[DL/Audio]HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
[Paper Review]
📄 원문
introduction
대부분의 음성 합성 모델의 2단계 파이프라인
- 멜스펙토그램이나 linguistic feature 같은 low resolution intermediate representation 만듦
- intermediate representation 가지고 raw waveform audio 합성
Wavenet은 2번째 단계에 사용되는 모델이었음. 하지만 이는 AR구조 때문에 높은 temporal resoltuion audio를 합성하기에 너무 오랜 시간이 걸림. 이를 해결하기 위해 Flow- based generative model이 제안됨. 동일한 크기의 noise sequence를 병렬로 변환하여 raw waveform 합성할 수 있기에, 이러한 모델은 sampling 속도가 점점 빨라졌다.
이후에 GAN 기반 음성 합성 deep generatvie model들이 등장했다. MelGAN은 generator가 cpu에서도 실시간 합성을 가능케 하였다. 그이후에도 여러 GAN기반 모델들이 등장했지만 여전히 AR or flow-based model과의 sample quality 사이의 갭이 여전히 존재함
따라서 이 논문에서는 높은 연산 효율성과 이전 모델들보다 더 좋은 sample quality를 보여주는 Hifi-GAN을 제안함. speech audio는 다양한 주기의 신호로 구성돼, 주기적인 패턴을 모델링하는 것이 실제 speech audio를 생성하는 데 중요한 부분임. 따라서 저자들은 작은 sub-discriminator로 구성된 discriminator를 제안함. 각 discriminator는 raw waveform의 특정 주기 부분만 이용함. 이런 구조는 실제 같은 음성 합성을 가능케하는 주된 이유임. audio의 다양한 부분들을 추출하여 discriminator에 사용하기 때문에, 저자들은 병렬로 다양한 길의 패턴을 다루는 여러 residual block을 배치한 모듈을 설계하여 generator에 적용함
여러 모델들과 비교했을 때 더 높은 MOS 점수를 보이고 연산 또한 빨랐음.
HIfi-GAN
< overview >
