
논문에서 소개된 모델 아키텍처의 사용법을 간단히 정리하여 소개하는 포스팅입니다.
Introduction
지난 Revisiting Deep Learning Models for Tabular Data 논문에서는 정형 데이터를 위한 FT-Transformer 아키텍처를 소개하였습니다. Tabular DL 모델 간 성능 실험에서 FT-Transformer는 대부분의 작업에서 최고의 성능을 보여주었습니다.
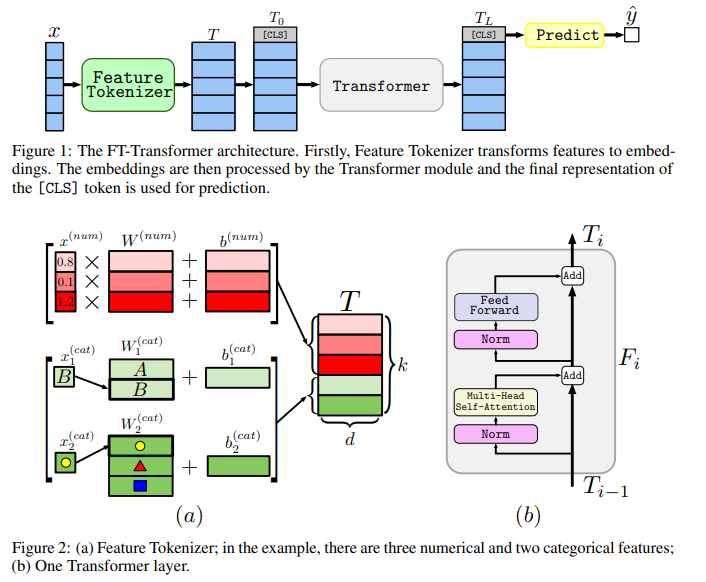
이번 포스팅에서는 rtdl 라이브러리를 통해 정형 데이터를 위한 FT-Transformer 아키텍처의 사용 방법에 대해 간단히 알아보겠습니다. 모델 학습을 위해 PyTorch를 사용하였으며, Optuna 라이브러리를 사용한 하이퍼파라미터 튜닝 예시까지 확인합니다.
사용한 데이터셋은 Adult 데이터셋입니다. 다음과 같은 특징을 가집니다.
- 이진 분류 문제 (소득이 50K 이상인지 판별)
- 숫자형 특성과 범주형 특성이 모두 존재
모든 코드는 Google의 Colaboratory(Colab)에서 구현되었습니다.
Setting
구현에 필요한 패키지를 설치합니다. Colab의 특성상 아래 !pip 코드 블럭을 실행한 후, 런타임을 다시 시작한 뒤 처음부터(!pip 부터) 실행해야 합니다.
# rtdl: ResNet, FT-Transformer
!pip install rtdl
!pip install optunaimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import random
from tqdm import tqdm
import rtdl
from typing import Any, Dict
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import optuna
from optuna import Trial
from optuna.samplers import TPESamplerColab의 GPU를 사용합니다.
# device check
device = ('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using {device} device")출력
Using cuda device
def seed_everything(seed = 21):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Truedef read_split_data():
df = pd.read_csv('/content/drive/MyDrive/Data/adult.csv')
X = {}
y = {}
X['train'], X['test'], y['train'], y['test'] = train_test_split(df.iloc[:, :-1], df.income, test_size = 0.10, random_state=21)
X['train'], X['val'], y['train'], y['val'] = train_test_split(X['train'], y['train'], test_size = 0.10, random_state=21)
return X, yread_split_data()는 adult 데이터셋을 불러와 전체 데이터셋을 훈련 / 검증 / 테스트 데이터셋으로 분할합니다. 아래 코드에는 데이터셋이 Google drive에 저장되어 있는데, 직접 실행을 원하신다면 pd.read_csv()에 적절한 경로를 입력하면 됩니다.
def preprocessing(X, y):
cat_index = X['train'].select_dtypes(['object']).columns
num_index = X['train'].select_dtypes(['int64']).columns
# categorical cardinalities for CategoricalFeatureTokenizer
cat_cardinalities = []
# StandardScaler
ss = StandardScaler()
X['train'][num_index] = ss.fit_transform(X['train'][num_index])
X['val'][num_index] = ss.transform(X['val'][num_index])
X['test'][num_index] = ss.transform(X['test'][num_index])
# float64 -> float32 (recommended)
X['train'][num_index] = X['train'][num_index].apply(lambda x: x.astype('float32'))
X['val'][num_index] = X['val'][num_index].apply(lambda x: x.astype('float32'))
X['test'][num_index] = X['test'][num_index].apply(lambda x: x.astype('float32'))
# LabelEncoder
for col in cat_index:
le = LabelEncoder()
X['train'][col] = le.fit_transform(X['train'][col])
# X_val, X_test에만 존재하는 label이 있을 경우
for label in np.unique(X['val'][col]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
for label in np.unique(X['test'][col]):
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
X['val'][col] = le.transform(X['val'][col])
X['test'][col] = le.transform(X['test'][col])
# cardinalities
max_cat = np.max([np.max(X['train'][col]),
np.max(X['val'][col]),
np.max(X['test'][col])]) + 1
cat_cardinalities.append(max_cat)
# y = 1 if > 50K
y['train'] = np.where(y['train']=='>50K', 1, 0).reshape(-1, 1)
y['val'] = np.where(y['val']=='>50K', 1, 0).reshape(-1, 1)
y['test'] = np.where(y['test']=='>50K', 1, 0).reshape(-1, 1)
return X, y, cat_cardinalitiespreprocessing()을 통해 데이터 전처리를 수행합니다. 적용되는 사항은 아래와 같습니다.
