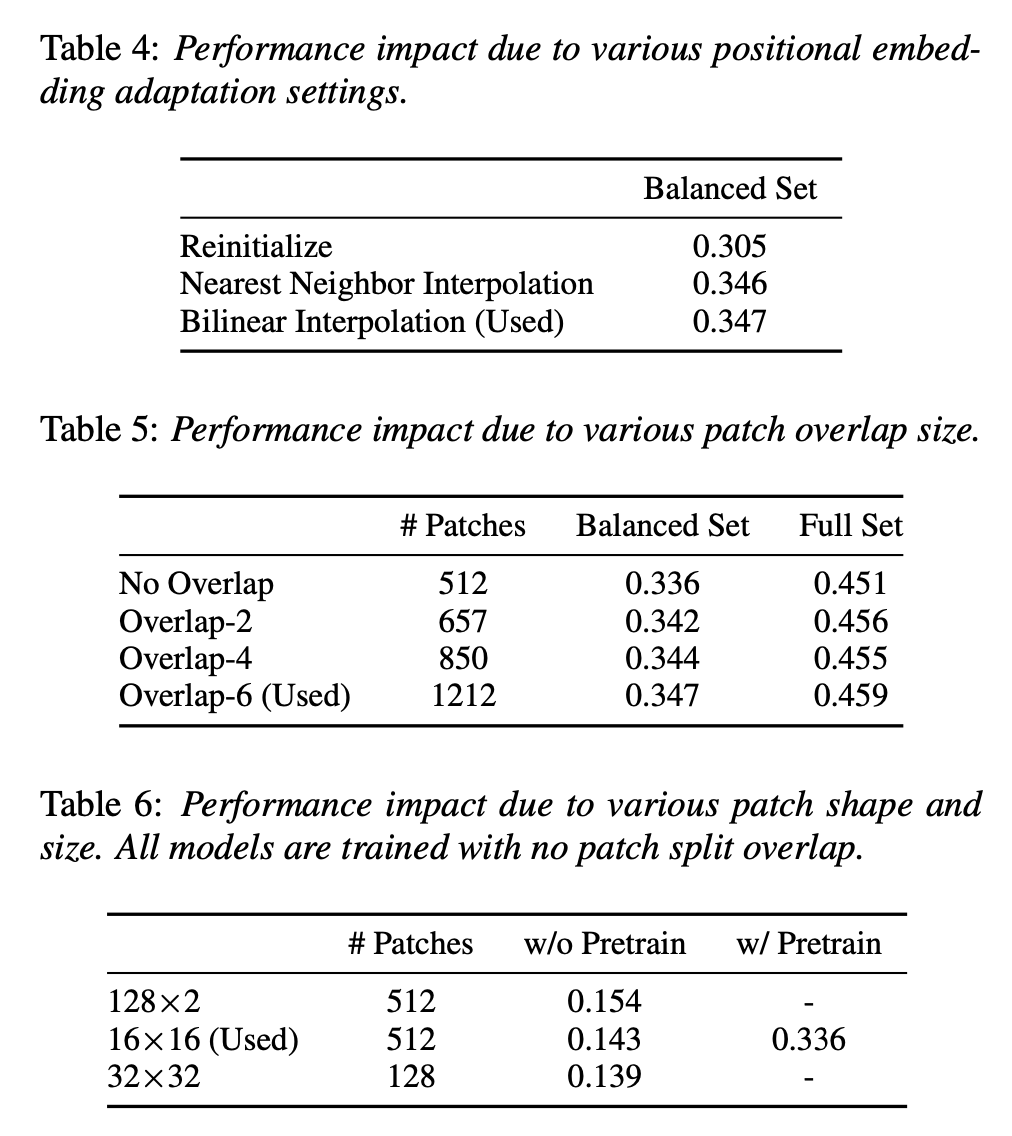
Impact of Positional Embedding Adaptation.
