📄참고자료
Abstract
- 자연어 이해는 텍스트 수반, 질문 답변, 의미론적 유사성 평가 및 문서 분류와 같은 광범위하고 다양한 작업으로 구성
- 라벨링 되지 않은 대규모 텍스트 말뭉치는 풍부하지만 이러한 특정 작업을 학습하기 위한 라벨링된 데이터가 부족하여 차별적으로 훈련된 모델이 적절하게 수행하기 어려움
- 이 논문은 라벨링 되지 않은 다양한 텍스트 말뭉치에 대한 언어 모델을 generative pre-training한 다음 각 특정 작업에 대해 차별적인 미세 조정을 통해 위 작업들을 효과적으로 수행
- 이전 접근 방식과 달리 모델 아키텍처를 최소한으로 변경하면서도 효과적인 전송을 달성하기 위해 미세 조정 중에 작업 인식 입력 변환을 사용
- 이 논문의 보다 일반적인, 작업에 구애받지 않는 모델은 각 작업에 대해 특별히 제작된 아키텍처를 사용하는 차별적으로 훈련된 모델보다 성능이 뛰어남
1 Introduction
[ 기존 자연어 처리 방법들과 이 방법들의 주요 문제점 ]
원시 텍스트로부터 효과적으로 학습할 수 있는 능력은 자연어 처리(NLP)에서 감독된 학습에 대한 의존성을 완화하는 데 중요
대부분의 딥 러닝 방법은 상당한 양의 수동으로 레이블이 지정된 데이터를 필요로 하며, 이는 주석이 달린 리소스가 부족한 많은 도메인에서의 적용 가능성을 제한
이러한 상황에서 레이블이 없는 데이터로부터 언어 정보를 활용할 수 있는 모델은 더 많은 주석을 수집하는 것보다 대안을 제공
또한 unsupervised 방식으로 좋은 표현을 학습하는 것이 상당한 성능 향상을 제공
레이블이 없는 텍스트로부터 단어 수준 이상의 정보를 활용하는 것은 두 가지 주요 이유로 어려움이 있음
- 전이에 유용한 텍스트 표현을 학습하는 데 가장 효과적인 최적화 목표가 무엇인지 명확하지 않음
- 이러한 학습된 표현을 대상 작업에 효과적으로 전달하는 가장 효과적인 방법 부재
- 기존 기술은 모델 아키텍처에 작업별 변경을 수행하거나 복잡한 학습 체계를 사용하고 보조 학습 목표를 추가하는 것을 포함.
이 논문에서는 unsupervised pre-training + supervised fine tuning을 결합한 semi-supervised language understanding 작업 접근 방법을 탐구
우리의 목표는 다양한 작업에 적은 적응으로 전달할 수 있는 보편적인 표현을 학습하는 것
우리는 레이블이 없는 대규모 텍스트 코퍼스와 수동으로 주석이 달린 훈련 예제가 포함된 여러 데이터 세트(대상 작업)에 액세스할 수 있다고 가정
- 이러한 대상 작업이 레이블이 없는 코퍼스와 동일한 도메인에 있을 필요는 없음
두 단계 훈련 절차
- 먼저, 레이블이 없는 데이터에서 언어 모델링 목표를 사용하여 신경망 모델의 초기 매개변수를 학습
- 그 후, 우리는 해당 supervised 목표를 사용하여 이 매개변수를 대상 작업에 적용
모델 아키텍처로는 Transformer를 사용하며, 이는 기계 번역, 문서 생성, 구문 파싱 등 다양한 작업에서 강력한 성능
2 Related Work
Semi-supervised learning for NLP
준감독 학습은 NLP에 있어서 이 논문이 속하는 범주
이 패러다임은 시퀀스 라벨링이나 text classification 같은 작업에 적용되어 상당한 관심을 받음
초기 접근 방식
- 레이블이 없는 데이터를 사용하여 단어 수준 또는 구문 수준의 통계를 계산한 다음, 이를 supervised model에서 특징으로 사용
- 최근 몇 년 동안 연구자들은 단어 임베딩을 사용하여 다양한 작업에서 성능을 향상시킬 수 있는 이점을 보여주었음. 그러나 이러한 접근 방식은 주로 단어 수준의 정보를 전달하는 데 중점을 두고 있으며, 우리는 더 높은 수준의 의미론을 포착하려고 함
최근의 접근 방식
- 레이블이 없는 데이터에서 단어 수준 이상의 의미론을 학습하고 활용하는 사례를 찾아보면 구문 수준 또는 문장 수준 임베딩은 레이블이 없는 코퍼스를 사용하여 훈련될 수 있으며, 다양한 대상 작업에 적합한 벡터 표현으로 텍스트를 인코딩하는 데 사용됨을 확인.