- 숫자형 특성: StandardScaler 적용 후 float32 타입으로 변경
- 범주형 특성: LabelEncoder 적용
- 범주형 특성의 경우 특성마다 카디널리티를 계산하여 리턴
- 타겟값 y(income)는 income이 50K를 초과하면 1, 아니면 0
StandardScaler를 사용한 것은 간단히 사용할 수 있기 때문입니다. 다른 전처리 방법을 사용하셔도 무방합니다.
범주형 특성의 경우 이후 Embedding layer에 입력하기 위하여 LabelEncoder를 사용해야 하고, 모델 입력 시 범주형 특성에 대한 카디널리티가 필요하기 때문에 따로 계산하여 추가합니다.
def setting_rtdl(data, label):
'''
DataFrame, np.array -> torch.Tensor
ResNet: model(X_num, X_cat) / split X -> X_num, X_cat
'''
cat_index = data['train'].select_dtypes(['int64']).columns
num_index = data['train'].select_dtypes(['float32']).columns
X = {'train': {},
'val': {},
'test': {}}
y = {'train': {},
'val': {},
'test': {}}
X['train']['num'] = torch.tensor(data['train'][num_index].values, device=device)
X['train']['cat'] = torch.tensor(data['train'][cat_index].values, device=device)
X['val']['num'] = torch.tensor(data['val'][num_index].values, device=device)
X['val']['cat'] = torch.tensor(data['val'][cat_index].values, device=device)
X['test']['num'] = torch.tensor(data['test'][num_index].values, device=device)
X['test']['cat'] = torch.tensor(data['test'][cat_index].values, device=device)
# dtype=float for BCELoss
y['train'] = torch.tensor(label['train'], dtype=torch.float, device=device)
y['val'] = torch.tensor(label['val'], dtype=torch.float, device=device)
y['test'] = torch.tensor(label['test'], dtype=torch.float, device=device)
return X, ysetting_rtdl()을 통해 데이터를 torch.Tensor로 변환합니다. FT-Transformer의 경우 입력을 model(X_num, X_cat)과 같이 숫자형 특성 데이터와 범주형 특성 데이터를 따로 받기 때문에 이를 분리해 줍니다.
# Dataset with num / cat features (for rtdl)
class TensorData(Dataset):
def __init__(self, num, cat, label):
self.num = num
self.cat = cat
self.label = label
self.len = self.label.shape[0]
def __getitem__(self, index):
return self.num[index],self.cat[index], self.label[index]
def __len__(self):
return self.lendef model_train(model, data_loader, criterion, optimizer, device, scheduler=None):
model.train()
running_loss = 0
corr = 0
# for rtdl
for x_num, x_cat, label in tqdm(data_loader):
optimizer.zero_grad()
x_num, x_cat, label = x_num.to(device), x_cat.to(device), label.to(device)
output = model(x_num, x_cat)
output = torch.sigmoid(output)
loss = criterion(output, label)
loss.backward()
optimizer.step()
pred = output >= torch.FloatTensor([0.5]).to(device)
corr += pred.eq(label).sum().item()
running_loss += loss.item() * x_num.size(0)
if scheduler:
scheduler.step()
# Average accuracy & loss
accuracy = corr / len(data_loader.dataset)
loss = running_loss / len(data_loader.dataset)
history['train_loss'].append(loss)
history['train_accuracy'].append(accuracy)
return loss, accuracydef model_evaluate(model, data_loader, criterion, device):
model.eval()
with torch.no_grad():
running_loss = 0
corr = 0
for x_num, x_cat, label in data_loader:
x_num, x_cat, label = x_num.to(device), x_cat.to(device), label.to(device)
output = model(x_num, x_cat)
output = torch.sigmoid(output)
pred = output >= torch.FloatTensor([0.5]).to(device)
corr += pred.eq(label).sum().item()
running_loss += criterion(output, label).item() * x_num.size(0)
accuracy = corr / len(data_loader.dataset)
loss = running_loss / len(data_loader.dataset)
history['val_loss'].append(loss)
history['val_accuracy'].append(accuracy)
return loss, accuracydef model_tune(model, train_loader, val_loader, criterion, optimizer, device):
model.train()
# train_loader
for x_num, x_cat, label in train_loader:
optimizer.zero_grad()
x_num, x_cat, label = x_num.to(device), x_cat.to(device), label.to(device)
output = model(x_num, x_cat)
output = torch.sigmoid(output)
loss = criterion(output, label)
loss.backward()
optimizer.step()
# val_loader
model.eval()
with torch.no_grad():
running_loss = 0
corr = 0
for x_num, x_cat, label in val_loader:
x_num, x_cat, label = x_num.to(device), x_cat.to(device), label.to(device)
output = model(x_num, x_cat)
output = torch.sigmoid(output)
pred = output >= torch.FloatTensor([0.5]).to(device)
corr += pred.eq(label).sum().item()
running_loss += criterion(output, label).item() * x_num.size(0)
val_accuracy = corr / len(val_loader.dataset)
val_loss = running_loss / len(val_loader.dataset)
return val_loss, val_accuracydef plot_loss(history):
plt.plot(history['train_loss'], label='train', marker='o')
plt.plot(history['val_loss'], label='val', marker='o')
plt.title('Loss per epoch')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
def plot_acc(history):
plt.plot(history['train_accuracy'], label='train', marker='o')
plt.plot(history['val_accuracy'], label='val', marker='o')
plt.title('Accuracy per epoch')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.grid()def ready_data():
# data setting
seed_everything()
X, y = read_split_data()
X, y, cardinalities = preprocessing(X, y)
X, y = setting_rtdl(X, y)
# dataset, dataloader
train_data = TensorData(X['train']['num'], X['train']['cat'], y['train'])
val_data = TensorData(X['val']['num'], X['val']['cat'], y['val'])
test_data = TensorData(X['test']['num'], X['test']['cat'], y['test'])
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
val_loader = DataLoader(val_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=True)
return X, y, cardinalities, train_loader, val_loader, test_loader데이터셋과 모델 훈련과 관련된 함수를 정의합니다.