1개의 generator과 2개의 discriminator로 구성됨. discriminator는 multi-scale & multi-period discriminator임. generator과 discriminator는 학습 안정성과 모델 성능 향상 위해 2개의 추가적 loss 사용하여 적대적으로 학습함.
< generator >
- input : mel-spectorgram
- raw waveform의 temporal resolution과 일치하는 output sequence length 만들도록 transposed convolution을 적용해 upsampling
- 모든 transposed convolution 뒤에 multi-receptive field fusion (MRF) 모듈이 존재
- 이전 연구처럼 noise를 generator의 추가적인 input으로 사용하지 않음
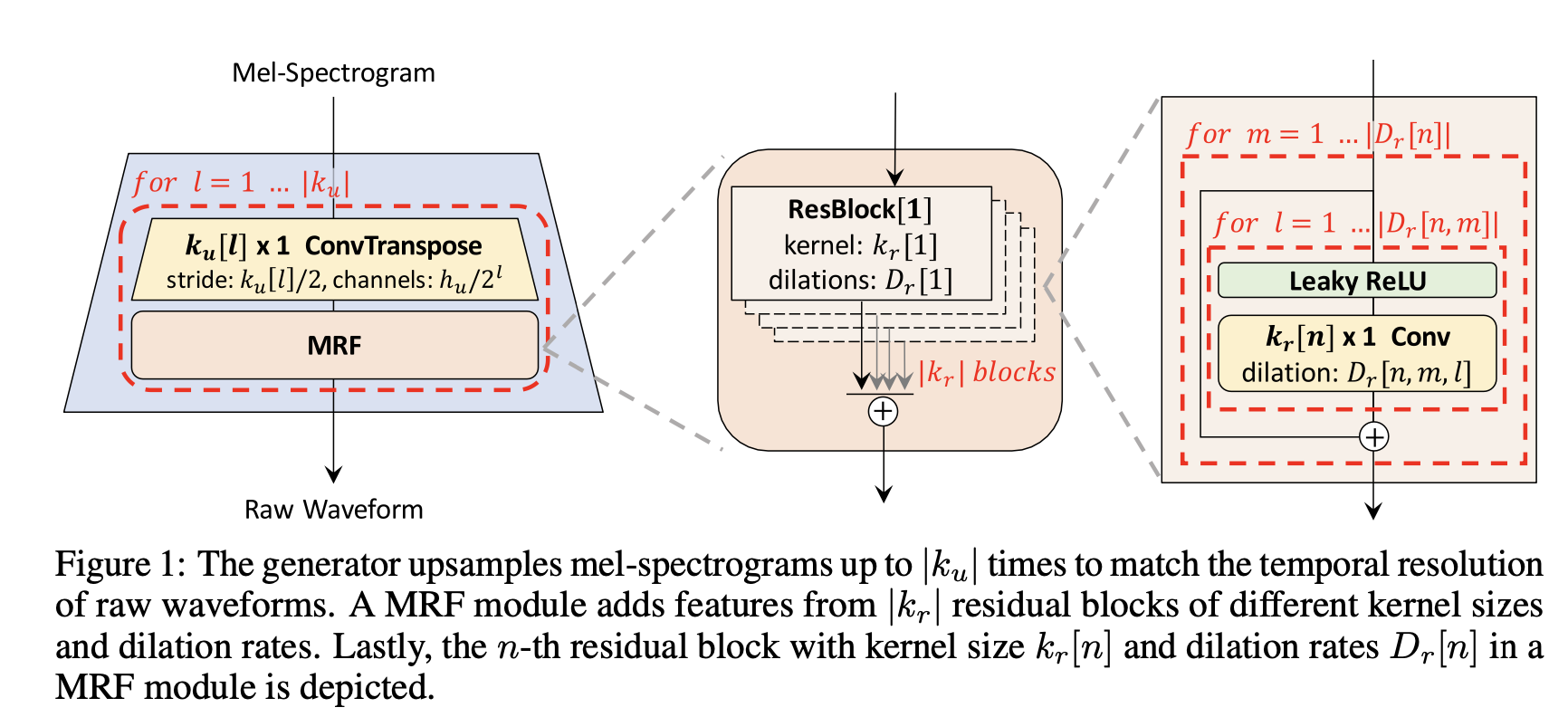
- multi-receptive field fusion
- generator에 사용됨
- 이를 통해 병렬적으로 다양한 길이의 패턴을 관측 가능함
- MRF 모듈은 multiple residual block으로부터 output 받아 더한 후에 반환
- generator에 조절 가능한 파라미터로 hidden dimension :
h_u/ tranposed convolution 의 kernerl size :k_u/ kernel size :k_r/ MRF 모듈의 dilation rate :D_r→ 합성 효율성과 샘플의 퀄리티 사이의 trade-off 맞추기 위한 것
< discriminator >
실제 같은 speech audio를 모델링하기 위해서는 long-term dependencies를 식별하는 것이 핵심임. 예시로 phoneme의 지속기간은 100ms를 넘길 수 있고, 이는 raw waveform에서 2200개 이상의 인접 샘플 간의 높은 상관관계를 초래함. 이런 문제를 generator과 discriminator의 receptive field를 증가시키는 방법으로 해결함.
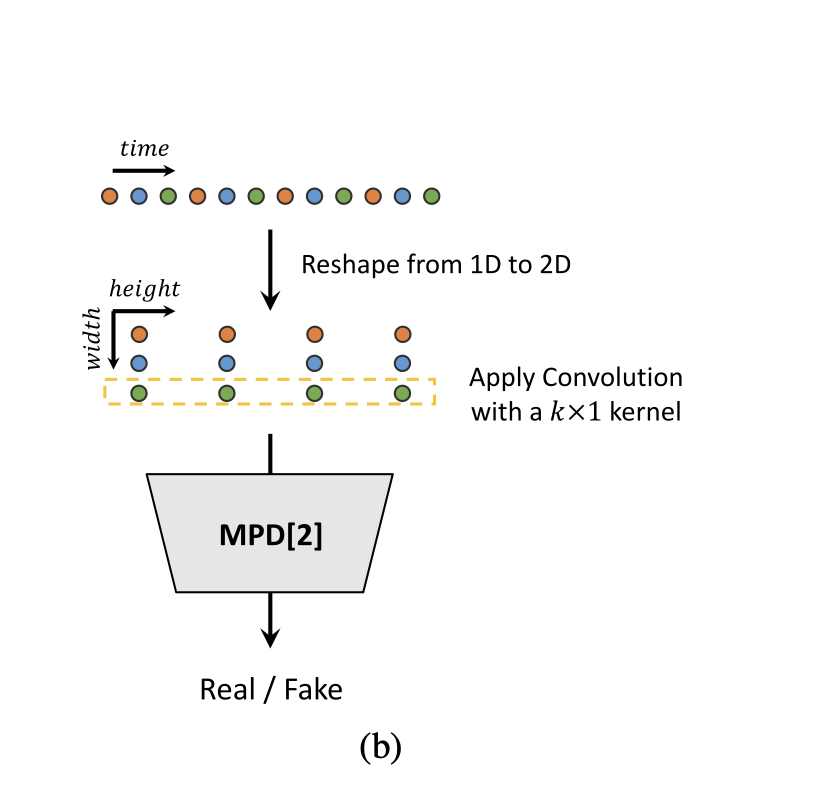
또다른 문제로 speech audio는 다양한 주기를 가진 신호로 구성되기에, audio 데이터에 존재하는 다양한 주기의 패턴을 식별할 필요가 있음. 이를 위해 이 논문은 multi-period discriminaotr (MPD)를 제안함.