Unsupervised pre-training
우리의 연구와 가장 밀접한 연구 라인은 언어 모델링 목표를 사용하여 신경망을 사전 훈련한 다음 감독된 작업에서 미세 조정하는 방법으로 텍스트 분류를 개선했음
그러나 사전 훈련 단계는 일부 언어 정보를 포착하는 데 도움이 되지만, 이 선행 연구는 LSTM 모델을 사용하였는데 이런 접근 방식은 예측 능력을 짧은 범위로 제한함
반면에, 우리의 Transformer 선택은 실험에서 보여준 것처럼 더 긴 범위의 언어 구조를 포착.
또한, 자연 언어 추론, 단어 재배치 감지 및 이야기 완성을 포함한 더 넓은 범위의 작업에서 우리 모델의 효과를 보여줌.
다른 접근 방식은 사전 훈련된 언어 또는 기계 번역 모델에서 숨겨진 표현을 대상 작업에서 감독된 모델을 훈련하는 보조 기능으로 사용. 이는 각각의 별도 대상 작업에 대해 상당한 양의 새로운 매개변수가 필요하며, 반면에 우리는 transfer 중에 모델 아키텍처에 최소한의 변경만을 요구
Auxiliary(보조) training objectives
보조 비감독 훈련 목표를 추가하는 것은 semi- supervised learning 의 또 다른 형태.
우리의 실험에서도 보조 목표를 사용하지만, 비감독 사전 훈련은 이미 대상 작업에 관련된 여러 언어 측면을 학습함
3 Framwork
두단계를 거치며 학습함
🚨 [사전훈련 단계] 대규모 원시 텍스트 코퍼스에서 대용량 언어 모델 학습
🚨 [미세조정 단계] 원하는 작업에 따라 레이블 있는 데이터 활용해 차별적으로 모델 적응시킴
3-1 Unsupervised pre-training
🚨 언어 모델로 다층 Transformer 디코더를 사용 < = > 다음에 나올 단어를 맞추도록 학습 Next Word Prediction

트랜스포머 디코더와의 차이점
- cross self attention 계층 제거됨
- transformer와 달리 encoder이 없기 때문
- cross self attention 계층은 Encoder의 입력과 Decoder의 입력을 Cross Attention 하는 역할
Encoder를 사용하지 않는 이유
- gpt1은 다음 단어를 예측하는 방법을 사용하여 학습하기 때문
- 이는 Decoder가 수행하기에 적합한 문제임
- 이와 정확히 반대 이유로 BERT에서는 Transformer의 Encoder만을 사용
- Decoder 만을 사용하면 모델 구조를 더 간결하게 만들 수 있고 이로 인해 연산량이 줄어드는 장점
gpt1의 디코더 작동 흐름
- 입력 컨텍스트 토큰에 multi-head self attention 적용
- 위치별 feef forward 레이어 사용하여 타깃 토큰에 대한 출력 분포 생성
- : 토큰의 컨텍스트 벡터
- n : 레이어의 수
- W_e : 토큰 임베딩 매트릭스
- W_p : 위치 임베딩 매트릭스
unsupervised loss function
unsupervised인 코퍼스의 토큰 U = {u1, ..., un}를 가지고 표준 언어 모델링 목표를 사용하여 다음과 같은 가능성을 최대화 → maxmize likelihood 최대 우도화 기법
- 최대 우도 추정
우도
- 어떤 확률분포에 대해서 주어진 관측값이 나올 가능성, 분포가 주어졌을 때 값이 관측될 확률
- 우도가 크다 = 해당 데이터가 관측될 가능성이 높다는 것
- 즉 최대 우도 추정이란 여러 개 데이터 관측했을 때 해당 사건들의 발생확률을 최대로 높이는 분포를 찾는 것이 목표
- ⇒ 데이터 가장 잘 설명할 수 있는 분포 찾아내는 것
- k : 컨텍스트 윈도우의 크기
- 조건부 확률 P
🚨 특정한 단어가 만약 i번째라면 i-1 부터 i-k번째까지의 단어를 보고, i번째가 나올 가능성을 최대화하는 방법을 통해 라벨이 없는 데이터에서도 학습이 가능하도록 한다.