FT-Transformer의 경우 숫자형 특성과 범주형 특성을 모두 입력 받을 수 있기 때문에 rtdl.FTTransformer.make_baseline()을 사용하여 간단히 모델을 구성할 수 있습니다.
Run
이제 모델을 생성하고 훈련합니다. 모델의 하이퍼파라미터는 임의로 설정하였습니다.
X, y, cardinalities, train_loader, val_loader, test_loader = ready_data()'''
FT-Transformer
Examples:
.. testcode::
x_num = torch.randn(4, 3)
x_cat = torch.tensor([[0, 1], [1, 0], [0, 2], [1, 1]])
module = FTTransformer.make_baseline(
n_num_features=3,
cat_cardinalities=[2, 3],
d_token=8,
n_blocks=2,
attention_dropout=0.2,
ffn_d_hidden=6,
ffn_dropout=0.2,
residual_dropout=0.0,
d_out=1,
)
x = module(x_num, x_cat)
assert x.shape == (4, 1)
Args:
n_num_features: the number of continuous features
cat_cardinalities: the cardinalities of categorical features (see
`CategoricalFeatureTokenizer` to learn more about cardinalities)
d_token: the token size for each feature. Must be a multiple of :code:`n_heads=8`.
n_blocks: the number of Transformer blocks
attention_dropout: the dropout for attention blocks (see `MultiheadAttention`).
Usually, positive values work better (even when the number of features is low).
ffn_d_hidden: the *input* size for the *second* linear layer in `Transformer.FFN`.
Note that it can be different from the output size of the first linear
layer, since activations such as ReGLU or GEGLU change the size of input.
For example, if :code:`ffn_d_hidden=10` and the activation is ReGLU (which
is always true for the baseline and default configurations), then the
output size of the first linear layer will be set to :code:`20`.
ffn_dropout: the dropout rate after the first linear layer in `Transformer.FFN`.
residual_dropout: the dropout rate for the output of each residual branch of
all Transformer blocks.
d_out: the output size.
'''
# embedding dimension = 64
# # of transformer layer = 3
ft_t = rtdl.FTTransformer.make_baseline(n_num_features=X['train']['num'].shape[1],
cat_cardinalities=cardinalities,
d_token=64,
n_blocks=3,
attention_dropout=0.2,
ffn_d_hidden=128,
ffn_dropout=0.1,
residual_dropout=0.1,
d_out=1).to(device)
print(ft_t)출력
FTTransformer(
(feature_tokenizer): FeatureTokenizer(
(num_tokenizer): NumericalFeatureTokenizer()
(cat_tokenizer): CategoricalFeatureTokenizer(
(embeddings): Embedding(102, 64)
)
)
(cls_token): CLSToken()
(transformer): Transformer(
(blocks): ModuleList(
(0): ModuleDict(
(attention): MultiheadAttention(
(W_q): Linear(in_features=64, out_features=64, bias=True)
(W_k): Linear(in_features=64, out_features=64, bias=True)
(W_v): Linear(in_features=64, out_features=64, bias=True)
(W_out): Linear(in_features=64, out_features=64, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffn): FFN(
(linear_first): Linear(in_features=64, out_features=256, bias=True)
(activation): ReGLU()
(dropout): Dropout(p=0.1, inplace=False)
(linear_second): Linear(in_features=128, out_features=64, bias=True)
)
(attention_residual_dropout): Dropout(p=0.1, inplace=False)
(ffn_residual_dropout): Dropout(p=0.1, inplace=False)
(output): Identity()
(ffn_normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(1): ModuleDict(
(attention): MultiheadAttention(
(W_q): Linear(in_features=64, out_features=64, bias=True)
(W_k): Linear(in_features=64, out_features=64, bias=True)
(W_v): Linear(in_features=64, out_features=64, bias=True)
(W_out): Linear(in_features=64, out_features=64, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffn): FFN(
(linear_first): Linear(in_features=64, out_features=256, bias=True)
(activation): ReGLU()
(dropout): Dropout(p=0.1, inplace=False)
(linear_second): Linear(in_features=128, out_features=64, bias=True)
)
(attention_residual_dropout): Dropout(p=0.1, inplace=False)
(ffn_residual_dropout): Dropout(p=0.1, inplace=False)
(output): Identity()
(attention_normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffn_normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(2): ModuleDict(
(attention): MultiheadAttention(
(W_q): Linear(in_features=64, out_features=64, bias=True)
(W_k): Linear(in_features=64, out_features=64, bias=True)
(W_v): Linear(in_features=64, out_features=64, bias=True)
(W_out): Linear(in_features=64, out_features=64, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffn): FFN(
(linear_first): Linear(in_features=64, out_features=256, bias=True)
(activation): ReGLU()
(dropout): Dropout(p=0.1, inplace=False)
(linear_second): Linear(in_features=128, out_features=64, bias=True)
)
(attention_residual_dropout): Dropout(p=0.1, inplace=False)
(ffn_residual_dropout): Dropout(p=0.1, inplace=False)
(output): Identity()
(attention_normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffn_normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
(head): Head(
(normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(activation): ReLU()
(linear): Linear(in_features=64, out_features=1, bias=True)
)
)
)모델 훈련을 진행합니다. 간단한 예시를 보는 것이므로 15 에포크만 훈련하고, 검증 손실이 가장 낮은 모델을 'FT-Transformer_Best.pth'로 저장합니다.