MPD는 여러 개의 sub-discriminator로 구성되고, 각 discriminator는 input auido의 각 주기 신호 부분을 처리함. 또한 연속적 패턴과 long-term dependencies를 포착하기 위해 , 저자들은 melGAN에서 제안한 multi-scale discriminaotr(MSD)를 사용함. 이를 통해 다양한 레벨에서 audio sample을 연속적으로 평가함.
- Multi-period discriminator
- 여러개 sub-discriminator로 구성됨
- 각 discriminator는 input audio와 동일한 spaced sample만 수용함( 여기서 space = period p)
- 즉, 각 discriminaotr는 서로 다른 period를 정의하고, input sample 중 p에 해당하는 샘플들이 discriminator에 input됨
- sub-discriminaotr들은 input audio의 서로 다른 파트를 보면서 서로 다른 암묵적 구조를 포착함
- 저자들은 period를 [2,3,5,7,11]로 설정해 가능한 중복을 피했음
- Multi-scale discriminator
- MPD의 각 sub-discriminator들은 분리된 샘플만 수용하기 때문에, MSD도 사용해 audio sequence를 연속적으로 평가함
- MSD구조는 melGAN에서 사용되었던 것과 유사함
- 3개의 sub-discriminaotr로 이뤄져있고, 각 discriminaotr는 서로 다른 input scale에서 작동
- raw audio, x2 average-pooled raw audio, x4 average-pooled raw audio와 같은 형토로 3가지의 서로 다른 스케일에서 작동
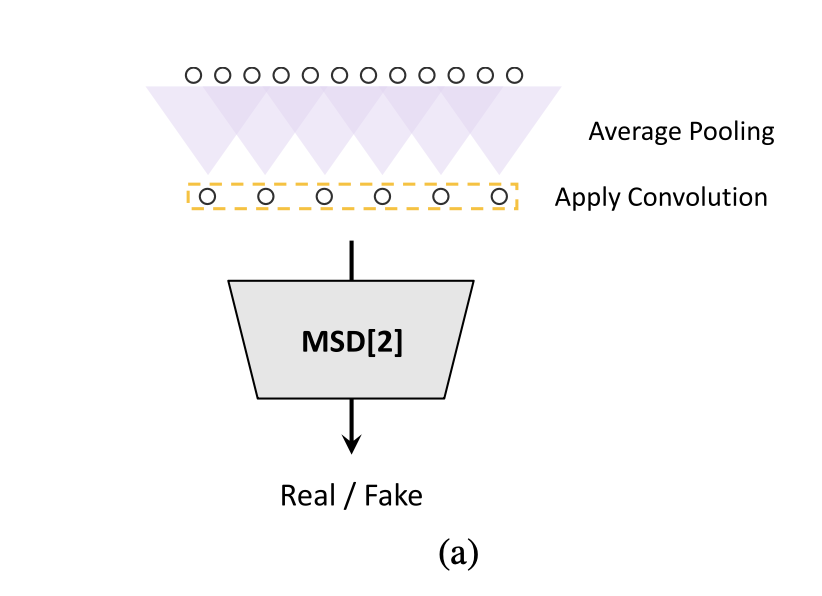
- MSD의 각 sub-discriminator는 strided & grouped conv layer과 leaky ReLU의 stack으로 구성됨
- discriminator size는 stride를 줄이고 layer를 추가함으로써 증가시킴
- raw audio를 처리하는 첫번재 sub-discriminator를 제외하고 나머지들은 weight-normalization을 이행함.
- 그대신 첫번째는 spectral normalization 적용해 학습을 안정적으로 만듦
MPD는 raw waveform에서 분리된 샘플에서 작동하고 MSD는 smoothed waveform에서 작동함
< Training loss >
- GAN Loss
- Mel-spectrogram Loss
- Feature matching Loss
- Final Loss