즉, i번째 text가 나올 확률에 대해서 최대화 하는 것이기 때문에 maxmize likelihood(우도 최대화) 기법을 loss function으로 설정하여 학습한다!!!
- 역전파 때 확률적 경사 하강법 SGD 사용하여 훈련
3-2 Supervised fine-tuning
🚨 pre-trained 모델의 장점을 살려서 linear+softmax의 layer만 추가하고 그 이전은 freeze시켜서 학습을 진행하여 fine-tuning으로 모델을 학습
목표에 따라 모델을 사전 훈련 후, labeled dataset을 가지는 target task에 대해 매개변수를 적응시킴
input tokens 에 해당하는 label y를 예측해야 할 때, 위 모델의 마지막 트랜스포머 블록의 activation 을 input으로 하는 linear layer를 추가
이를 통해 최대화할 목표
⇒ 학습하고자 할 task에 대한 loss function(최대 우도):
추가적으로 fine-tuning에 auxiliary objective로 LM을 포험하는 것이, supervised model의 generalization을 향상시키고, 모델이 빠르게 수렴하도록하여 학습에 도움이 됨을 확인하였음.
즉 다음의 objective를 최적화.
- : supervised fine- tuning
- : unsupervised pre-training
전반적으로, 미세 조정 중에 필요한 추가 매개변수는 뿐
3-3 Task-specific input transformations
우리는 순회 스타일 접근법을 사용
여기서는 구조화된 입력을 우리의 사전 훈련된 모델이 처리할 수 있는 순서 있는 시퀀스로 변환. 이러한 입력 변환은 작업 간에 아키텍처를 광범위하게 변경할 필요 없이 우리가 효과적으로 미세 조정할 수 있도록 함
모든 변환에는 무작위로 초기화된 시작 및 종료 토큰(<s>, <e>)이 포함됨
각 테스크에 해당하는 입력의 변형
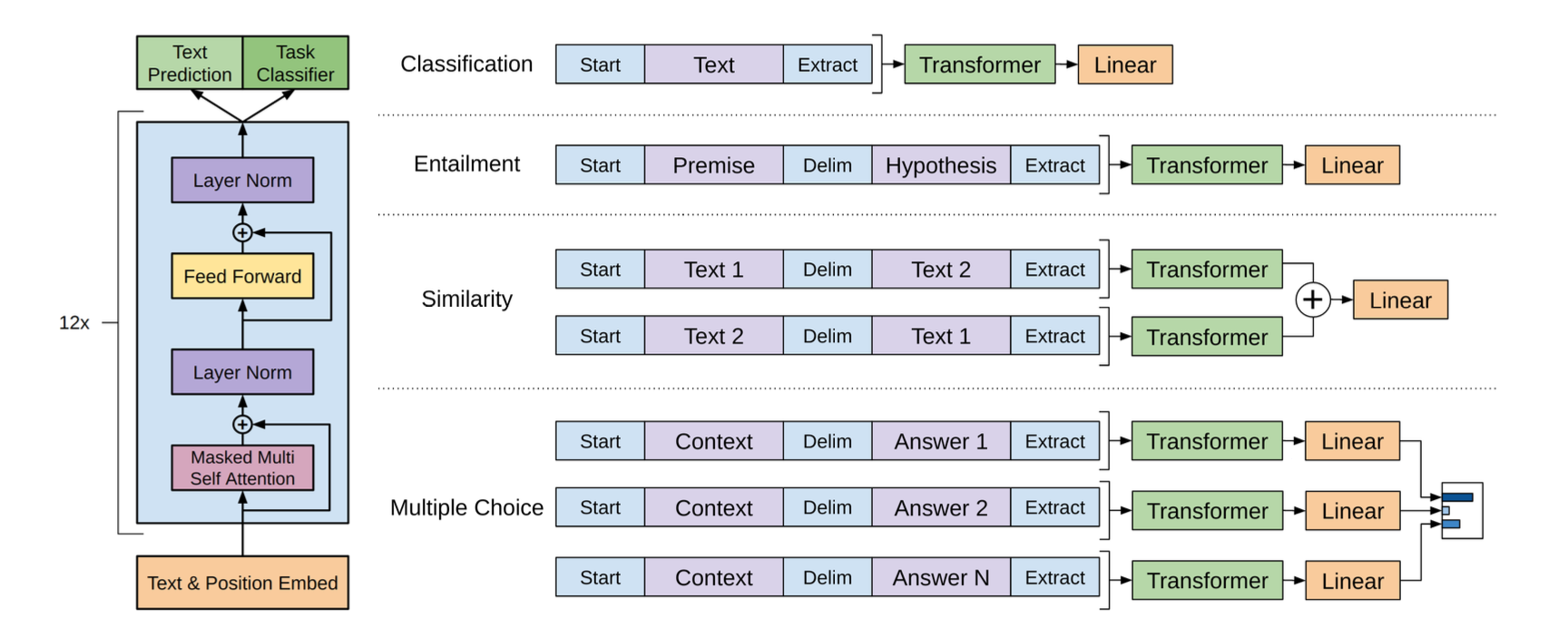
왼쪽 : 트랜스포머 아키텍처, 이 작업에서 사용되는 학습 목표들 / 오른쪽 : 모든 구조화된 입력을 토큰 시퀀스로 변환하여 사전 학습된 모델에서 처리한 다음 선형 소프트맥스 계층을 사용
Textual entailment 텍스트 추론
추론 작업의 경우, 전제 p와 가설 h 토큰 시퀀스를 구분 토큰($), Delim을 사이에 두고 연결
Similarity
유사성 작업의 경우, 비교되는 두 문장 사이에 고유한 순서가 없음