criterion = nn.BCELoss()
optimizer = optim.AdamW(ft_t.parameters(), lr = 1e-4, weight_decay=1e-5)
history = {'train_loss' : [],
'val_loss': [],
'train_accuracy': [],
'val_accuracy': []}
EPOCHS = 15
max_loss = np.inf
for epoch in range(EPOCHS):
train_loss, train_acc = model_train(ft_t, train_loader, criterion, optimizer, device, None)
val_loss, val_acc = model_evaluate(ft_t, val_loader, criterion, device)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(ft_t.state_dict(), 'FT-Transformer_Best.pth')
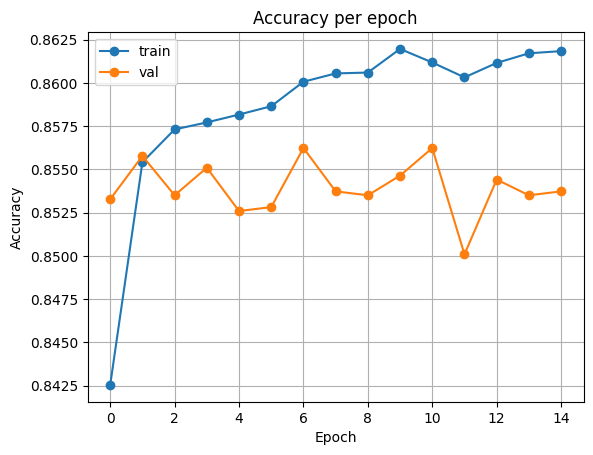
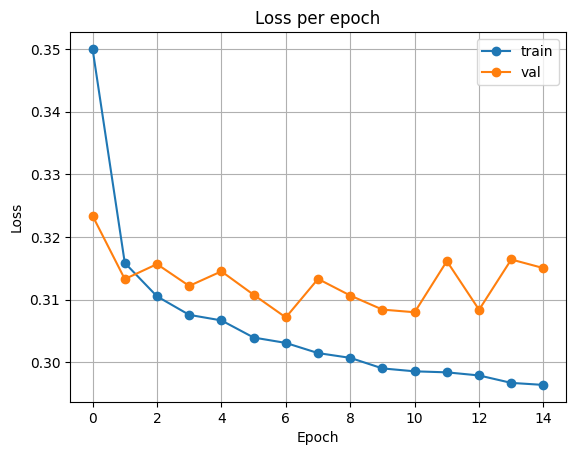
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')출력
100%|██████████| 1237/1237 [00:22<00:00, 54.66it/s]
[INFO] val_loss has been improved from inf to 0.32339. Save model.
epoch 01, loss: 0.35004, accuracy: 0.84255, val_loss: 0.32339, val_accuracy: 0.85328
100%|██████████| 1237/1237 [00:21<00:00, 57.09it/s]
[INFO] val_loss has been improved from 0.32339 to 0.31328. Save model.
epoch 02, loss: 0.31587, accuracy: 0.85541, val_loss: 0.31328, val_accuracy: 0.85578
100%|██████████| 1237/1237 [00:22<00:00, 56.18it/s]
epoch 03, loss: 0.31053, accuracy: 0.85731, val_loss: 0.31567, val_accuracy: 0.85350
100%|██████████| 1237/1237 [00:20<00:00, 61.07it/s]
[INFO] val_loss has been improved from 0.31328 to 0.31219. Save model.
epoch 04, loss: 0.30757, accuracy: 0.85771, val_loss: 0.31219, val_accuracy: 0.85510
100%|██████████| 1237/1237 [00:20<00:00, 59.36it/s]
epoch 05, loss: 0.30668, accuracy: 0.85817, val_loss: 0.31452, val_accuracy: 0.85259
100%|██████████| 1237/1237 [00:21<00:00, 57.74it/s]
[INFO] val_loss has been improved from 0.31219 to 0.31078. Save model.
epoch 06, loss: 0.30395, accuracy: 0.85865, val_loss: 0.31078, val_accuracy: 0.85282
100%|██████████| 1237/1237 [00:20<00:00, 61.05it/s]
[INFO] val_loss has been improved from 0.31078 to 0.30716. Save model.
epoch 07, loss: 0.30309, accuracy: 0.86006, val_loss: 0.30716, val_accuracy: 0.85623
100%|██████████| 1237/1237 [00:21<00:00, 56.26it/s]
epoch 08, loss: 0.30146, accuracy: 0.86054, val_loss: 0.31331, val_accuracy: 0.85373
100%|██████████| 1237/1237 [00:20<00:00, 60.62it/s]
epoch 09, loss: 0.30070, accuracy: 0.86060, val_loss: 0.31066, val_accuracy: 0.85350
100%|██████████| 1237/1237 [00:21<00:00, 58.79it/s]
epoch 10, loss: 0.29902, accuracy: 0.86196, val_loss: 0.30841, val_accuracy: 0.85464
100%|██████████| 1237/1237 [00:21<00:00, 58.50it/s]
epoch 11, loss: 0.29855, accuracy: 0.86118, val_loss: 0.30799, val_accuracy: 0.85623
100%|██████████| 1237/1237 [00:20<00:00, 60.87it/s]
epoch 12, loss: 0.29839, accuracy: 0.86032, val_loss: 0.31615, val_accuracy: 0.85009
100%|██████████| 1237/1237 [00:22<00:00, 54.48it/s]
epoch 13, loss: 0.29789, accuracy: 0.86115, val_loss: 0.30838, val_accuracy: 0.85441
100%|██████████| 1237/1237 [00:20<00:00, 59.77it/s]
epoch 14, loss: 0.29670, accuracy: 0.86171, val_loss: 0.31641, val_accuracy: 0.85350
100%|██████████| 1237/1237 [00:21<00:00, 56.64it/s]
epoch 15, loss: 0.29638, accuracy: 0.86183, val_loss: 0.31503, val_accuracy: 0.85373
plot_acc(history)출력
plot_loss(history)출력
검증 손실이 가장 적었던 모델을 불러와 테스트 데이터셋에서 평가를 진행합니다.