- ViT에서 AST로 지식을 전이할 때 위치 임베딩을 잘라내기(cut) 및 이중 선형 보간(bilinear interpolation) 방법을 사용하여 적응시킴
- 무작위로 초기화된 위치 임베딩을 사용한 모델에 비해, 제안된 방법을 사용한 모델이 더 나은 성능을 보였음
- 이는 공간 정보를 전이하는 위치 임베딩의 중요성을 보여줌
Impact of Patch Split Overlap
- 패치 분할 겹침의 크기를 달리하여 실험한 결과, 겹침 크기가 클수록 성능이 향상됨
- 그러나 겹침 크기가 커질수록 Transformer의 계산 복잡도가 기하급수적으로 증가
- 겹침이 없는 경우에도 AST는 이전 최고의 시스템보다 우수한 성능을 보였음
Impact of Patch Shape and Size
- 오디오 스펙트로그램을 16×16 정사각형 패치로 나누는 방법과 직사각형 패치로 나누는 방법을 비교
- 128×2 직사각형 패치를 사용하는 모델이 16×16 정사각형 패치를 사용하는 모델보다 더 나은 성능을 보임
- 그러나 사전 학습된 ImageNet 모델이 없기 때문에 16×16 패치를 사용하는 것이 최적의 솔루션으로 남았음
3.2. Results on ESC-50 and Speech Commands
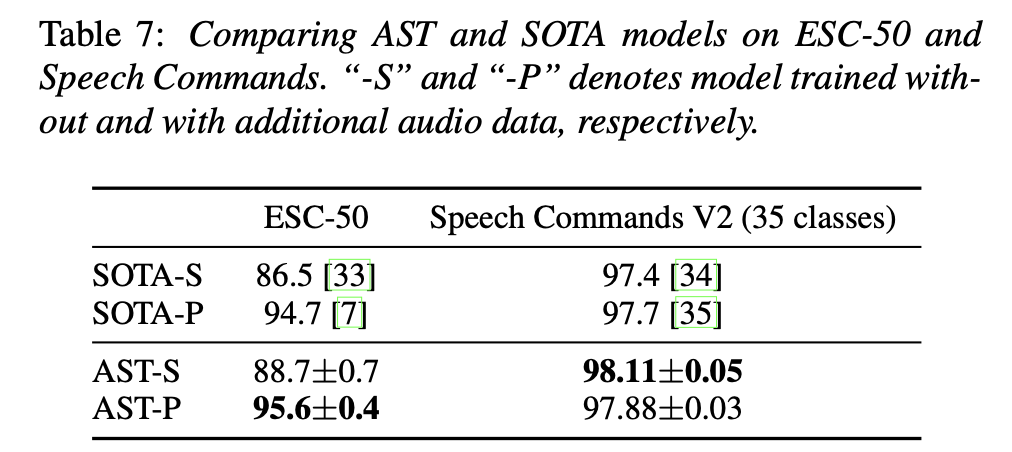
< ESC-50 실험 결과 >
- ESC-50 데이터셋은 50개의 클래스로 구성된 2000개의 5초 환경 오디오 녹음을 포함
- AST 모델은 ImageNet 사전 학습만 사용한 경우(AST-S)와 AudioSet 사전 학습도 추가한 경우(AST-P) 모두에서 최고 성능을 기록
- AST-S는 88.7% ± 0.7%, AST-P는 95.6% ± 0.4%의 정확도를 달성하여 기존 SOTA 모델의 성능을 능가
- ESC-50의 훈련 샘플 수가 적음에도 불구하고, AST는 AudioSet 사전 학습 없이도 뛰어난 성능을 보임
< Speech Commands V2 실험 결과 >
- Speech Commands V2 데이터셋은 35개의 일반적인 음성 명령어로 구성된 105,829개의 1초 녹음을 포함
- AST-S와 AST-P 모델을 모두 평가한 결과, AST-S 모델이 98.11% ± 0.05%로 최고 성능을 보임
- 이는 추가적인 오디오 데이터 사전 학습 없이도 SOTA 모델을 능가하는 성능을 보였음
- AudioSet 사전 학습은 Speech Commands 분류 작업에서 필요하지 않음을 확인함
4. Conclusions
audio classification에서 CNN이 가장 흔히 사용됐지만, 이 논문은 CNN은 필수적이지 않고, 오로지 attention-based한 모델인 AST가 간단한 구조로 좋은 성과를 보일 수 있음을 발견함