이를 반영하기 위해 입력 시퀀스를 두 가지 가능한 문장 순서(사이에 구분자 포함)로 수정하고 각각을 독립적으로 처리하여 두 시퀀스 표현을 요소별로 추가한 후 선형 출력 레이어로 전달
Question Answering and Commonsense Reasoning
문맥 문서 z, 질문 q 및 가능한 답변 {a_k}이 주어짐
우리는 문서 컨텍스트와 질문을 각 가능한 답변과 함께 연결하고, 사이에 구분 토큰을 추가하여 [z; q; $; a_k]를 얻음.
이러한 각 시퀀스는 우리 모델로 독립적으로 처리된 다음 가능한 답변에 대한 출력 분포를 생성하기 위해 소프트맥스 층을 통해 정규화됩니다.
4 Experiments & 5 Analysis
비지도 사전 학습 - 사용한 데이터셋

비지도 사전 학습 - 모델 세부사항
- 마스크된 셀프 어텐션 헤드를 가진 12계층의 디코더만 있는 트랜스포머 훈련
- 최적화 함수
- Adam 최적화 사용 - 최대 학습률 2.5e-4
- 활성화 함수
- 가우시안 오류 선형 유닛, GELU
지도학습 - 자연어 추론
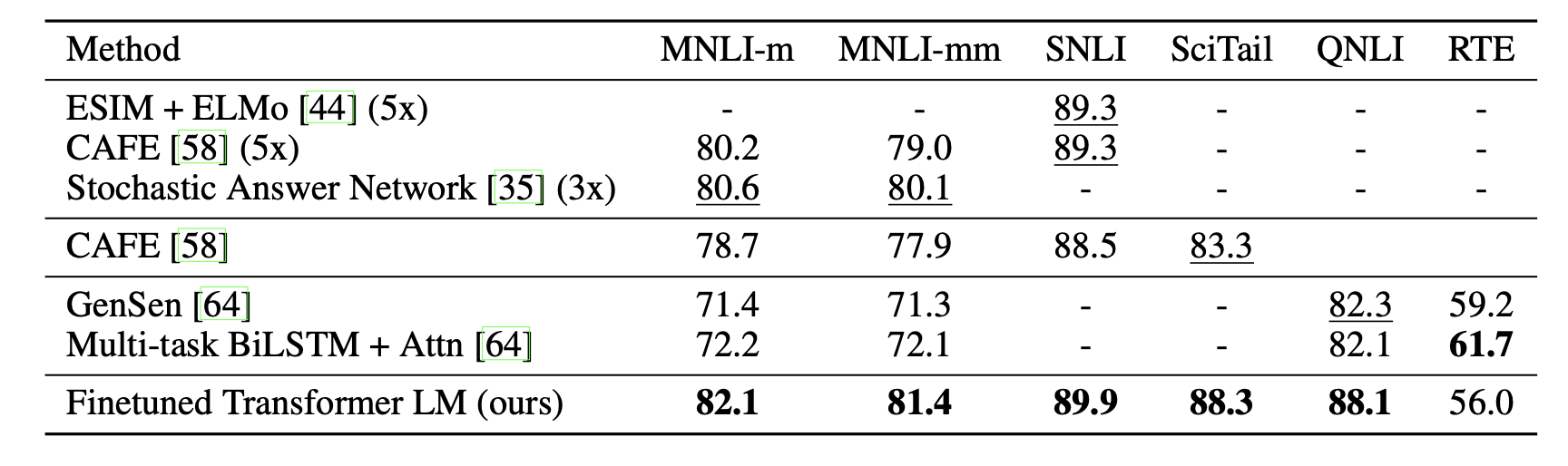
지도학습 - question answering and commonsense reasoning