# test evaluate
ft_t.load_state_dict(torch.load('FT-Transformer_Best.pth'))
test_loss, test_acc = model_evaluate(ft_t, test_loader, criterion, device)
print('Test loss:', test_loss, '\nTest acc:', test_acc)출력
Test loss: 0.30666763982606887
Test acc: 0.8550665301944729
Tuning
Optuna 라이브러리를 사용하여 하이퍼파라미터 튜닝을 수행합니다. Optuna 사용 방법에 대해서는 Optuna 튜토리얼을 참고해 주세요.
데이터를 준비한 뒤, optuna objective 함수를 정의합니다. 탐색할 하이퍼파라미터의 범위는 해당 논문을 참고하였습니다.
X, y, cardinalities, train_loader, val_loader, test_loader = ready_data()
# optuna objective
# hyperparameter space from Revisiting Deep Learning Models for Tabular Data
# suggest_uniform, suggest_loguniform -> suggest_float, suggest_float(log=True)
def objective(trial, train_loader, val_loader):
d_token = trial.suggest_categorical('d_token', [64, 128, 256, 512])
n_blocks = trial.suggest_int('n_blocks', 1, 4, log=True)
attention_dropout = trial.suggest_float('attention_dropout', 0, 0.5)
ffn_d_hidden = trial.suggest_int('ffn_d_hidden', 64, 1028)
ffn_dropout = trial.suggest_float('ffn_dropout', 0, 0.5)
residual_dropout = trial.suggest_float('residual_dropout', 0, 0.2)
lr = trial.suggest_float('lr', 1e-5, 1e-2, log=True)
weight_decay = trial.suggest_float('weigth_decay', 1e-6, 1e-3, log=True)
model = rtdl.FTTransformer.make_baseline(n_num_features=X['train']['num'].shape[1],
cat_cardinalities=cardinalities,
d_token=d_token,
n_blocks=n_blocks,
attention_dropout=attention_dropout,
ffn_d_hidden=ffn_d_hidden,
ffn_dropout=ffn_dropout,
residual_dropout=residual_dropout,
d_out=1).to(device)
criterion = nn.BCELoss()
optimizer = optim.AdamW(model.parameters(), lr=lr, weight_decay=weight_decay)
EPOCHS = 10
min_loss = np.inf
for epoch in range(EPOCHS):
val_loss, val_acc = model_tune(model, train_loader, val_loader, criterion, optimizer, device)
if val_loss < min_loss:
min_loss = val_loss
# minimize minimun loss
return min_loss10 에포크 동안 모델을 훈련한 뒤, 10 에포크 중 가장 작았던 검증 손실(min_loss)을 리턴합니다. 에포크 수, 리턴 값 종류는 임의로 설정한 것이니 다른 방법으로 수정할 수 있습니다.
n_trials=15를 전달하여 15회 탐색을 수행합니다. 최적의 방법은 아닐 수 있습니다.
study = optuna.create_study(study_name='FT-Transformer', direction='minimize', sampler=TPESampler(seed=21))
study.optimize(lambda trial: objective(trial, train_loader, val_loader), n_trials=15)
print()
print("Best Score:", study.best_value)
print("Best trial:", study.best_trial.params)출력
[I 2023-09-03 15:10:26,769] A new study created in memory with name: FT-Transformer
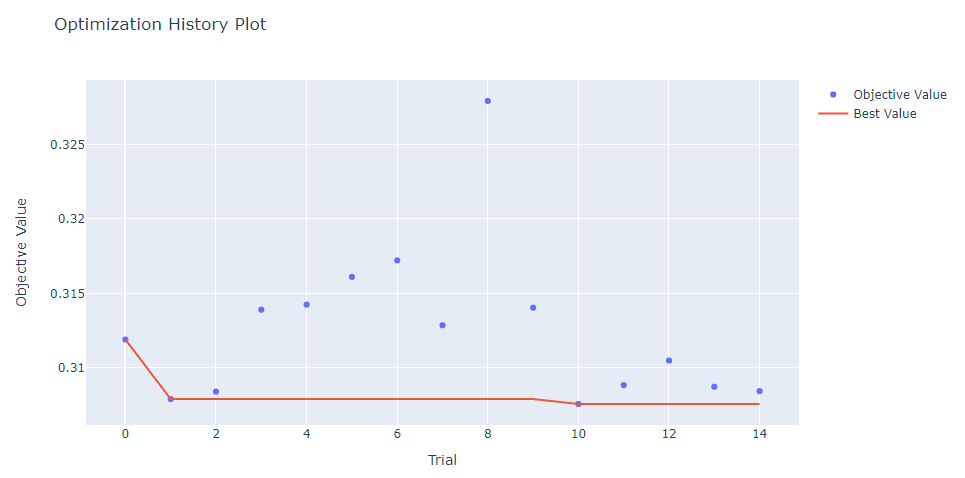
[I 2023-09-03 15:12:01,746] Trial 0 finished with value: 0.31191023896779657 and parameters: {'d_token': 256, 'n_blocks': 1, 'attention_dropout': 0.0253866283476884, 'ffn_d_hidden': 355, 'ffn_dropout': 0.33195514731235, 'residual_dropout': 0.06162287864737577, 'lr': 0.0005633442017222582, 'weigth_decay': 1.6170105887878455e-06}. Best is trial 0 with value: 0.31191023896779657.