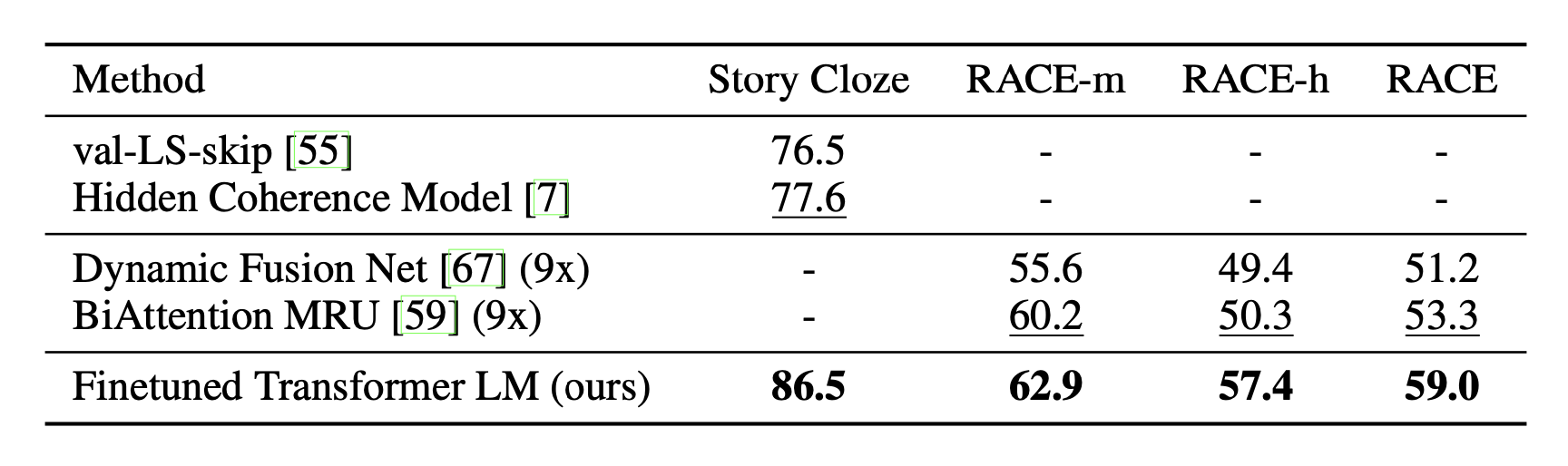
지도학습 - Semantic similarity and classification
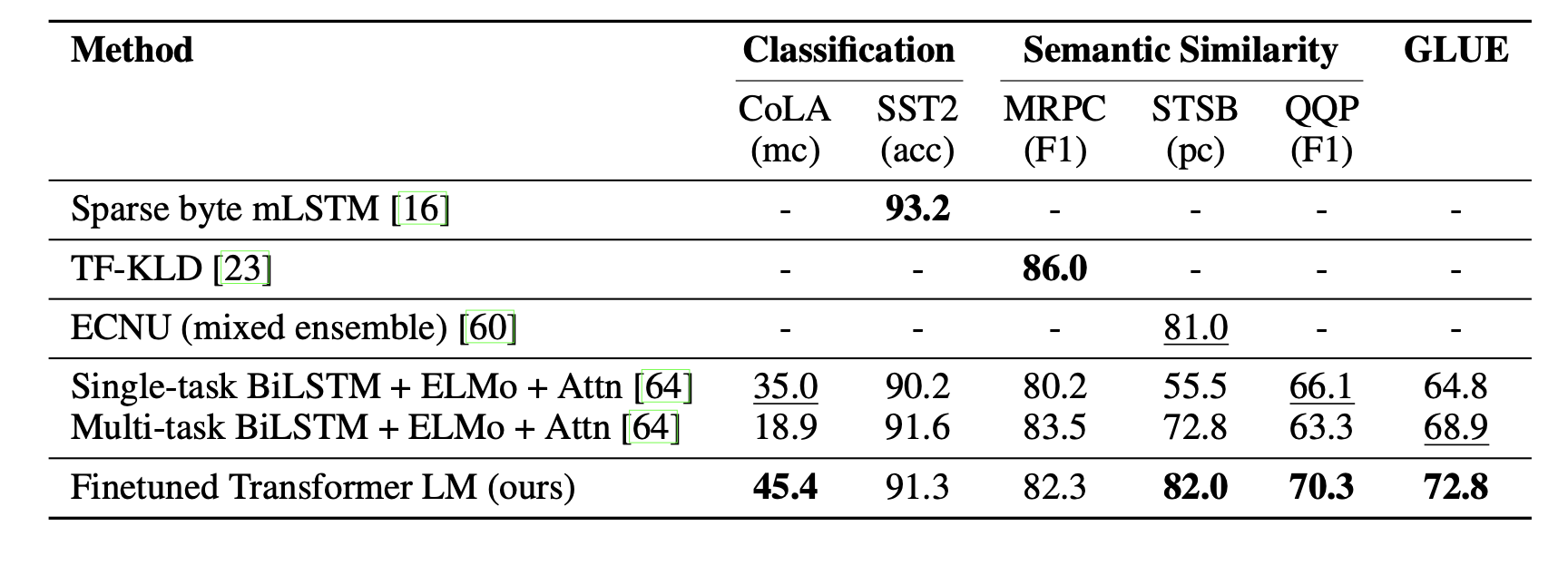
Impact of Number of Layers Transferred & Zero Shot Behaviors
Layer의 개수에 따른 성능과 Zero shot 성능 실험
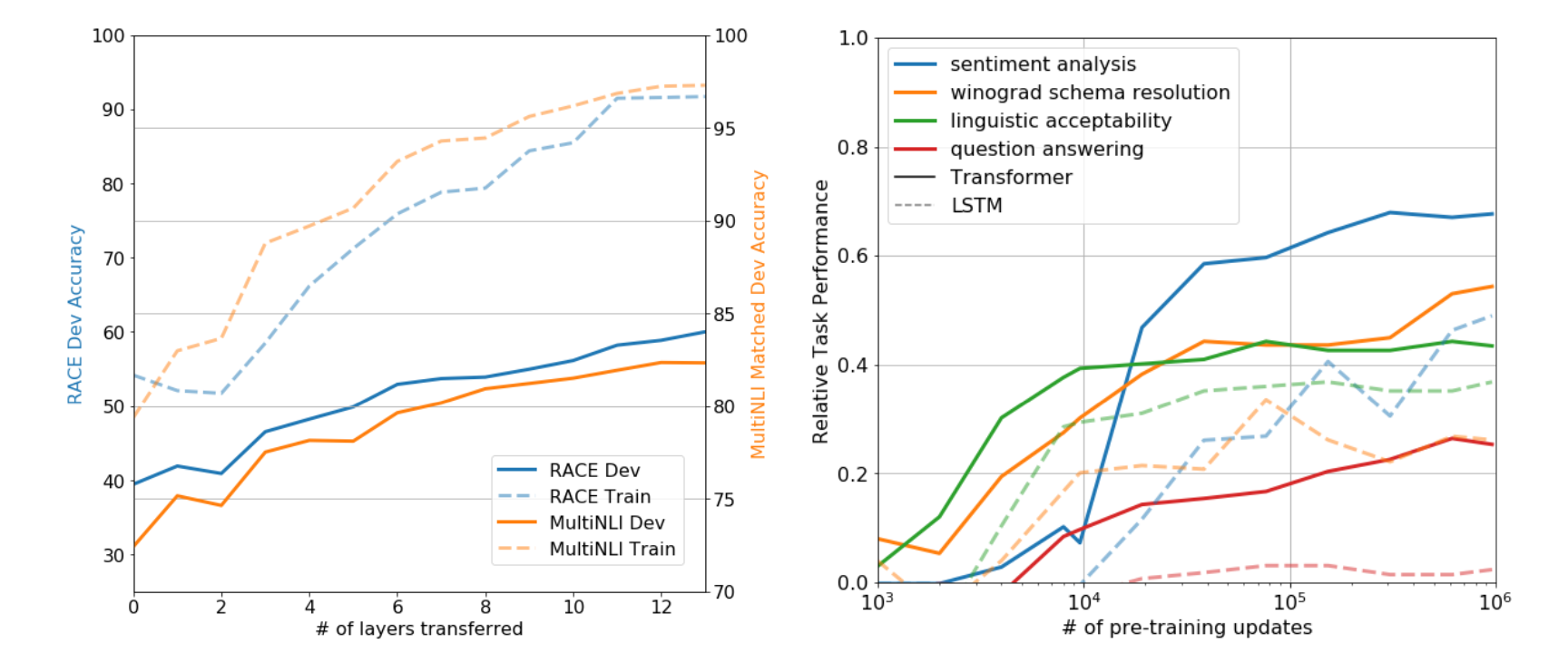
- Transfer에 사용한 Layer 개수에 따른 성능
사용한 레이어가 많을수록 성능 점차 좋아짐
pretrained 정보를 많이 사용할 수록 Fine Tuning 했을때의 성능이 좋다는 의미
결과적으로 Pretrained Model은 Down Stream Task를 해결하기에 유용한 정보를 많이 가지고 있다는것을 알 수 있음
⇒ 즉 GPt-1에서 제안하는 다음 단어 예측하기 학습 방법은 대부분의 Down Stream Task에 적합하다고 결론
- Down Stream Task
- 구체적으로 풀고 싶은 문제들 = gpt와 같이 사전학습 → 파인 튜닝 단계 거치는 모델들이 풀 문제
- Zero Shot 성능
- X 축
- Pre-Training을 진행한 정도