[I 2023-09-03 15:15:21,720] Trial 1 finished with value: 0.30791561366537684 and parameters: {'d_token': 64, 'n_blocks': 3, 'attention_dropout': 0.37947191775605715, 'ffn_d_hidden': 1000, 'ffn_dropout': 0.3796512763927764, 'residual_dropout': 0.07685000641802589, 'lr': 0.00016832746705566732, 'weigth_decay': 0.00013806426449912442}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:17:49,153] Trial 2 finished with value: 0.30841183575638 and parameters: {'d_token': 256, 'n_blocks': 2, 'attention_dropout': 0.08391788261075367, 'ffn_d_hidden': 352, 'ffn_dropout': 0.14197152251531692, 'residual_dropout': 0.0654425153235462, 'lr': 0.00024011594547390913, 'weigth_decay': 4.2964036649104274e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:19:22,480] Trial 3 finished with value: 0.31391026360322605 and parameters: {'d_token': 512, 'n_blocks': 1, 'attention_dropout': 0.3074123555742173, 'ffn_d_hidden': 693, 'ffn_dropout': 0.19340821706714278, 'residual_dropout': 0.08207083571456375, 'lr': 0.002694465631697865, 'weigth_decay': 6.325688416776969e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:22:45,038] Trial 4 finished with value: 0.31425553684998253 and parameters: {'d_token': 64, 'n_blocks': 3, 'attention_dropout': 0.4438277186036015, 'ffn_d_hidden': 738, 'ffn_dropout': 0.2271951538053748, 'residual_dropout': 0.061183032957771104, 'lr': 0.0028857135238802138, 'weigth_decay': 2.6241820849180914e-06}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:24:18,000] Trial 5 finished with value: 0.31611508817104345 and parameters: {'d_token': 512, 'n_blocks': 1, 'attention_dropout': 0.4023048260098239, 'ffn_d_hidden': 833, 'ffn_dropout': 0.3328468238870974, 'residual_dropout': 0.048822499344554696, 'lr': 0.0028712349861834516, 'weigth_decay': 2.52815426958096e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:25:50,521] Trial 6 finished with value: 0.3172221409395893 and parameters: {'d_token': 256, 'n_blocks': 1, 'attention_dropout': 0.08962323656258431, 'ffn_d_hidden': 884, 'ffn_dropout': 0.1825561234209927, 'residual_dropout': 0.07620702788217536, 'lr': 1.329298365664037e-05, 'weigth_decay': 7.988941311419133e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:27:23,237] Trial 7 finished with value: 0.31286784431628467 and parameters: {'d_token': 128, 'n_blocks': 1, 'attention_dropout': 0.18676054932517328, 'ffn_d_hidden': 432, 'ffn_dropout': 0.2853225110077615, 'residual_dropout': 0.10222734330823656, 'lr': 0.0003865733636663784, 'weigth_decay': 3.712001106743147e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:28:52,438] Trial 8 finished with value: 0.3279178399894322 and parameters: {'d_token': 64, 'n_blocks': 1, 'attention_dropout': 0.33769619545643537, 'ffn_d_hidden': 955, 'ffn_dropout': 0.03498470984813046, 'residual_dropout': 0.1563538885204995, 'lr': 1.2744094026775414e-05, 'weigth_decay': 3.366967992935658e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:30:24,901] Trial 9 finished with value: 0.31404495586364023 and parameters: {'d_token': 256, 'n_blocks': 1, 'attention_dropout': 0.3024222694512644, 'ffn_d_hidden': 751, 'ffn_dropout': 0.07538727408581358, 'residual_dropout': 0.12295271490015723, 'lr': 2.834999352564659e-05, 'weigth_decay': 2.4277091644083078e-05}. Best is trial 1 with value: 0.30791561366537684.
[I 2023-09-03 15:34:40,764] Trial 10 finished with value: 0.30758440882320076 and parameters: {'d_token': 64, 'n_blocks': 4, 'attention_dropout': 0.47110354044768354, 'ffn_d_hidden': 111, 'ffn_dropout': 0.4536617774026742, 'residual_dropout': 0.0112958582072534, 'lr': 7.878491237694348e-05, 'weigth_decay': 0.000969774237597253}. Best is trial 10 with value: 0.30758440882320076.
[I 2023-09-03 15:38:57,871] Trial 11 finished with value: 0.3088506360939137 and parameters: {'d_token': 64, 'n_blocks': 4, 'attention_dropout': 0.4924117619922685, 'ffn_d_hidden': 113, 'ffn_dropout': 0.46271281999602054, 'residual_dropout': 0.0038342215759173126, 'lr': 9.222237764391702e-05, 'weigth_decay': 0.0009716793664825517}. Best is trial 10 with value: 0.30758440882320076.
[I 2023-09-03 15:43:17,137] Trial 12 finished with value: 0.31050074859789223 and parameters: {'d_token': 64, 'n_blocks': 4, 'attention_dropout': 0.39447850770900916, 'ffn_d_hidden': 69, 'ffn_dropout': 0.46631079808403886, 'residual_dropout': 0.0038004038876968092, 'lr': 9.420009445103097e-05, 'weigth_decay': 0.000909151615240169}. Best is trial 10 with value: 0.30758440882320076.
[I 2023-09-03 15:45:43,217] Trial 13 finished with value: 0.30874233029179404 and parameters: {'d_token': 64, 'n_blocks': 2, 'attention_dropout': 0.49938064452676934, 'ffn_d_hidden': 536, 'ffn_dropout': 0.39328069685591205, 'residual_dropout': 0.03379640360217914, 'lr': 6.358119441124893e-05, 'weigth_decay': 0.00028288917730312025}. Best is trial 10 with value: 0.30758440882320076.
[I 2023-09-03 15:49:10,551] Trial 14 finished with value: 0.30845081944482994 and parameters: {'d_token': 128, 'n_blocks': 3, 'attention_dropout': 0.38709273701369884, 'ffn_d_hidden': 241, 'ffn_dropout': 0.41230356354491476, 'residual_dropout': 0.19836499463176543, 'lr': 0.00021656872719706034, 'weigth_decay': 0.00029534981882161596}. Best is trial 10 with value: 0.30758440882320076.
Best Score: 0.30758440882320076
Best trial: {'d_token': 64, 'n_blocks': 4, 'attention_dropout': 0.47110354044768354, 'ffn_d_hidden': 111, 'ffn_dropout': 0.4536617774026742, 'residual_dropout': 0.0112958582072534, 'lr': 7.878491237694348e-05, 'weigth_decay': 0.000969774237597253}optuna.visualization.plot_optimization_history(study)출력
optuna.visualization.plot_param_importances(study)출력
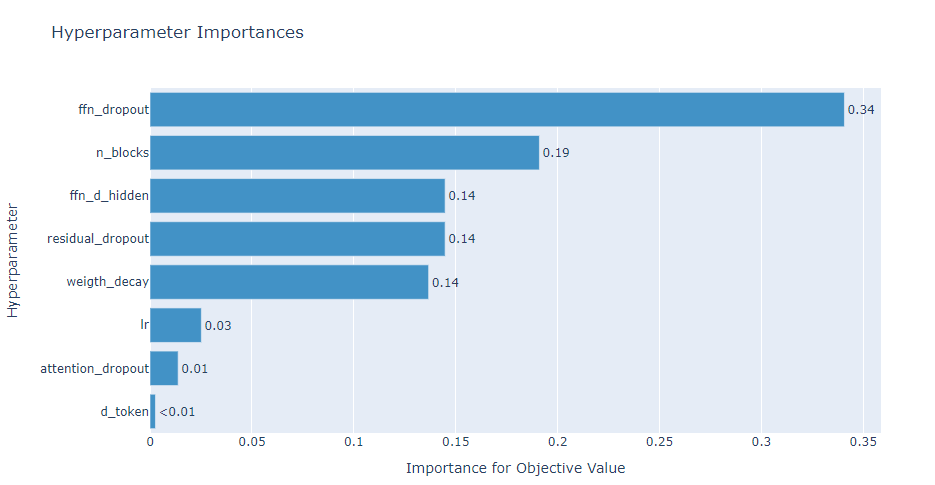
study.best_trial.params출력
{'d_token': 64,
'n_blocks': 4,
'attention_dropout': 0.47110354044768354,
'ffn_d_hidden': 111,
'ffn_dropout': 0.4536617774026742,
'residual_dropout': 0.0112958582072534,
'lr': 7.878491237694348e-05,
'weigth_decay': 0.000969774237597253}최적의 하이퍼파라미터 조합으로 모델을 다시 훈련합니다. 검증 손실이 가장 작은 모델을 'FT-Transformer_Best_tuned.pth'로 저장합니다.
X, y, cardinalities, train_loader, val_loader, test_loader = ready_data()
ft_t = rtdl.FTTransformer.make_baseline(n_num_features=X['train']['num'].shape[1],
cat_cardinalities=cardinalities,
d_token=study.best_trial.params['d_token'],
n_blocks=study.best_trial.params['n_blocks'],
attention_dropout=study.best_trial.params['attention_dropout'],
ffn_d_hidden=study.best_trial.params['ffn_d_hidden'],
ffn_dropout=study.best_trial.params['ffn_dropout'],
residual_dropout=study.best_trial.params['residual_dropout'],
d_out=1).to(device)
criterion = nn.BCELoss()
optimizer = optim.AdamW(ft_t.parameters(),
lr = study.best_trial.params['lr'],
weight_decay=study.best_trial.params['weigth_decay'])
history = {'train_loss' : [],
'val_loss': [],
'train_accuracy': [],
'val_accuracy': []}
EPOCHS = 15
max_loss = np.inf
for epoch in range(EPOCHS):
train_loss, train_acc = model_train(ft_t, train_loader, criterion, optimizer, device, None)
val_loss, val_acc = model_evaluate(ft_t, val_loader, criterion, device)
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(ft_t.state_dict(), 'FT-Transformer_Best_tuned.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')출력
100%|██████████| 1237/1237 [00:26<00:00, 46.50it/s]
[INFO] val_loss has been improved from inf to 0.32704. Save model.
epoch 01, loss: 0.37064, accuracy: 0.83347, val_loss: 0.32704, val_accuracy: 0.84964
100%|██████████| 1237/1237 [00:26<00:00, 46.84it/s]
[INFO] val_loss has been improved from 0.32704 to 0.32234. Save model.
epoch 02, loss: 0.32431, accuracy: 0.85213, val_loss: 0.32234, val_accuracy: 0.84964
100%|██████████| 1237/1237 [00:27<00:00, 44.98it/s]
[INFO] val_loss has been improved from 0.32234 to 0.31594. Save model.