- 실선
- Transformer를 사용한 성능
- 점선
- LSTM을 사용한 성능
- 대부분의 Task에서 Pre-Training을 많이 진행했을수록 성능이 좋으므로, Pre-Training 과정이 대부분의 Down Stream Task에 적합함
- 또한 Transformer 구조가 LSTM보다 탁월함
Ablation
특정 기능 제거해봄으로써 그 기능의 효과를 실험해봄

- L1 Auxiliary Objective의 효과
- Fine Tuning 과정에서 Loss 함수를 Pre-Training Loss와 같이 구성가능
- 이러한 방법을 L1 Auxiliary(보조적인) Objective 라고 표현
- 결과를 보면 이는 NLI, QQP 등 큰 데이터셋에서는 도움이 되고, 작은 데이터셋에서는 도움이 안됨
- LSTM과의 비교
- 전체적으로 LSTM을 사용할 경우 성능이 크게 하락
- 이를 통해 Transformer 구조가 LSTM을 사용하는 구조보다 우수함을 알 수 있음
- Pre-Training의 효과
- Pre-Training을 생략할 경우 아주 크게 성능이 하락
- 이를 통해 GPT-1에서 제안하는 Pre-Training 방식이 효과적이며, 성능에 아주 큰 영향을 준다는 사실을 알 수 있음