epoch 03, loss: 0.31692, accuracy: 0.85309, val_loss: 0.31594, val_accuracy: 0.85214
100%|██████████| 1237/1237 [00:27<00:00, 44.25it/s]
epoch 04, loss: 0.31211, accuracy: 0.85544, val_loss: 0.31876, val_accuracy: 0.85191
100%|██████████| 1237/1237 [00:27<00:00, 44.45it/s]
epoch 05, loss: 0.30868, accuracy: 0.85582, val_loss: 0.32563, val_accuracy: 0.84759
100%|██████████| 1237/1237 [00:27<00:00, 45.37it/s]
epoch 06, loss: 0.30714, accuracy: 0.85784, val_loss: 0.31656, val_accuracy: 0.85168
100%|██████████| 1237/1237 [00:27<00:00, 44.86it/s]
epoch 07, loss: 0.30630, accuracy: 0.85918, val_loss: 0.31977, val_accuracy: 0.84827
100%|██████████| 1237/1237 [00:26<00:00, 46.34it/s]
[INFO] val_loss has been improved from 0.31594 to 0.31213. Save model.
epoch 08, loss: 0.30602, accuracy: 0.85738, val_loss: 0.31213, val_accuracy: 0.85077
100%|██████████| 1237/1237 [00:27<00:00, 45.03it/s]
[INFO] val_loss has been improved from 0.31213 to 0.31095. Save model.
epoch 09, loss: 0.30443, accuracy: 0.85860, val_loss: 0.31095, val_accuracy: 0.85168
100%|██████████| 1237/1237 [00:27<00:00, 44.70it/s]
[INFO] val_loss has been improved from 0.31095 to 0.31038. Save model.
epoch 10, loss: 0.30350, accuracy: 0.85888, val_loss: 0.31038, val_accuracy: 0.85350
100%|██████████| 1237/1237 [00:27<00:00, 44.66it/s]
[INFO] val_loss has been improved from 0.31038 to 0.30803. Save model.
epoch 11, loss: 0.30243, accuracy: 0.85898, val_loss: 0.30803, val_accuracy: 0.85464
100%|██████████| 1237/1237 [00:26<00:00, 46.09it/s]
epoch 12, loss: 0.30255, accuracy: 0.85948, val_loss: 0.30838, val_accuracy: 0.85373
100%|██████████| 1237/1237 [00:26<00:00, 47.42it/s]
epoch 13, loss: 0.30143, accuracy: 0.86080, val_loss: 0.31192, val_accuracy: 0.85464
100%|██████████| 1237/1237 [00:27<00:00, 44.56it/s]
[INFO] val_loss has been improved from 0.30803 to 0.30650. Save model.
epoch 14, loss: 0.30129, accuracy: 0.85958, val_loss: 0.30650, val_accuracy: 0.85373
100%|██████████| 1237/1237 [00:27<00:00, 44.42it/s]
epoch 15, loss: 0.30042, accuracy: 0.85961, val_loss: 0.31261, val_accuracy: 0.85487
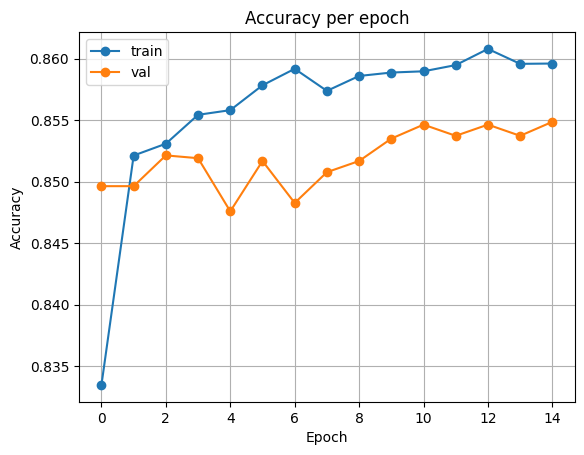
plot_acc(history)출력
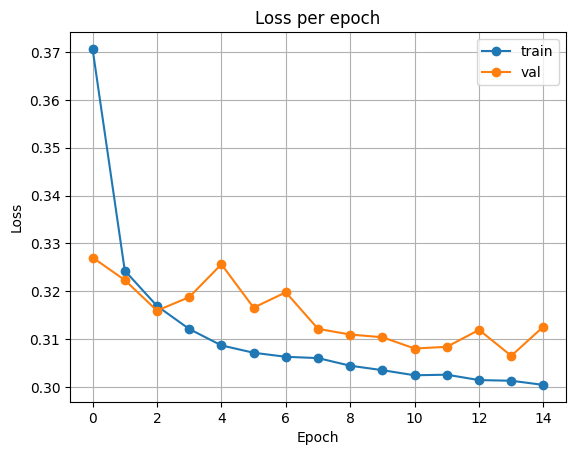
plot_loss(history)출력
테스트 데이터셋에서 최종 평가를 진행합니다.
# test evaluate
ft_t.load_state_dict(torch.load('FT-Transformer_Best_tuned.pth'))
test_loss, test_acc = model_evaluate(ft_t, test_loader, criterion, device)
print('Test loss:', test_loss, '\nTest acc:', test_acc)출력
Test loss: 0.3057573468774222
Test acc: 0.8595701125895598
이상으로 FT-Transformer 아키텍처의 간단한 사용 방법에 대해 알아보았습니다. 위의 방법이 모델 성능을 위한 최적의 방법이 아닐 수 있습니다. 하이퍼파라미터 탐색 범위 수정, 모델 훈련 시 scheduler 사용 등 추가적인 방법으로 더 좋은 성능을 달성할 수도 있습니다.
해당 아키텍처에 대해 더 많은 정보를 확인하시려면 rtdl의 github를 참고해 주세요.
감사합니다.
